True Range Breakout [racer8]TRB (True Range Breakout) plots the current TR (true range) as well as the previous TR high over n periods. If the current TR is greater than the previous TR high, then the TR histogram will become red. Red signals high volatility. Enter trades only when the histogram is above the TR high line. Happy trading! 🥳
Cari dalam skrip untuk "Volatility"

AVWTR (Average Volume Weighted True Range)A better tool to measure market volatility. The true ranges are weighted by the volume and averaged through the specified period.

AlignedMA and Cumulative HighLow Strategy V2Based on earlier strategy published - AlignedMA and Cumulative HighLow Strategy. Adjustments are done in entry and exit criteria to make it work for shares.
Modified to preserve existing entry criteria + additional MA shift condition. Exit criteria is set based on supertrend and trailing stops.
Most of the parameters are already optimized. You only need to alter SupertrendMult for individual shares based on individual share volatility. Usually works within 2-4.
There might be bit of repainting. I am unable to understand if there is any. Any suggestions on further improvements welcome :)
Note to moderators : I have used 1000 as initial capital with 100% on each trade. As strategy does not compound - I believe this is reasonable. I have kept this setting as this makes it easier to compare with buy and hold return.

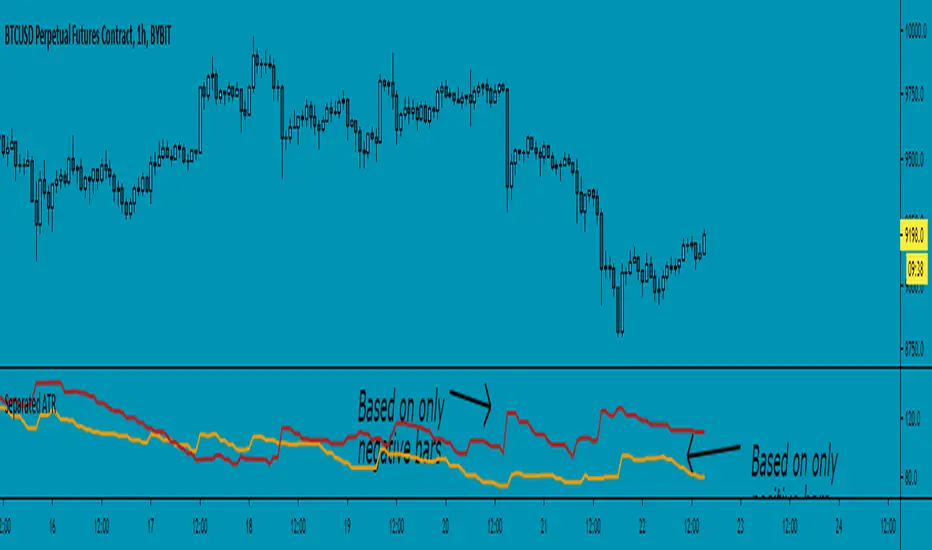
Separated ATR - evoThis script plots two ATR (Average True Range) values, one based on only bullish and the other based on only bearish bars. If the current bar is positive, the negative ATR will use its last known negative bar for the calculation. You can smooth bar directions by using the Heikin Ashi setting.
Use this the same way how you would use the regular ATR indicator, but with the added value of knowing which side of the market has more volatility.
Strategy - Bobo PAPATRHi I've revamped this bot mentioned in the linked idea to make it work with v4 of pine. In doing so there are some very significant changes to how it works. The main one is that it no longer uses traditional daily pivot calculations to calculate the bands. It creates a more dynamic intraday set of pivot points based on recent price action rather than yesterday's ohlc. As published, the bot is tuned for a 15 min time frame. But it actually works well on lower time frames you just need to adjust the lookback periods in settings a bit to re tune it. It's also tuned to ES really but will need tweaking for a different instrument at the very least.
The basic concept is recent price action is used to calculate a 'middle' around which red and green bands are located. Their position or width is largely determined by recent volatility. The middle line is again calculated from recent price action. The three lines from that form a tradeable range with green at the top and red at the bottom. The strategy is simple enough, it shorts as it sinks from outside red, and longs when rising above green. The basic principle being that once you enter that range you have a high probability of hitting the middle before you hit your stop loss. So the basic principle is you are trying to capture the inherent ranginess of liquid indices like S&P 500. That back and forth movement that happens. The bot is capturing this by fading extremes of a recent range but the problem with that is you'dd get murdered in a strong trend. To mitigate that there is a trend calculation running in the background the will prevent trading against firm trends mostly. So the bot should trade mostly in rangy conditions because that is what it is trying to do.
Bot will close issue close signals automatically upon crossing the middle, it also will close automatically at predefined stops or limits. These values are denominated in market mintick values. For example the CFD SPX500 has a mintick of 0.1. Therefore a stop value of 100 will equate to 10 points on the index. If trading the same market via ES1! the mintick value is different - 0.25. So in this case a value of 40 is required to set the stop at 10 points.
Anyway shout if you have questions. Hope it's useful.
TVC:SPX OANDA:SPX500USD

SuperTrendSuperTrend is one of the most common ATR based trailing stop indicators.
In this version you can change the ATR calculation method from the settings. Default method is RMA, when the alternative method is SMA.
The indicator is easy to use and gives an accurate reading about an ongoing trend. It is constructed with two parameters, namely period and multiplier. The default values used while constructing a superindicator are 10 for average true range or trading period and three for its multiplier.
The average true range (ATR) plays an important role in 'Supertrend' as the indicator uses ATR to calculate its value. The ATR indicator signals the degree of price volatility.
The buy and sell signals are generated when the indicator starts plotting either on top of the closing price or below the closing price. A buy signal is generated when the ‘Supertrend’ closes above the price and a sell signal is generated when it closes below the closing price.
It also suggests that the trend is shifting from descending mode to ascending mode. Contrary to this, when a ‘Supertrend’ closes above the price, it generates a sell signal as the colour of the indicator changes into red.
