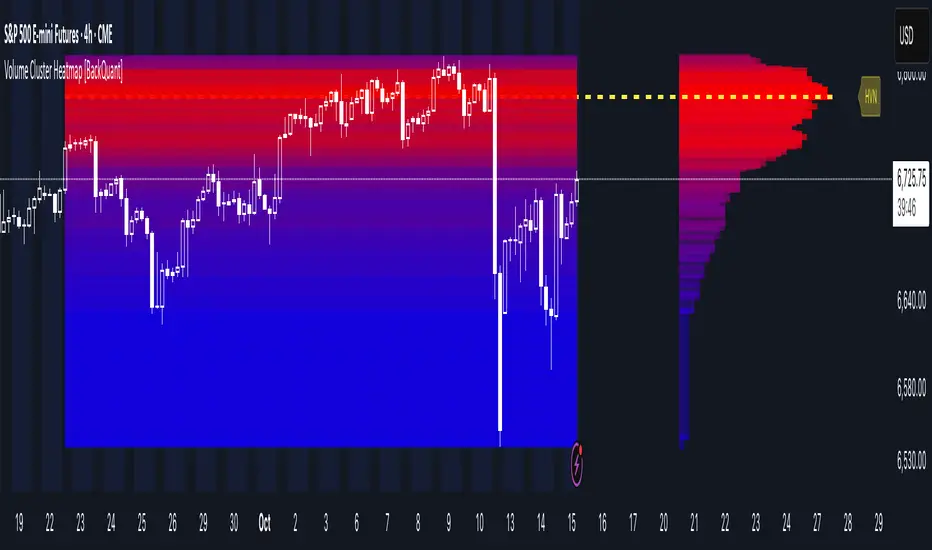
Volume Cluster Heatmap [BackQuant]Volume Cluster Heatmap
A visualization tool that maps traded volume across price levels over a chosen lookback period. It highlights where the market builds balance through heavy participation and where it moves efficiently through low-volume zones. By combining a heatmap, volume profile, and high/low volume node detection, this indicator reveals structural areas of support, resistance, and liquidity that drive price behavior.
What Are Volume Clusters?
A volume cluster is a horizontal aggregation of traded volume at specific price levels, showing where market participants concentrated their buying and selling.
High Volume Nodes (HVN) : Price levels with significant trading activity; often act as support or resistance.
Low Volume Nodes (LVN) : Price levels with little trading activity; price moves quickly through these areas, reflecting low liquidity.
Volume clusters help identify key structural zones, reveal potential reversals, and gauge market efficiency by highlighting where the market is balanced versus areas of thin liquidity.
By creating heatmaps, profiles, and highlighting high and low volume nodes (HVNs and LVNs), it allows traders to see where the market builds balance and where it moves efficiently through thin liquidity zones.
Example: Bitcoin breaking away from the high-volume zone near 118k and moving cleanly through the low-volume pocket around 113k–115k, illustrating how markets seek efficiency:
Core Features
Visual Analysis Components:
Heatmap Display : Displays volume intensity as colored boxes, lines, or a combination for a dynamic view of market participation.
Volume Profile Overlay : Shows cumulative volume per price level along the right-hand side of the chart.
HVN & LVN Labels : Marks high and low volume nodes with color-coded lines and labels.
Customizable Colors & Transparency : Adjust high and low volume colors and minimum transparency for clear differentiation.
Session Reset & Timeframe Control : Dynamically resets clusters at the start of new sessions or chosen timeframes (intraday, daily, weekly).
Alerts
HVN / LVN Alerts : Notify when price reaches a significant high or low volume node.
High Volume Zone Alerts : Trigger when price enters the top X% of cumulative volume, signaling key areas of market interest.
How It Works
Each bar’s volume is distributed proportionally across the horizontal price levels it touches. Over the lookback period, this builds a cumulative volume profile, identifying price levels with the most and least trading activity. The highest cumulative volume levels become HVNs, while the lowest are LVNs. A side volume profile shows aggregated volume per level, and a heatmap overlay visually reinforces market structure.
Applications for Traders
Identify strong support and resistance at HVNs.
Detect areas of low liquidity where price may move quickly (LVNs).
Determine market balance zones where price may consolidate.
Filter noise: because volume clusters aggregate activity into levels, minor fluctuations and irrelevant micro-moves are removed, simplifying analysis and improving strategy development.
Combine with other indicators such as VWAP, Supertrend, or CVD for higher-probability entries and exits.
Use volume clusters to anticipate price reactions to breaking points in thin liquidity zones.
Advanced Display Options
Heatmap Styles : Boxes, lines, or both. Boxes provide a traditional heatmap, lines are better for high granularity data.
Line Mode Example : Simplified line visualization for easier reading at high level counts:
Profile Width & Offset : Adjust spacing and placement of the volume profile for clarity alongside price.
Transparency Control : Lower transparency for more opaque visualization of high-volume zones.
Best Practices for Usage
Reduce the number of levels when using line mode to avoid clutter.
Use HVN and LVN markers in conjunction with volume profiles to plan entries and exits.
Apply session resets to monitor intraday vs. multi-day volume accumulation.