A ‘Supertrend’ indicator can be used on equities, futures or forex, or even crypto markets and also on daily, weekly and hourly charts as well, but generally, it fails in a sideways-moving market.
I had converted Supertrend indicator code for various platforms like Metastock in 2017, but in this TradingView version special credit goes to everget - Alex Orekhov which gave a great inspiration to look my indicators better with highlights, signals and alarms. Thank you Alex.
(Poshtrader) Bollinger Band SqueezeThe Bollinger Band Squeeze is a trading strategy designed to find consolidations with decreasing volatility. In its simplest form, this strategy is neutral and the ensuing break can be up or down. Traders, therefore, must employ other aspects of technical analysis to formulate a trading bias to act before the break or confirm the break. Acting before the break will improve the risk-reward ratio.

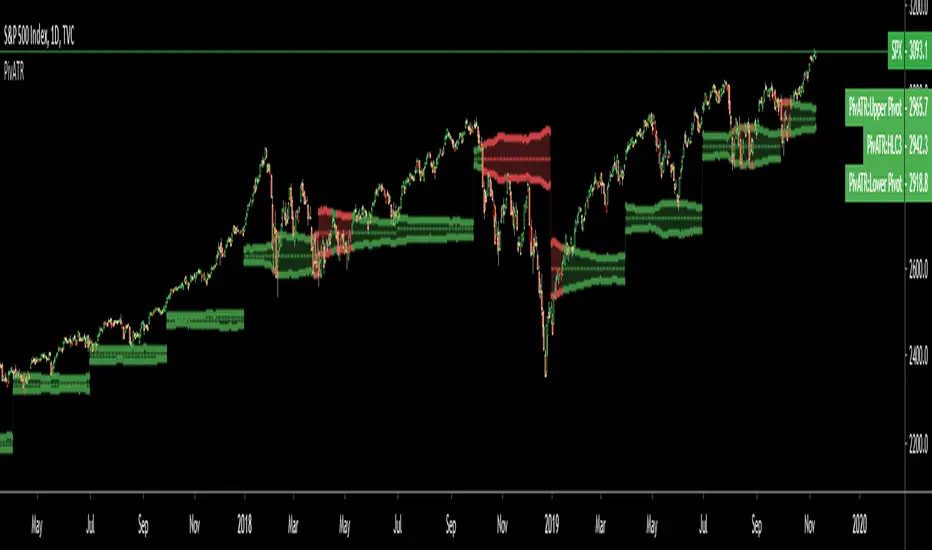
Adaptive Pivot (HLC3)SUMMARY:
Standard Pivot (HLC3) with ATR leeway added to make it adaptive to market volatility.
DESCRIPTION:
Adaptive Pivot is an indicator utilizing the simplicity of HLC3 Pivots as a turning point (and sometimes a trend indicator) while addressing it's fixed and inflexible nature.
Because the indicator is just a single line in the chart, the price may go near it but never touch it. Or it can go pass through it and never retest it again. In an attempt to lessen these from occurring, we can combine pivots with average true range (ATR). This is the specific formula I applied in this indicator:
>Upper Pivot = HLC3 + ATR
>Lower Pivot = HLC3 - ATR
This creates a kind of a range or cloud around the Pivot, making it possibly a more accurate indicator for market turning points.
ADJUSTABLE PARAMETERS:
The usual ATR parameters are included in this indicator:
>ATR_Length = input(14, title="ATR Length", minval=1)
>ATR_Smoothing = input(title="ATR Smoothing", defval="RMA", options="RMA", "SMA", "EMA", "WMA")
Added to the usual ones is this:
>ATR_Multiplier = input(1, title="ATR Multiplier", minval=0.1)
which modifies the extent of the ATR (similar to Chandelier Exit) as it is added/subtracted from the pivot values.
Pivot’s timeframe is also adjustable:
>Pivot_Timeframe = input("3M", title='Pivot Resolution')
Note: I did not lock the type to input.resolution to allow for more possible timeframes.
OTHER PARAMETERS
Indicator color will change to green when the open is above the HLC3 Pivot and change to red when the reverse is true.
Dynamically Adjustable Moving AverageIntroduction
The Dynamically Adjustable Moving Average (AMA) is an adaptive moving average proposed by Jacinta Chan Phooi M’ng (1) originally provided to forecast Asian Tiger's futures markets. AMA adjust to market condition in order to avoid whipsaw trades as well as entering the trending market earlier. This moving average showed better results than classical methods (SMA20, EMA20, MAC, MACD, KAMA, OptSMA) using a classical crossover/under strategy in Asian Tiger's futures from 2014 to 2015.
Dynamically Adjustable Moving Average
AMA adjust to market condition using a non-exponential method, which in itself is not common, AMA is described as follow :
1/v * sum(close,v)
where v = σ/√σ
σ is the price standard deviation.
v is defined as the Efficacy Ratio (not be confounded with the Efficiency Ratio) . As you can see v determine the moving average period, you could resume the formula in pine with sma(close,v) but in pine its not possible to use the function sma with variables for length, however you can derive sma using cumulation.
sma ≈ d/length where d = c - c_length and c = cum(close)
So a moving average can be expressed as the difference of the cumulated price by the cumulated price length period back, this difference is then divided by length. The length period of the indicator should be short since rounded version of v tend to become less variables thus providing less adaptive results.
AMA in Forex Market
In 2014/2015 Major Forex currencies where more persistent than Asian Tiger's Futures (2) , also most traded currency pairs tend to have a strong long-term positive autocorrelation so AMA could have in theory provided good results if we only focus on the long term dependency. AMA has been tested with ASEAN-5 Currencies (3) and still showed good results, however forex is still a tricky market, also there is zero proof that switching to a long term moving average during ranging market avoid whipsaw trades (if you have a paper who prove it please pm me) .