Combine with other technical indicators to confirm high-probability trading signals.
Watch price interactions with LVNs for potential rapid movements and with HVNs for possible support/resistance or reversals.
Technical Notes
Each bar contributes volume proportionally to the price levels it spans, creating a dynamic and accurate representation of traded interest.
Volume profiles are scaled and offset for visual clarity alongside live price.
Alerts are fully integrated for HVN/LVN interaction and high-volume zone entries.
Optimized to handle large lookback windows and numerous price levels efficiently without performance degradation.
This indicator is ideal for understanding market structure, detecting key liquidity areas, and filtering out noise to model price more accurately in high-frequency or algorithmic strategies.
Cluster
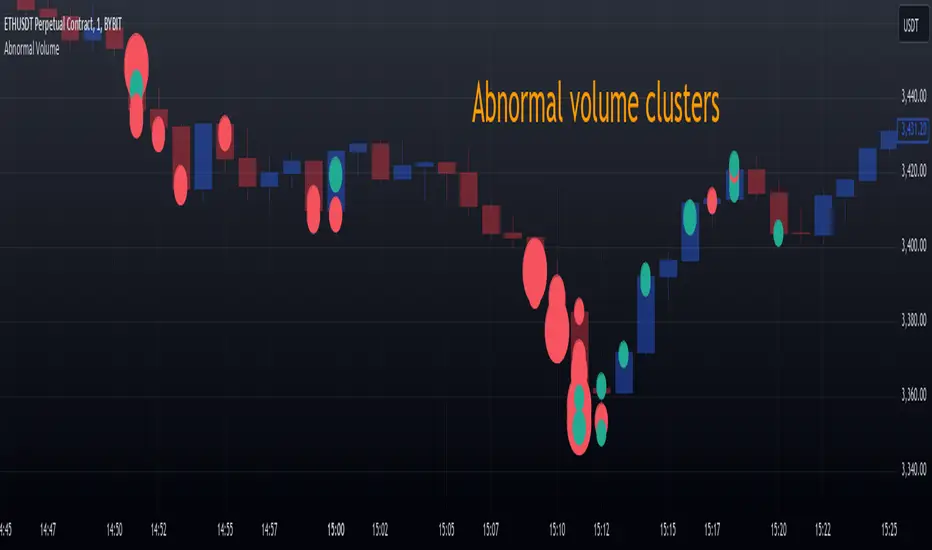
Abnormal volume [VG]🪙 INTRODUCTION
This technical indicator helps identify and highlight large volume clusters on the chart.
Abnormal volume refers to unusually large accumulations of volume over short time intervals. Such clusters appear when the amount of assets bought or sold significantly exceeds typical volumes for a specific asset over a given period. These patterns can indicate significant events or intentions of market participants.
Reasons for abnormal volume clusters:
Institutional investments :
Large investment funds and banks may buy or sell significant volumes of assets to rebalance their portfolios.
Impact of news and events :
Important news (e.g., mergers, bankruptcies, management changes) can trigger large-scale buying or selling of assets.
Market manipulation :
Big players may execute large trades to artificially create demand or supply for an asset, affecting its price in the short term.
Insider trading :
Abnormal volumes may signal that someone with insider information has started buying or selling assets in anticipation of future events that could impact the price.
What do abnormal volume clusters mean for traders?
A signal of potential price changes :
High trading volumes are often accompanied by sharp price movements. An increase in volume during price growth might indicate rising interest in the asset, while an increase during a decline could signal a sell-off.
Potential entry or exit points :
For short-term traders, abnormal trades can serve as signals to enter or exit positions. For example, a large volume growth accompanied by a breakout of a key level might be seen as a buy signal.
Caution due to potential manipulation :
Abnormal trades don’t always lead to expected outcomes. Sometimes, they are part of a price manipulation strategy, so it’s essential to consider the broader context and confirm with other signals.
🪙 USAGE
This indicator doesn’t provide trading signals, entry points, or actionable recommendations.
Instead, it simplifies tracking market dynamics and highlights unusual activity worth considering during analysis.
After adding the indicator to the chart, you only need to configure two parameters: the threshold value that determines what constitutes a significant volume cluster and the period over which volumes are aggregated for comparison against the threshold.
It’s recommended to use the shortest available period, as this helps more precisely identify the prevailing volume direction (since this depends on price changes, not trade direction).
The threshold value can be fine-tuned by switching the chart’s timeframe to match the selected period, observing of the significant volume increase on the classic volume histogram, and noting the corresponding market reactions. This allows for selecting a threshold that highlights early signs of impactful trading events on higher timeframes.
Let’s look at an example in the screenshot:
Once the parameters are set, you can also enable an alert to trigger whenever a new volume cluster appears, simplifying event tracking.
Note: in the current version of the indicator, the alert will be triggered only once per bar on the chart at the first detected cluster of abnormal volume.
🪙 IMPLEMENTATION
Technically, the script retrieves volume data from a lower timeframe and estimates whether the volume was primarily generated by buyers or sellers based on price movements.