Conclusion
An interesting indicator, however the idea behind it is far from being optimal, so far most adaptive methods tend to focus more in adapting themselves to market complexity than volatility. An interesting approach would have been to determine the validity of a signal by checking the efficacy ratio at time t . Backtesting could be a good way to see if the indicator is still performing well.
References
(1) J.C.P. M’ng, Dynamically adjustable moving average (AMA’) technical
analysis indicator to forecast Asian Tigers’ futures markets, Physica A (2018),
doi.org
(2) www.researchgate.net
(3) www.ncbi.nlm.nih.gov
DD ATR bandsThe top band is ATR added to candle high (with given length and multiplication). The bottom one is analogic.
Created for finding initial stop loss for entry on low timeframes. Use band value at last major high/low to place the stop loss at.
It shows prices with acceptable risk and a reasonable margin for market volatility.
Brooks Type Signal BarIndicates "strong bars" similar to how Al Brooks defines them in his book-- these don't necessarily trigger entries but can be points of interest.
2-3 points as a signal bar size seems to work well, depending upon volatility.
btcATR Bitfinex [csg]A simple script that uses the average true range indicator and compares it against bitcoin's market cap to obtain a visual representation of bitcoin's historical volatility.
A version of this indicator will be made for other coins once tradingview gives us access to the market cap data

Bollinger Band Percent Width Crossing RSIBollinger Band width is hard to follow on log charts, but it's an excellent indicator for volatility. When BBand % width crosses down through periods of low crosses down through periods where RSI is low, you may be able to count on a substantial reversal over the intermediate or long-term.

Directional Movement Bands [DW]This is a simple experimental study designed to outline trend activity and volatility.
In this study, the amount of change between current source and source of a specified lookback is calculated, then added to and subtracted from current source.
Next an exponential moving average is taken of the values for smoothing over the specified period.
Lastly, a midline is generated by taking the median of both bands.
Volatility Finite Volume Elements Strategy The FVE is a pure volume indicator. Unlike most of the other indicators
(except OBV), price change doesn?t come into the equation for the FVE
(price is not multiplied by volume), but is only used to determine whether
money is flowing in or out of the stock. This is contrary to the current trend
in the design of modern money flow indicators. The author decided against a
price-volume indicator for the following reasons:
- A pure volume indicator has more power to contradict.
- The number of buyers or sellers (which is assessed by volume) will be the same,
regardless of the price fluctuation.
- Price-volume indicators tend to spike excessively at breakouts or breakdowns.
This study is an addition to FVE indicator. Indicator plots different-coloured volume
bars depending on volatility.
You can change long to short in the Input Settings
Please, use it only for learning or paper trading. Do not
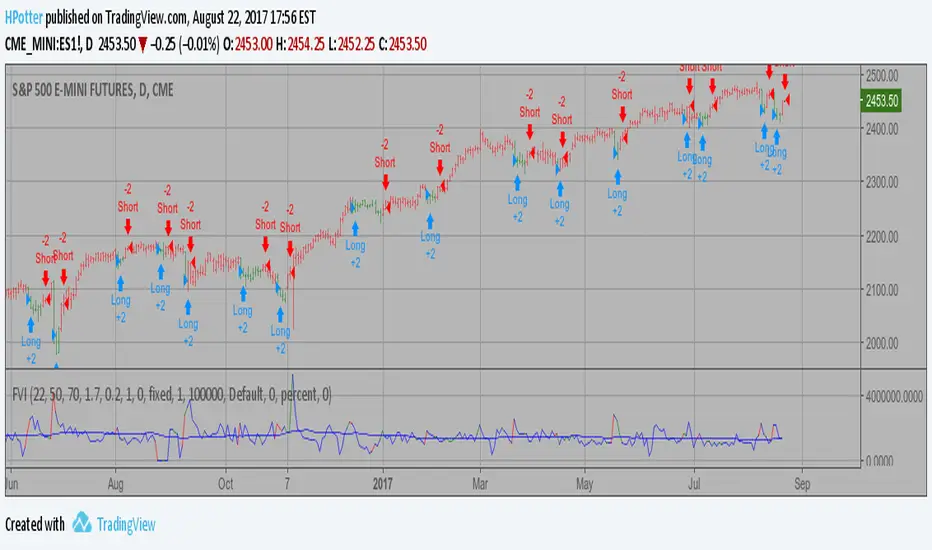
Volatility Finite Volume Elements Strategy The FVE is a pure volume indicator. Unlike most of the other indicators
(except OBV), price change doesn?t come into the equation for the FVE
(price is not multiplied by volume), but is only used to determine whether
money is flowing in or out of the stock. This is contrary to the current trend
in the design of modern money flow indicators. The author decided against a
price-volume indicator for the following reasons:
- A pure volume indicator has more power to contradict.
- The number of buyers or sellers (which is assessed by volume) will be the same,
regardless of the price fluctuation.
- Price-volume indicators tend to spike excessively at breakouts or breakdowns.
This study is an addition to FVE indicator. Indicator plots different-coloured volume
bars depending on volatility.
Moving CO-covariance (covariance on covariance)This is Covariance on Covariance. It shows you how much a given covariance period has deviated from it mean over another defined period. Because it is a time series, It can allow you to spot changes in how covariance changes. You can apply trend lines, Fibonacci retracements, etc. This is also volume weighting covariance.
This is not a directional indicator nor is moving covariance. This is used for forecasting volatility. This must be used in conjunction with moving covariance.
Zero-Lag ATR Trend [BackQuant]Zero-Lag ATR Trend
Overview
Zero-Lag ATR Trend is a volatility-adaptive trend-following overlay designed to identify directional market regimes with minimal delay while preserving structural clarity. The indicator combines a zero-lag moving average framework with a zero-lag volatility model to produce a trailing trend line that reacts quickly to meaningful price changes without becoming unstable or overly sensitive.