The lower resolution timeframe is determined as follows:
if the settings base period is less than 1 minute, then the data timeframe will be equal to 1 second
if the settings base period is equals 1 minute or more, then the data timeframe will be equal to 1 minute
The algorithm checks whether the price increased or decreased at each point. If the price rose, the volume is presumed to be driven by buyers and marked as buy volume; otherwise, it’s marked as sell volume.
The total volume at each point is then checked against the user-defined threshold. If the volume exceeds the threshold, a corresponding circle is drawn on the chart, and an alert is generated if created.
The size of the visual representation is proportional to the most recent maximum volume and follows the rules below:
Percentage of max volume -> Volume cluster size
less than 25% -> Tiny
25% to 50% -> Small
50% to 75% -> Normal
75% to 100% -> Large
100% or more -> Huge
🪙 SETTINGS
The indicator is designed to be as simple and minimalist as possible, making configuration effortless. There are only two core parameters, with additional options to customize the colors of volume clusters based on their type.
Trade volume threshold
Defines the volume level above which a cluster is considered significant and displayed on the chart as a circle. The size of the circle depends on the proportion of the current volume relative to the most recent maximum over the chosen period.
Trades base period
Specifies the period for aggregating trade volumes to determine whether they qualify as abnormal. The significance level is set using the Trade volume threshold parameter.
Buy/Sell trades
Allows you to set the colors for abnormal volume circles based on the price direction during cluster formation.
🪙 CONCLUSION
Abnormal volume clusters are always a critical indicator requiring attention and analysis, but they are not a guaranteed predictor of trend changes.
Correlation Clusters [LuxAlgo]The Correlation Clusters is a machine learning tool that allows traders to group sets of tickers with a similar correlation coefficient to a user-set reference ticker.
The tool calculates the correlation coefficients between 10 user-set tickers and a user-set reference ticker, with the possibility of forming up to 10 clusters.
🔶 USAGE
Applying clustering methods to correlation analysis allows traders to quickly identify which set of tickers are correlated with a reference ticker, rather than having to look at them one by one or using a more tedious approach such as correlation matrices.
Tickers belonging to a cluster may also be more likely to have a higher mutual correlation. The image above shows the detailed parts of the Correlation Clusters tool.
The correlation coefficient between two assets allows traders to see how these assets behave in relation to each other. It can take values between +1.0 and -1.0 with the following meaning
Value near +1.0: Both assets behave in a similar way, moving up or down at the same time
Value close to 0.0: No correlation, both assets behave independently
Value near -1.0: Both assets have opposite behavior when one moves up the other moves down, and vice versa
There is a wide range of trading strategies that make use of correlation coefficients between assets, some examples are:
Pair Trading: Traders may wish to take advantage of divergences in the price movements of highly positively correlated assets; even highly positively correlated assets do not always move in the same direction; when assets with a correlation close to +1.0 diverge in their behavior, traders may see this as an opportunity to buy one and sell the other in the expectation that the assets will return to the likely same price behavior.
Sector rotation: Traders may want to favor some sectors that are expected to perform in the next cycle, tracking the correlation between different sectors and between the sector and the overall market.
Diversification: Traders can aim to have a diversified portfolio of uncorrelated assets. From a risk management perspective, it is useful to know the correlation between the assets in your portfolio, if you hold equal positions in positively correlated assets, your risk is tilted in the same direction, so if the assets move against you, your risk is doubled. You can avoid this increased risk by choosing uncorrelated assets so that they move independently.
Hedging: Traders may want to hedge positions with correlated assets, from a hedging perspective, if you are long an asset, you can hedge going long a negatively correlated asset or going short a positively correlated asset.
Grouping different assets with similar behavior can be very helpful to traders to avoid over-exposure to those assets, traders may have multiple long positions on different assets as a way of minimizing overall risk when in reality if those assets are part of the same cluster traders are maximizing their risk by taking positions on assets with the same behavior.
As a rule of thumb, a trader can minimize risk via diversification by taking positions on assets with no correlations, the proposed tool can effectively show a set of uncorrelated candidates from the reference ticker if one or more clusters centroids are located near 0.
🔶 DETAILS
K-means clustering is a popular machine-learning algorithm that finds observations in a data set that are similar to each other and places them in a group.
The process starts by randomly assigning each data point to an initial group and calculating the centroid for each. A centroid is the center of the group. K-means clustering forms the groups in such a way that the variances between the data points and the centroid of the cluster are minimized.
It's an unsupervised method because it starts without labels and then forms and labels groups itself.
🔹 Execution Window
In the image above we can see how different execution windows provide different correlation coefficients, informing traders of the different behavior of the same assets over different time periods.
Users can filter the data used to calculate correlations by number of bars, by time, or not at all, using all available data. For example, if the chart timeframe is 15m, traders may want to know how different assets behave over the last 7 days (one week), or for an hourly chart set an execution window of one month, or one year for a daily chart. The default setting is to use data from the last 50 bars.
🔹 Clusters
On this graph, we can see different clusters for the same data. The clusters are identified by different colors and the dotted lines show the centroids of each cluster.
Traders can select up to 10 clusters, however, do note that selecting 10 clusters can lead to only 4 or 5 returned clusters, this is caused by the machine learning algorithm not detecting any more data points deviating from already detected clusters.