Unlike conventional ATR-based trend tools that rely on lagging averages and delayed volatility estimates, this indicator applies zero-lag logic to both the trend centerline and the volatility calculation. The result is a trend structure that aligns more closely with real-time price action while still maintaining the discipline required for trend continuation trading.
Core design philosophy
The core idea behind Zero-Lag ATR Trend is simple:
Reduce signal delay without sacrificing trend integrity.
Adapt dynamically to changing volatility regimes.
Provide a single, clean structure that defines trend direction, continuation, and invalidation.
Instead of stacking multiple indicators, the script builds a complete trend framework from two tightly integrated components: a zero-lag trend spine and a zero-lag ATR trailing mechanism.
Zero-lag trend spine
The trend spine is constructed using a zero-lag moving average (ZLMA). This is achieved by applying a corrective step to a traditional moving average, effectively compensating for smoothing delay.
Conceptually, the process works as follows:
A base moving average is calculated from the selected price source.
That moving average is then passed through a zero-lag correction.
The correction pulls the line closer to current price without introducing noise.
This produces a trend line that reacts faster than standard EMA, SMA, or HMA signals, particularly during early trend acceleration phases. Multiple moving-average types can be used inside the zero-lag framework, allowing traders to fine-tune responsiveness based on asset behavior and timeframe.
Zero-lag volatility model
Volatility is measured using True Range, but instead of applying classic ATR smoothing, the indicator uses a zero-lag smoothing pass on the True Range itself.
This approach offers several advantages:
Volatility expands more quickly during impulse moves.
Volatility contracts faster during consolidations.
Band width adjusts in near real-time to changing conditions.
The smoothed zero-lag ATR is multiplied by a user-defined factor to create adaptive upper and lower boundaries around the trend spine. These boundaries define how much counter-movement price is allowed before the trend structure is invalidated.
Volatility-aware trailing structure
The trailing output is the defining feature of the indicator. It behaves as a one-directional trailing structure:
In bullish conditions, the trailing line can only move upward.
In bearish conditions, the trailing line can only move downward.
Minor pullbacks inside the volatility envelope do not flip the trend.
This logic prevents the indicator from reacting to shallow retracements and focuses instead on structural trend changes. Because the trailing behavior is volatility-scaled, the indicator remains stable during high volatility while still responding promptly during regime shifts.
Trend flips and regime transitions
Trend direction is determined by changes in the trailing structure itself rather than raw price crosses. A trend flip occurs only when price movement is strong enough, relative to current volatility, to force the trailing line to reverse direction.
This means:
Bullish flips represent genuine transitions into upward regimes.
Bearish flips represent genuine transitions into downward regimes.
Sideways noise is largely filtered out.
As a result, the indicator is well suited for identifying medium-to-long trend phases rather than short-term oscillations.
Visual structure and chart clarity
The visual design is intentionally minimal and functional:
The main trailing line is color-coded by trend direction.
An optional ribbon or cloud reinforces directional bias.
Optional candle coloring aligns price bars with the active trend.
These elements allow traders to assess trend state instantly without interpreting multiple signals or overlays.
How to use for trend following
Trend bias
Maintain a bullish bias while price holds above the trailing line.
Maintain a bearish bias while price holds below the trailing line.
Entries
Trend flips can be used as initial directional entries.
Pullbacks toward the trailing line often act as continuation opportunities.
Momentum confirmation can be layered on top for additional confluence.
Trend management
The trailing line naturally functions as a dynamic stop reference.
As long as price respects the trailing structure, the trend remains valid.
A flip in direction signals a full regime transition rather than a minor correction.
Why zero-lag matters for trend trading
Traditional trend indicators often react late, especially during fast expansions, resulting in delayed entries and early exits. By reducing lag in both the trend calculation and the volatility model, Zero-Lag ATR Trend aims to capture a larger portion of directional moves while maintaining consistency and discipline.
This makes it particularly effective for momentum-based trend following, breakout continuation strategies, and traders who prioritize staying aligned with dominant market structure rather than predicting reversals.
Summary
Zero-Lag ATR Trend is a complete trend-following framework built around responsiveness, adaptability, and clarity. Its zero-lag architecture allows it to respond earlier to meaningful price changes, while its volatility-aware trailing logic ensures that trends are only invalidated when structure truly breaks. The result is a clean, intuitive tool that supports disciplined trend participation across assets and timeframes.

Advanced Speedometer Gauge [PhenLabs]Advanced Speedometer Gauge
Version: PineScript™v6
📌 Description
The Advanced Speedometer Gauge is a revolutionary multi-metric visualization tool that consolidates 13 distinct trading indicators into a single, intuitive speedometer display. Instead of cluttering your workspace with multiple oscillators and panels, this gauge provides a unified interface where you can switch between different metrics while maintaining consistent visual interpretation.
Built on PineScript™ v6, the indicator transforms complex technical calculations into an easy-to-read semi-circular gauge with color-coded zones and a precision needle indicator. Each of the 13 available metrics has been carefully normalized to a 0-100 scale, ensuring that whether you’re analyzing RSI, volume trends, or volatility extremes, the visual interpretation remains consistent and intuitive.
The gauge is designed for traders who value efficiency and clarity. By consolidating multiple analytical perspectives into one compact display, you can quickly assess market conditions without the visual noise of traditional multi-indicator setups. All metrics are non-overlapping, meaning each provides unique insights into different aspects of market behavior.
🚀 Points of Innovation
13 selectable metrics covering momentum, volume, volatility, trend, and statistical analysis, all accessible through a single dropdown menu
Universal 0-100 normalization system that standardizes different indicator scales for consistent visual interpretation across all metrics
Semi-circular gauge design with 21 arc segments providing smooth precision and clear visual feedback through color-coded zones
Non-redundant metric selection ensuring each indicator provides unique market insights without analytical overlap
Advanced metrics including MFI (volume-weighted momentum), CCI (statistical deviation), Volatility Rank (extended lookback), Trend Strength (ADX-style), Choppiness Index, Volume Trend, and Price Distance from MA
Flexible positioning system with 5 chart locations, 3 size options, and fully customizable color schemes for optimal workspace integration
🔧 Core Components
Metric Selection Engine: Dropdown interface allowing instant switching between 13 different technical indicators, each with independent parameter controls
Normalization System: All metrics converted to 0-100 scale using indicator-specific algorithms that preserve the statistical significance of each measurement
Semi-Circular Gauge: Visual display using 21 arc segments arranged in curved formation with two-row thickness for enhanced visibility
Color Zone System: Three distinct zones (0-40 green, 40-70 yellow, 70-100 red) providing instant visual feedback on metric extremes
Needle Indicator: Dynamic pointer that positions across the gauge arc based on precise current metric value
Table Implementation: Professional table structure ensuring consistent positioning and rendering across different chart configurations
🔥 Key Features
RSI (Relative Strength Index): Classic momentum oscillator measuring overbought/oversold conditions with adjustable period length (default 14)
Stochastic Oscillator: Compares closing price to price range over specified period with smoothing, ideal for identifying momentum shifts
MFI (Money Flow Index): Volume-weighted RSI that combines price movement with volume to measure buying and selling pressure intensity
CCI (Commodity Channel Index): Measures statistical deviation from average price, normalized from typical -200 to +200 range to 0-100 scale
Williams %R: Alternative overbought/oversold indicator using high-low range analysis, inverted to match 0-100 scale conventions
Volume %: Current volume relative to moving average expressed as percentage, capped at 100 for extreme spikes
Volume Trend: Cumulative directional volume flow showing whether volume is flowing into up moves or down moves over specified period
ATR Percentile: Current Average True Range position within historical range using specified lookback period (default 100 bars)
Volatility Rank: Close-to-close volatility measured against extended historical range (default 252 days), differs from ATR in calculation method
Momentum: Rate of change calculation showing price movement speed, centered at 50 and normalized to 0-100 range
Trend Strength: ADX-style calculation using directional movement to quantify trend intensity regardless of direction
Choppiness Index: Measures market choppiness versus trending behavior, where high values indicate ranging markets and low values indicate strong trends
Price Distance from MA: Measures current price over-extension from moving average using standard deviation calculations
🎨 Visualization
Semi-Circular Arc Display: Curved gauge spanning from 0 (left) to 100 (right) with smooth progression and two-row thickness for visibility
Color-Coded Zones: Green zone (0-40) for low/oversold conditions, yellow zone (40-70) for neutral readings, red zone (70-100) for high/overbought conditions
Needle Indicator: Downward-pointing triangle (▼) positioned precisely at current metric value along the gauge arc
Scale Markers: Vertical line markers at 0, 25, 50, 75, and 100 positions with corresponding numerical labels below
Title Display: Merged cell showing “𓄀 PhenLabs” branding plus currently selected metric name in monospace font
Large Value Display: Current metric value shown with two decimal precision in large text directly below title
Table Structure: Professional table with customizable background color, text color, and transparency for minimal chart obstruction
📖 Usage Guidelines
Metric Selection
Select Metric: Default: RSI | Options: RSI, Stochastic, Volume %, ATR Percentile, Momentum, MFI (Money Flow), CCI (Commodity Channel), Williams %R, Volatility Rank, Trend Strength, Choppiness Index, Volume Trend, Price Distance | Choose the technical indicator you want to display on the gauge based on your current analytical needs
RSI Settings
RSI Length: Default: 14 | Range: 1+ | Controls the lookback period for RSI calculation, shorter periods increase sensitivity to recent price changes
Stochastic Settings
Stochastic Length: Default: 14 | Range: 1+ | Lookback period for stochastic calculation comparing close to high-low range
Stochastic Smooth: Default: 3 | Range: 1+ | Smoothing period applied to raw stochastic value to reduce noise and false signals
Volume Settings
Volume MA Length: Default: 20 | Range: 1+ | Moving average period used to calculate average volume for comparison with current volume
Volume Trend Length: Default: 20 | Range: 5+ | Period for calculating cumulative directional volume flow trend
ATR and Volatility Settings
ATR Length: Default: 14 | Range: 1+ | Period for Average True Range calculation used in ATR Percentile metric
ATR Percentile Lookback: Default: 100 | Range: 20+ | Historical range used to determine current ATR position as percentile
Volatility Rank Lookback (Days): Default: 252 | Range: 50+ | Extended lookback period for Volatility Rank metric using close-to-close volatility
Momentum and Trend Settings
Momentum Length: Default: 10 | Range: 1+ | Lookback period for rate of change calculation in Momentum metric
Trend Strength Length: Default: 20 | Range: 5+ | Period for directional movement calculations in ADX-style Trend Strength metric
Advanced Metric Settings
MFI Length: Default: 14 | Range: 1+ | Lookback period for Money Flow Index calculation combining price and volume
CCI Length: Default: 20 | Range: 1+ | Period for Commodity Channel Index statistical deviation calculation
Williams %R Length: Default: 14 | Range: 1+ | Lookback period for Williams %R high-low range analysis
Choppiness Index Length: Default: 14 | Range: 5+ | Period for calculating market choppiness versus trending behavior
Price Distance MA Length: Default: 50 | Range: 10+ | Moving average period used for Price Distance standard deviation calculation
Visual Customization
Position: Default: Top Right | Options: Top Left, Top Right, Bottom Left, Bottom Right, Middle Right | Controls gauge placement on chart for optimal workspace organization