Traders can fine-tune the algorithm by changing the 'Cluster Threshold' and 'Max Iterations' settings, but if you are not familiar with them we advise you not to change these settings, the defaults can work fine for the application of this tool.
🔹 Correlations
Different correlations mean different behaviors respecting the same asset, as we can see in the chart above.
All correlations are found against the same asset, traders can use the chart ticker or manually set one of their choices from the settings panel. Then they can select the 10 tickers to be used to find the correlation coefficients, which can be useful to analyze how different types of assets behave against the same asset.
🔶 SETTINGS
Execution Window Mode: Choose how the tool collects data, filter data by number of bars, time, or no filtering at all, using all available data.
Execute on Last X Bars: Number of bars for data collection when the 'Bars' execution window mode is active.
Execute on Last: Time window for data collection when the `Time` execution window mode is active. These are full periods, so `Day` means the last 24 hours, `Week` means the last 7 days, and so on.
🔹 Clusters
Number of Clusters: Number of clusters to detect up to 10. Only clusters with data points are displayed.
Cluster Threshold: Number used to compare a new centroid within the same cluster. The lower the number, the more accurate the centroid will be.
Max Iterations: Maximum number of calculations to detect a cluster. A high value may lead to a timeout runtime error (loop takes too long).
🔹 Ticker of Reference
Use Chart Ticker as Reference: Enable/disable the use of the current chart ticker to get the correlation against all other tickers selected by the user.
Custom Ticker: Custom ticker to get the correlation against all the other tickers selected by the user.
🔹 Correlation Tickers
Select the 10 tickers for which you wish to obtain the correlation against the reference ticker.
🔹 Style
Text Size: Select the size of the text to be displayed.
Display Size: Select the size of the correlation chart to be displayed, up to 500 bars.
Box Height: Select the height of the boxes to be displayed. A high height will cause overlapping if the boxes are close together.
Clusters Colors: Choose a custom colour for each cluster.

Support & Resistance AI (K means/median) [ThinkLogicAI]█ OVERVIEW
K-means is a clustering algorithm commonly used in machine learning to group data points into distinct clusters based on their similarities. While K-means is not typically used directly for identifying support and resistance levels in financial markets, it can serve as a tool in a broader analysis approach.
Support and resistance levels are price levels in financial markets where the price tends to react or reverse. Support is a level where the price tends to stop falling and might start to rise, while resistance is a level where the price tends to stop rising and might start to fall. Traders and analysts often look for these levels as they can provide insights into potential price movements and trading opportunities.
█ BACKGROUND
The K-means algorithm has been around since the late 1950s, making it more than six decades old. The algorithm was introduced by Stuart Lloyd in his 1957 research paper "Least squares quantization in PCM" for telecommunications applications. However, it wasn't widely known or recognized until James MacQueen's 1967 paper "Some Methods for Classification and Analysis of Multivariate Observations," where he formalized the algorithm and referred to it as the "K-means" clustering method.
So, while K-means has been around for a considerable amount of time, it continues to be a widely used and influential algorithm in the fields of machine learning, data analysis, and pattern recognition due to its simplicity and effectiveness in clustering tasks.
█ COMPARE AND CONTRAST SUPPORT AND RESISTANCE METHODS
1) K-means Approach:
Cluster Formation: After applying the K-means algorithm to historical price change data and visualizing the resulting clusters, traders can identify distinct regions on the price chart where clusters are formed. Each cluster represents a group of similar price change patterns.
Cluster Analysis: Analyze the clusters to identify areas where clusters tend to form. These areas might correspond to regions of price behavior that repeat over time and could be indicative of support and resistance levels.
Potential Support and Resistance Levels: Based on the identified areas of cluster formation, traders can consider these regions as potential support and resistance levels. A cluster forming at a specific price level could suggest that this level has been historically significant, causing similar price behavior in the past.
Cluster Standard Deviation: In addition to looking at the means (centroids) of the clusters, traders can also calculate the standard deviation of price changes within each cluster. Standard deviation is a measure of the dispersion or volatility of data points around the mean. A higher standard deviation indicates greater price volatility within a cluster.
Low Standard Deviation: If a cluster has a low standard deviation, it suggests that prices within that cluster are relatively stable and less likely to exhibit sudden and large price movements. Traders might consider placing tighter stop-loss orders for trades within these clusters.
High Standard Deviation: Conversely, if a cluster has a high standard deviation, it indicates greater price volatility within that cluster. Traders might opt for wider stop-loss orders to allow for potential price fluctuations without getting stopped out prematurely.
Cluster Density: Each data point is assigned to a cluster so a cluster that is more dense will act more like gravity and
2) Traditional Approach:
Trendlines: Draw trendlines connecting significant highs or lows on a price chart to identify potential support and resistance levels.
Chart Patterns: Identify chart patterns like double tops, double bottoms, head and shoulders, and triangles that often indicate potential reversal points.
Moving Averages: Use moving averages to identify levels where the price might find support or resistance based on the average price over a specific period.
Psychological Levels: Identify round numbers or levels that traders often pay attention to, which can act as support and resistance.
Previous Highs and Lows: Identify significant previous price highs and lows that might act as support or resistance.