Size: Default: Normal | Options: Small, Normal, Large | Adjusts overall gauge dimensions and text size for different monitor resolutions and preferences
Low Zone Color (0-40): Default: Green (#00FF00) | Customize color for low/oversold zone of gauge arc
Medium Zone Color (40-70): Default: Yellow (#FFFF00) | Customize color for neutral/medium zone of gauge arc
High Zone Color (70-100): Default: Red (#FF0000) | Customize color for high/overbought zone of gauge arc
Background Color: Default: Semi-transparent dark gray | Customize gauge background for contrast and chart integration
Text Color: Default: White (#FFFFFF) | Customize all text elements including title, value, and scale labels
✅ Best Use Cases
Quick visual assessment of market conditions when you need instant feedback on whether an asset is in extreme territory across multiple analytical dimensions
Workspace organization for traders who monitor multiple indicators but want to reduce chart clutter and visual complexity
Metric comparison by switching between different indicators while maintaining consistent visual interpretation through the 0-100 normalization
Overbought/oversold identification using RSI, Stochastic, Williams %R, or MFI depending on whether you prefer price-only or volume-weighted analysis
Volume analysis through Volume %, Volume Trend, or MFI to confirm price movements with corresponding volume characteristics
Volatility monitoring using ATR Percentile or Volatility Rank to identify expansion/contraction cycles and adjust position sizing
Trend vs range identification by comparing Trend Strength (high values = trending) against Choppiness Index (high values = ranging)
Statistical over-extension detection using CCI or Price Distance to identify when price has deviated significantly from normal behavior
Multi-timeframe analysis by duplicating the gauge on different timeframe charts to compare metric readings across time horizons
Educational purposes for new traders learning to interpret technical indicators through consistent visual representation
⚠️ Limitations
The gauge displays only one metric at a time, requiring manual switching to compare different indicators rather than simultaneous multi-metric viewing
The 0-100 normalization, while providing consistency, may obscure the raw values and specific nuances of each underlying indicator
Table-based visualization cannot be exported or saved as an image separately from the full chart screenshot
Optimal parameter settings vary by asset type, timeframe, and market conditions, requiring user experimentation for best results
💡 What Makes This Unique
Unified Multi-Metric Interface: The only gauge-style indicator offering 13 distinct metrics through a single interface, eliminating the need for multiple oscillator panels
Non-Overlapping Analytics: Each metric provides genuinely unique insights—MFI combines volume with price, CCI measures statistical deviation, Volatility Rank uses extended lookback, Trend Strength quantifies directional movement, and Choppiness Index measures ranging behavior
Universal Normalization System: All metrics standardized to 0-100 scale using indicator-appropriate algorithms that preserve statistical meaning while enabling consistent visual interpretation
Professional Visual Design: Semi-circular gauge with 21 arc segments, precision needle positioning, color-coded zones, and clean table implementation that maintains clarity across all chart configurations
Extensive Customization: Independent parameter controls for each metric, five position options, three size presets, and full color customization for seamless workspace integration
🔬 How It Works
1. Metric Calculation Phase:
All 13 metrics are calculated simultaneously on every bar using their respective algorithms with user-defined parameters
Each metric applies its own specific calculation method—RSI uses average gains vs losses, Stochastic compares close to high-low range, MFI incorporates typical price and volume, CCI measures deviation from statistical mean, ATR calculates true range, directional indicators measure up/down movement, and statistical metrics analyze price relationships
2. Normalization Process:
Each calculated metric is converted to a standardized 0-100 scale using indicator-appropriate transformations
Some metrics are naturally 0-100 (RSI, Stochastic, MFI, Williams %R), while others require scaling—CCI transforms from ±200 range, Momentum centers around 50, Volume ratio caps at 2x for 100, ATR and Volatility Rank calculate percentile positions, and Price Distance scales by standard deviations
3. Gauge Rendering:
The selected metric’s normalized value determines the needle position across 21 arc segments spanning 0-100
Each arc segment receives its color based on position—segments 0-8 are green zone, segments 9-14 are yellow zone, segments 15-20 are red zone
The needle indicator (▼) appears in row 5 at the column corresponding to the current metric value, providing precise visual feedback
4. Table Construction:
The gauge uses TradingView’s table system with merged cells for title and value display, ensuring consistent positioning regardless of chart configuration
Rows are allocated as follows: Row 0 merged for title, Row 1 merged for large value display, Row 2 for spacing, Rows 3-4 for the semi-circular arc with curved shaping, Row 5 for needle indicator, Row 6 for scale markers, Row 7 for numerical labels at 0/25/50/75/100
All visual elements update on every bar when barstate.islast is true, ensuring real-time accuracy without performance impact
💡 Note:
This indicator is designed for visual analysis and market condition assessment, not as a standalone trading system. For best results, combine gauge readings with price action analysis, support and resistance levels, and broader market context. Parameter optimization is recommended based on your specific trading timeframe and asset class. The gauge works on all timeframes but may require different parameter settings for intraday versus daily/weekly analysis. Consider using multiple instances of the gauge set to different metrics for comprehensive market analysis without switching between settings.

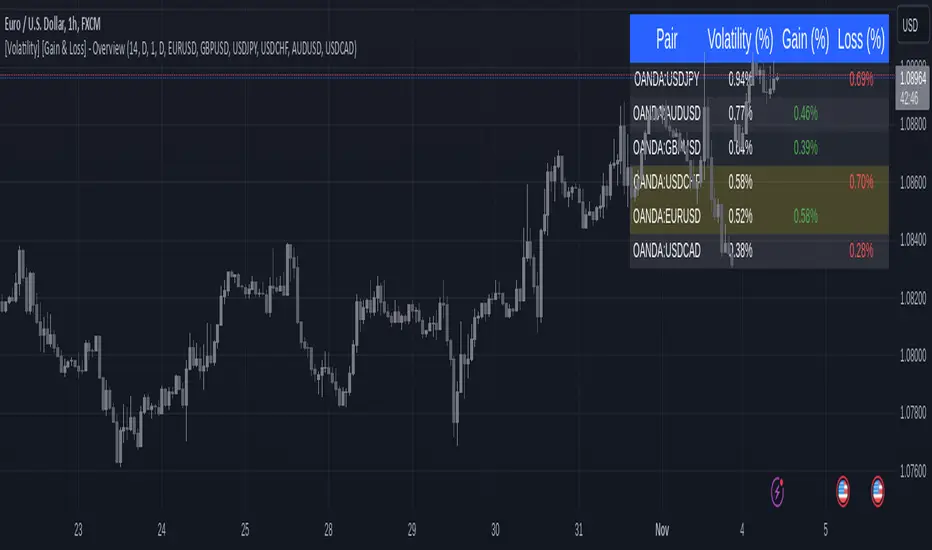
[Volatility] [Gain & Loss] - OverviewFX:EURUSD
Indicator Overview: Volatility & Gain/Loss - Forex Pair Analysis
This indicator, " —Overview" , is designed for users interested in analyzing the volatility and gain/loss metrics of multiple forex pairs. The tool is especially useful for traders aiming to assess currency pair volatility alongside gain and loss percentages over selected periods. It enables a clearer understanding of pair behavior and aids in decision-making.