The key difference lies in the approach and the foundation of these methods. Traditional methods are based on well-established principles of technical analysis and market psychology, while the K-means approach involves clustering price behavior without necessarily incorporating market sentiment or specific price patterns.
It's important to note that while the K-means approach might provide an interesting way to analyze price data, it should be used cautiously and in conjunction with other traditional methods. Financial markets are influenced by a wide range of factors beyond just price behavior, and the effectiveness of any method for identifying support and resistance levels should be thoroughly tested and validated. Additionally, developments in trading strategies and analysis techniques could have occurred since my last update.
█ K MEANS ALGORITHM
The algorithm for K means is as follows:
Initialize cluster centers
assign data to clusters based on minimum distance
calculate cluster center by taking the average or median of the clusters
repeat steps 1-3 until cluster centers stop moving
█ LIMITATIONS OF K MEANS
There are 3 main limitations of this algorithm:
Sensitive to Initializations: K-means is sensitive to the initial placement of centroids. Different initializations can lead to different cluster assignments and final results.
Assumption of Equal Sizes and Variances: K-means assumes that clusters have roughly equal sizes and spherical shapes. This may not hold true for all types of data. It can struggle with identifying clusters with uneven densities, sizes, or shapes.
Impact of Outliers: K-means is sensitive to outliers, as a single outlier can significantly affect the position of cluster centroids. Outliers can lead to the creation of spurious clusters or distortion of the true cluster structure.
█ LIMITATIONS IN APPLICATION OF K MEANS IN TRADING
Trading data often exhibits characteristics that can pose challenges when applying indicators and analysis techniques. Here's how the limitations of outliers, varying scales, and unequal variance can impact the use of indicators in trading:
Outliers are data points that significantly deviate from the rest of the dataset. In trading, outliers can represent extreme price movements caused by rare events, news, or market anomalies. Outliers can have a significant impact on trading indicators and analyses:
Indicator Distortion: Outliers can skew the calculations of indicators, leading to misleading signals. For instance, a single extreme price spike could cause indicators like moving averages or RSI (Relative Strength Index) to give false signals.
Risk Management: Outliers can lead to overly aggressive trading decisions if not properly accounted for. Ignoring outliers might result in unexpected losses or missed opportunities to adjust trading strategies.
Different Scales: Trading data often includes multiple indicators with varying units and scales. For example, prices are typically in dollars, volume in units traded, and oscillators have their own scale. Mixing indicators with different scales can complicate analysis:
Normalization: Indicators on different scales need to be normalized or standardized to ensure they contribute equally to the analysis. Failure to do so can lead to one indicator dominating the analysis due to its larger magnitude.
Comparability: Without normalization, it's challenging to directly compare the significance of indicators. Some indicators might have a larger numerical range and could overshadow others.
Unequal Variance: Unequal variance in trading data refers to the fact that some indicators might exhibit higher volatility than others. This can impact the interpretation of signals and the performance of trading strategies:
Volatility Adjustment: When combining indicators with varying volatility, it's essential to adjust for their relative volatilities. Failure to do so might lead to overemphasizing or underestimating the importance of certain indicators in the trading strategy.
Risk Assessment: Unequal variance can impact risk assessment. Indicators with higher volatility might lead to riskier trading decisions if not properly taken into account.
█ APPLICATION OF THIS INDICATOR
This indicator can be used in 2 ways:
1) Make a directional trade:
If a trader thinks price will go higher or lower and price is within a cluster zone, The trader can take a position and place a stop on the 1 sd band around the cluster. As one can see below, the trader can go long the green arrow and place a stop on the one standard deviation mark for that cluster below it at the red arrow. using this we can calculate a risk to reward ratio.
Calculating risk to reward: targeting a risk reward ratio of 2:1, the trader could clearly make that given that the next resistance area above that in the orange cluster exceeds this risk reward ratio.
2) Take a reversal Trade:
We can use cluster centers (support and resistance levels) to go in the opposite direction that price is currently moving in hopes of price forming a pivot and reversing off this level.
Similar to the directional trade, we can use the standard deviation of the cluster to place a stop just in case we are wrong.
In this example below we can see that shorting on the red arrow and placing a stop at the one standard deviation above this cluster would give us a profitable trade with minimal risk.
Using the cluster density table in the upper right informs the trader just how dense the cluster is. Higher density clusters will give a higher likelihood of a pivot forming at these levels and price being rejected and switching direction with a larger move.
█ FEATURES & SETTINGS
General Settings:
Number of clusters: The user can select from 3 to five clusters. A good rule of thumb is that if you are trading intraday, less is more (Think 3 rather than 5). For daily 4 to 5 clusters is good.
Cluster Method: To get around the outlier limitation of k means clustering, The median was added. This gives the user the ability to choose either k means or k median clustering. K means is the preferred method if the user things there are no large outliers, and if there appears to be large outliers or it is assumed there are then K medians is preferred.
Bars back To train on: This will be the amount of bars to include in the clustering. This number is important so that the user includes bars that are recent but not so far back that they are out of the scope of where price can be. For example the last 2 years we have been in a range on the sp500 so 505 days in this setting would be more relevant than say looking back 5 years ago because price would have to move far to get there.
Show SD Bands: Select this to show the 1 standard deviation bands around the support and resistance level or unselect this to just show the support and resistance level by itself.
Features:
Besides the support and resistance levels and standard deviation bands, this indicator gives a table in the upper right hand corner to show the density of each cluster (support and resistance level) and is color coded to the cluster line on the chart. Higher density clusters mean price has been there previously more than lower density clusters and could mean a higher likelihood of a reversal when price reaches these areas.
█ WORKS CITED
Victor Sim, "Using K-means Clustering to Create Support and Resistance", 2020, towardsdatascience.com
Chris Piech, "K means", stanford.edu
█ ACKNOLWEDGMENTS
@jdehorty- Thanks for the publish template. It made organizing my thoughts and work alot easier.

Variety MA Cluster Filter Crosses [Loxx]What is a Cluster Filter?
One of the approaches to determining a useful signal (trend) in stream data. Small filtering (smoothing) tests applied to market quotes demonstrate the potential for creating non-lagging digital filters (indicators) that are not redrawn on the last bars.
Standard Approach
This approach is based on classical time series smoothing methods. There are lots of articles devoted to this subject both on this and other websites. The results are also classical:
1. The changes in trends are displayed with latency;
2. Better indicator (digital filter) response achieved at the expense of smoothing quality decrease;
3. Attempts to implement non-lagging indicators lead to redrawing on the last samples (bars).
And whereas traders have learned to cope with these things using persistence of economic processes and other tricks, this would be unacceptable in evaluating real-time experimental data, e.g. when testing aerostructures.
The Main Problem
It is a known fact that the majority of trading systems stop performing with the course of time, and that the indicators are only indicative over certain intervals. This can easily be explained: market quotes are not stationary. The definition of a stationary process is available in Wikipedia:
A stationary process is a stochastic process whose joint probability distribution does not change when shifted in time.
Judging by this definition, methods of analysis of stationary time series are not applicable in technical analysis. And this is understandable. A skillful market-maker entering the market will mess up all the calculations we may have made prior to that with regard to parameters of a known series of market quotes.
Even though this seems obvious, a lot of indicators are based on the theory of stationary time series analysis. Examples of such indicators are moving averages and their modifications. However, there are some attempts to create adaptive indicators. They are supposed to take into account non-stationarity of market quotes to some extent, yet they do not seem to work wonders. The attempts to "punish" the market-maker using the currently known methods of analysis of non-stationary series (wavelets, empirical modes and others) are not successful either. It looks like a certain key factor is constantly being ignored or unidentified.
The main reason for this is that the methods used are not designed for working with stream data. All (or almost all) of them were developed for analysis of the already known or, speaking in terms of technical analysis, historical data. These methods are convenient, e.g., in geophysics: you feel the earthquake, get a seismogram and then analyze it for few months. In other words, these methods are appropriate where uncertainties arising at the ends of a time series in the course of filtering affect the end result.
When analyzing experimental stream data or market quotes, we are focused on the most recent data received, rather than history. These are data that cannot be dealt with using classical algorithms.
Cluster Filter
Cluster filter is a set of digital filters approximating the initial sequence. Cluster filters should not be confused with cluster indicators.
Cluster filters are convenient when analyzing non-stationary time series in real time, in other words, stream data. It means that these filters are of principal interest not for smoothing the already known time series values, but for getting the most probable smoothed values of the new data received in real time.
Unlike various decomposition methods or simply filters of desired frequency, cluster filters create a composition or a fan of probable values of initial series which are further analyzed for approximation of the initial sequence. The input sequence acts more as a reference than the target of the analysis. The main analysis concerns values calculated by a set of filters after processing the data received.
In the general case, every filter included in the cluster has its own individual characteristics and is not related to others in any way. These filters are sometimes customized for the analysis of a stationary time series of their own which describes individual properties of the initial non-stationary time series. In the simplest case, if the initial non-stationary series changes its parameters, the filters "switch" over. Thus, a cluster filter tracks real time changes in characteristics.
Cluster Filter Design Procedure
Any cluster filter can be designed in three steps:
1. The first step is usually the most difficult one but this is where probabilistic models of stream data received are formed. The number of these models can be arbitrary large. They are not always related to physical processes that affect the approximable data. The more precisely models describe the approximable sequence, the higher the probability to get a non-lagging cluster filter.
2. At the second step, one or more digital filters are created for each model. The most general condition for joining filters together in a cluster is that they belong to the models describing the approximable sequence.
3. So, we can have one or more filters in a cluster. Consequently, with each new sample we have the sample value and one or more filter values. Thus, with each sample we have a vector or artificial noise made up of several (minimum two) values. All we need to do now is to select the most appropriate value.
An Example of a Simple Cluster Filter
For illustration, we will implement a simple cluster filter corresponding to the above diagram, using market quotes as input sequence. You can simply use closing prices of any time frame.
1. Model description. We will proceed on the assumption that:
The aproximate sequence is non-stationary, i.e. its characteristics tend to change with the course of time.
The closing price of a bar is not the actual bar price. In other words, the registered closing price of a bar is one of the noise movements, like other price movements on that bar.