Key Features
Customizable Volatility and Gain/Loss Periods : Define your preferred calculation periods and timeframes for both volatility and gain/loss to tailor the indicator to specific trading strategies. Multi-Pair Analysis : This indicator supports up to six forex pairs (default pairs include EURUSD, GBPUSD, USDJPY, USDCHF, AUDUSD, and USDCAD) and allows you to adjust these pairs as needed. Visual Ranking : Forex pairs are sorted by volatility, displaying the highest pairs at the top for quick reference. Top Gain/Loss Highlighting : The pair with the maximum gain and the pair with the maximum loss are highlighted in the table, making it easy to identify the best and worst performers at a glance.
Indicator Settings
Volatility Settings : Period : Adjust the number of periods used in the ATR (Average True Range) calculation. A default period of 14 is set. Timeframe : Select a timeframe (e.g., Daily, Weekly) for volatility calculation to match your analysis preference.
Gain/Loss Settings : Period : Choose the number of periods for gain/loss calculation. The default is set to 1. Timeframe : Select the timeframe for gain/loss calculation, independent of the volatility timeframe.
Symbol Selection : Configure up to six forex pairs. By default, popular forex pairs are pre-loaded but can be customized to include other currency pairs.
Output and Visualization
Table Display : This indicator displays data in a neatly structured table positioned in the top-right corner of your chart. Columns : Includes columns for the Forex Pair, Volatility Percentage, Gain Percentage, and Loss Percentage. Color Coding : Volatility is displayed in a standard color for clear readability. Gain values are highlighted in green, and Loss values are highlighted in red, allowing for quick visual differentiation. Highlighting : Rows representing the pair with the highest gain and the pair with the most significant loss are especially highlighted for emphasis.
How to Use
Volatility Analysis : This metric gives insight into the average price range movements for each pair over the specified period and timeframe, helping you evaluate the potential for rapid price changes. Gain/Loss Tracking : Gain or loss percentages show the pair's recent performance, allowing you to observe whether a currency pair is trending positively or negatively over the chosen period. Comparative Pair Ranking : Use the table to identify pairs with the highest volatility and extremes in gain or loss to guide trading decisions based on market conditions.
Ideal For
Swing Traders and Day Traders looking to understand short-term market fluctuations in currency pairs. Risk Management : Helps traders gauge pairs with higher risk (volatility) and recent performance (gain/loss) for informed position sizing and risk control.
This indicator is a comprehensive tool for visualizing and analyzing key forex pairs, making it an essential addition for traders looking to stay updated on volatility trends and recent price changes.
Standard Deviation OscillatorStandard Deviation Oscillator (STDEV OSC) v1.1
Description
The Standard Deviation Oscillator transforms traditional volatility measurements into a dynamic oscillator that fluctuates between 0 and 100. This advanced technical analysis tool helps traders identify periods of extreme volatility and potential market turning points.
Features
Normalized volatility readings (0-100 scale)
Dynamic color changes based on volatility levels
Customizable overbought/oversold thresholds
Built-in alert conditions
Adaptive calculation using rolling windows
Clean, professional visualization
Indicator Parameters
Length: 20; Calculation period for standard deviation
Source: close; Price source for calculations
Overbought Level: 70; Upper threshold for high volatility
Oversold Level: 30; Lower threshold for low volatility
Visual Components
- Main Oscillator Line: Changes color based on current level
- Red: Above overbought level
- Green: Below oversold level
- Blue: Normal range
- Reference Lines:
- Overbought level (default: 70)
- Oversold level (default: 30)
- Middle line (50)
Alert Conditions
1. Volatility High Alert
- Triggers when oscillator crosses above the overbought level
- Useful for identifying potential market tops or breakout scenarios
2. Volatility Low Alert
- Triggers when oscillator crosses below the oversold level
- Helps identify potential market bottoms or consolidation periods
Risk Adjustment Tool
- Scale position sizes inversely to oscillator readings
- Reduce exposure during extremely high volatility periods
- Increase position sizes during normal volatility conditions
Best Practices
1. Timeframe Selection
- Best suited for 1H, 4H, and Daily charts
- Adjust length parameter based on timeframe
2. Confirmation
- Use in conjunction with trend indicators
- Confirm signals with price action patterns
- Consider overall market context
3. Parameter Optimization
- Backtest different length settings
- Adjust overbought/oversold levels based on asset
- Consider market conditions when setting alerts
Technical Notes
- Built in PineScript v5
- Optimized for TradingView platform
- Uses rolling window calculations for better adaptability
- Compatible with all trading instruments
- Minimal performance impact on charts
Version History
- v1.1: Added dynamic coloring, customizable levels, and alert conditions
- v1.0: Initial release with basic oscillator functionality
Disclaimer
This technical indicator is provided for educational and informational purposes only. Past performance is not indicative of future results. Always conduct thorough testing and use proper risk management techniques.