The actual price or the actual value of the approximable sequence is between the closing price of the current bar and the closing price of the previous bar.
The approximable sequence tends to maintain its direction. That is, if it was growing on the previous bar, it will tend to keep on growing on the current bar.
2. Selecting digital filters. For the sake of simplicity, we take two filters:
The first filter will be a variety filter calculated based on the last closing prices using the slow period. I believe this fits well in the third assumption we specified for our model.
Since we have a non-stationary filter, we will try to also use an additional filter that will hopefully facilitate to identify changes in characteristics of the time series. I've chosen a variety filter using the fast period.
3. Selecting the appropriate value for the cluster filter.
So, with each new sample we will have the sample value (closing price), as well as the value of MA and fast filter. The closing price will be ignored according to the second assumption specified for our model. Further, we select the МА or ЕМА value based on the last assumption, i.e. maintaining trend direction:
For an uptrend, i.e. CF(i-1)>CF(i-2), we select one of the following four variants:
if CF(i-1)fastfilter(i), then CF(i)=slowfilter(i);
if CF(i-1)>slowfilter(i) and CF(i-1)slowfilter(i) and CF(i-1)>fastfilter(i), then CF(i)=MAX(slowfilter(i),fastfilter(i)).
For a downtrend, i.e. CF(i-1)slowfilter(i) and CF(i-1)>fastfilter(i), then CF(i)=MAX(slowfilter(i),fastfilter(i));
if CF(i-1)>slowfilter(i) and CF(i-1)fastfilter(i), then CF(i)=fastfilter(i);
if CF(i-1)
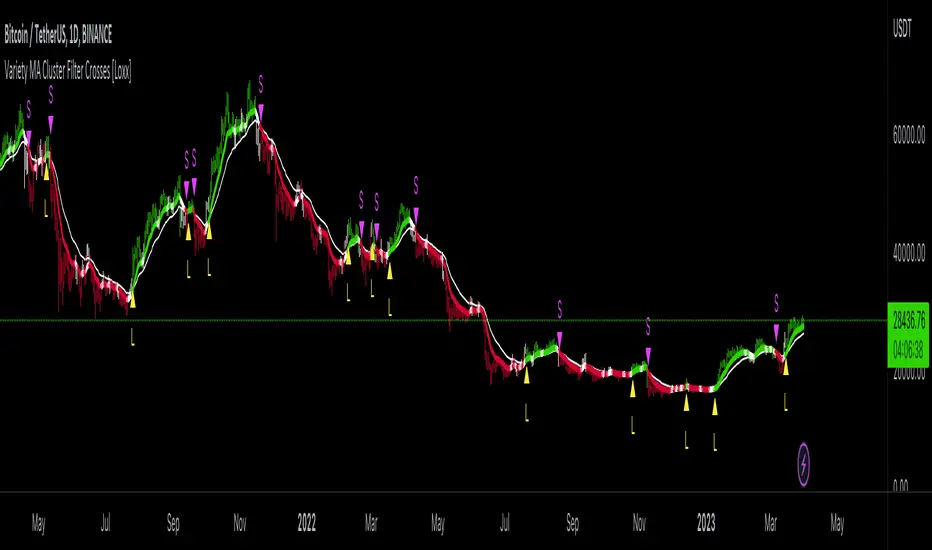
Variety MA Cluster Filter [Loxx]Variety MA Cluster Filter is one method of creating a low-lag digital filter. This is done by calculating two moving averages and then comparing their output to the past value of the combined output and then choosing the max and min between the two moving averages to then determine the combined output. I've included standard deviation filtering for smoothing.
What is a Standard Deviation Filter?
If price or output or both don't move more than the (standard deviation) * multiplier then the trend stays the previous bar trend. This will appear on the chart as "stepping" of the moving average line. This works similar to Super Trend or Parabolic SAR but is a more naive technique of filtering.
Included
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types
Loxx's Moving Averages
SignalProcessingClusteringKMeansLibrary "SignalProcessingClusteringKMeans"
K-Means Clustering Method.
nearest(point_x, point_y, centers_x, centers_y) finds the nearest center to a point and returns its distance and center index.
Parameters:
point_x : float, x coordinate of point.
point_y : float, y coordinate of point.
centers_x : float array, x coordinates of cluster centers.
centers_y : float array, y coordinates of cluster centers.
@ returns tuple of int, float.
bisection_search(samples, value) Bissection Search
Parameters:
samples : float array, weights to compare.
value : float array, weights to compare.
Returns: int.
label_points(points_x, points_y, centers_x, centers_y) labels each point index with cluster index and distance.
Parameters:
points_x : float array, x coordinates of points.
points_y : float array, y coordinates of points.
centers_x : float array, x coordinates of points.
centers_y : float array, y coordinates of points.
Returns: tuple with int array, float array.
kpp(points_x, points_y, n_clusters) K-Means++ Clustering adapted from Andy Allinger.
Parameters:
points_x : float array, x coordinates of the points.
points_y : float array, y coordinates of the points.
n_clusters : int, number of clusters.
Returns: tuple with 2 arrays, float array, int array.

Fibonacci Extension / Retracement / Pivot Points by DGTFɪʙᴏɴᴀᴄᴄɪ Exᴛᴇɴᴛɪᴏɴ / Rᴇᴛʀᴀᴄᴍᴇɴᴛ / Pɪᴠᴏᴛ Pᴏɪɴᴛꜱ
This study combines various Fibonacci concepts into one, and some basic volume and volatility indications
█ Pɪᴠᴏᴛ Pᴏɪɴᴛꜱ — is a technical indicator that is used to determine the levels at which price may face support or resistance. The Pivot Points indicator consists of a pivot point (PP) level and several support (S) and resistance (R) levels. PP, resistance and support values are calculated in different ways, depending on the type of the indicator, this study implements Fibonacci Pivot Points
The indicator resolution is set by the input of the Pivot Points TF (Timeframe). If the Pivot Points TF is set to AUTO (the default value), then the increased resolution is determined by the following algorithm:
for intraday resolutions up to and including 5 min, 4HOURS (4H) is used
for intraday resolutions more than 5 min and up to and including 45 min, DAY (1D) is used
for intraday resolutions more than 45 min and up to and including 4 hour, WEEK (1W) is used
for daily resolutions MONTH is used (1M)
for weekly resolutions, 3-MONTH (3M) is used
for monthly resolutions, 12-MONTH (12M) is used
If the Pivot Points TF is set to User Defined, users may choose any higher timeframe of their preference
█ Fɪʙ Rᴇᴛʀᴀᴄᴇᴍᴇɴᴛ — Fibonacci retracements is a popular instrument used by technical analysts to determine support and resistance areas. In technical analysis, this tool is created by taking two extreme points (usually a peak and a trough) on the chart and dividing the vertical distance by the key Fibonacci coefficients equal to 23.6%, 38.2%, 50%, 61.8%, and 100%. This study implements an automated method of identifying the pivot lows/highs and automatically draws horizontal lines that are used to determine possible support and resistance levels
█ Fɪʙᴏɴᴀᴄᴄɪ Exᴛᴇɴꜱɪᴏɴꜱ — Fibonacci extensions are a tool that traders can use to establish profit targets or estimate how far a price may travel AFTER a retracement/pullback is finished. Extension levels are also possible areas where the price may reverse. This study implements an automated method of identifying the pivot lows/highs and automatically draws horizontal lines that are used to determine possible support and resistance levels.
IMPORTANT NOTE: Fibonacci extensions option may require to do further adjustment of the study parameters for proper usage. Extensions are aimed to be used when a trend is present and they aim to measure how far a price may travel AFTER a retracement/pullback. I will strongly suggest users of this study to check the education post for further details, where to use extensions and where to use retracements
Important input options for both Fibonacci Extensions and Retracements
Deviation, is a multiplier that affects how much the price should deviate from the previous pivot in order for the bar to become a new pivot. Increasing its value is one way to get higher timeframe Fib Retracement Levels
Depth, affects the minimum number of bars that will be taken into account when building
█ Volume / Volatility Add-Ons
High Volatile Bar Indication
Volume Spike Bar Indication
Volume Weighted Colored Bars
This study benefits from build-in auto fib retracement tv study and modifications applied to get extentions and also to fit this combo
Disclaimer:
Trading success is all about following your trading strategy and the indicators should fit within your trading strategy, and not to be traded upon solely
The script is for informational and educational purposes only. Use of the script does not constitute professional and/or financial advice. You alone have the sole responsibility of evaluating the script output and risks associated with the use of the script. In exchange for using the script, you agree not to hold dgtrd TradingView user liable for any possible claim for damages arising from any decision you make based on use of the script

Function K-Means ClusteringDescription:
A Function that returns cluster centers for given data (X,Y) vector points.
Inputs:
_X: Array containing x data points.¹
_Y: Array containing y data points.¹
_number_of_clusters: number of clusters.
Note:
¹: _X and _Y size must match.
Outputs:
_centers_x: Array containing x data points.
_centers_y: Array containing y data points.
Resources:
rosettacode.org
en.wikipedia.org

Poor man's volume clustersVolume clusters created from candlestick volumes.
See also "Poor man's volume profile" .
The code is generated using a template. To change the settings, you may need to regenerate the code. The code has a link to the repository with the template.

SMA/EMA SR mtf Clusters v0.9SMA and EMA endings to identify support and resistance with a good chart overview.
Unfortunately the scaling of TradingView in intraday charts is not good.

Fibonacci ClustersI was reading about Fibonacci Clusters on investopedia (www.investopedia.com) and couldn't find a script for it on tradingveiw. Apparently some people use it successfully but I found it a little chaotic. This script will mark the retracements in a window's length, and you can set this for six windows. This script isn't very pretty because it doesn't seem obviously useful and pinescript has far too many deficiencies to fully flesh this idea out. I was able to make more sense out of larger windowing times (500-4000 periods), than shorter ones (25-333). Try it out, see what it shows you. Happy trading

[RS]MTF Fibonacci Cycles V0EXPERIMENTAL:
Fibonacci rate levels based on price advance/decline, can be used to make visualizations of fib clusters or for cycles.