---
Tags: #TechnicalAnalysis #Volatility #Trading #Oscillator #TradingView #PineScript

VIX HeatmapVIX HeatMap
Instructions:
- To be used with the S&P500 index (ES, SPX, SPY, any S&P ETF) as that's the input from where the CBOE calculates and measures the VIX. Can also be used with the Dow Jones, Nasdaq, & Nasdaq100.
Description:
- Expected Implied Volatility regime simplified & visualized. Know if we are in a high, medium, or low volatility regime, instantly.
- Ranges from Hot to Cold: The hotter the heat-map, the higher the implied volatility and fear & vice versa.
- The VIX HeatMap, color-maps important VIX levels (7 in this case) in measuring volatility for day trading & swing trading.
Using the VIX HeatMap:
- A LOW level volatility environment: Represented by "cooler" colors (Blue & White) depicts that the level of volatility and fear is low. Percentage moves on the index level are going to be tame and less volatile more often than not. Low fear = low perceived risk.
- A MEDIUM level volatility environment: Represented by "warmer" colors (Green & Yellow) depicts that the markets are transitioning from a calmer period or from a more fearful period. Market volatility here will be higher and provide more volatile swings in price.
- A HIGH level volatility environment: Represented by "hotter" colors (Orange, Red, & Purple) depicts that the markets are very fearful at the moment and will have big swings in both directions. Historically, extreme VIX levels tend to coincide with bottoms but are in no way predictive of the exact timing as the volatile moves can continue for an extended period of time.
- Transitioning between the 7 VIX Zones: Each and every one of these specific VIX zone levels is important.
1. Extreme low: <16
2. Low: 16 to 20
3. Normal: 20 to 24
4. Medium: 24 to 28
5. Med-High: 28 to 32
6. High: 32 to 36
7. Extreme high: >36
- These VIX levels in particular measure volatility changes that have a major impact on switching between smaller time frames and measuring depths of a sell move and vice versa. Each level also behaves as its own support & resistance level in terms of taking a bit of effort to switch regimes, and aids in identifying and measuring the potential depth of pullbacks in bull markets and bounces in bear markets to reveal reversal points.
- Examples of VIX level supports depicted on the chart marked with arrows. From left to right:
1. March 10th: Markets jumped 2 volatility levels in 2 days. The fluctuations from blue to yellow to green where a sign that price action would reverse from the selloff.
2. March 28th: As soon as we move from green to the blue VIX level (<20), markets began to rally and only ended when the volatility level moved sub VIX 16 (white).
3. May 4th & 24th: Next we see the 2 dips where volatility levels went from blue to green (VIX > 20), marked bottoms and reversed higher.
4. June 1st: We see a change in VIX regime yet again into lower VIX level and markets rocket higher.
Knowing the current VIX regime is a very important tool and aid in trading, now easily visualized.

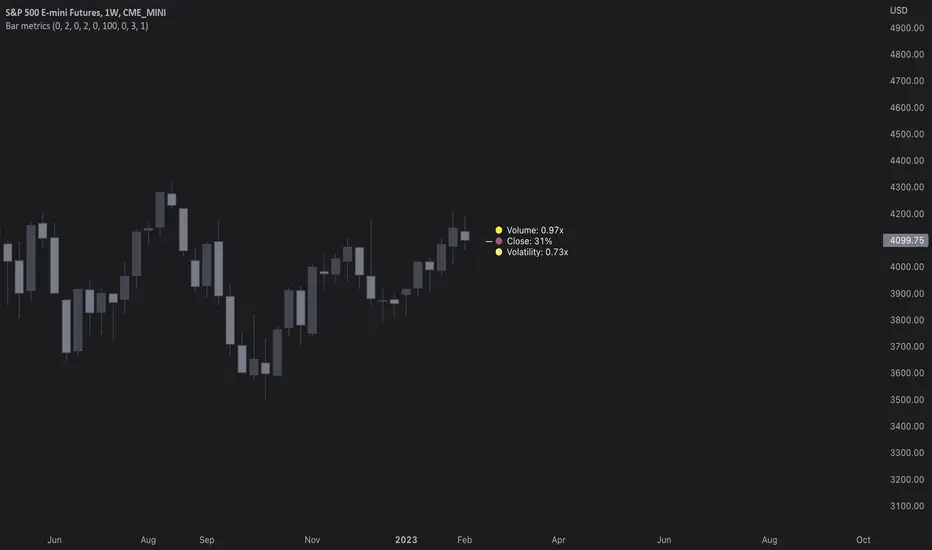
Bar metrics / quantifytools— Overview
Rather than eyeball evaluating bullishness/bearishness in any given bar, bar metrics allow a quantified approach using three basic fundamental data points: relative close, relative volatility and relative volume. These data points are visualized in a discreet data dashboard form, next to all real-time bars. Each value also has a dot in front, representing color coded extremes in the values.
Relative close represents position of bar's close relative to high and low, high of bar being 100% and low of bar being 0%. Relative close indicates strength of bulls/bears in a given bar, the higher the better for bulls, the lower the better for bears. Relative volatility (bar range, high - low) and relative volume are presented in a form of a multiplier, relative to their respective moving averages (SMA 20). A value of 1x indicates volume/volatility being on par with moving average, 2x indicates volume/volatility being twice as much as moving average and so on. Relative volume and volatility can be used for measuring general market participant interest, the "weight of the bar" as it were.
— Features
Users can gauge past bar metrics using lookback via input menu. Past bars, especially recent ones, are helpful for giving context for current bar metrics. Lookback bars are highlighted on the chart using a yellow box and metrics presented on the data dashboard with lookback symbols:
To inspect bar metric data and its implications, users can highlight bars with specified bracket values for each metric:
When bar highlighter is toggled on and desired bar metric values set, alert for the specified combination can be toggled on via alert menu. Note that bar highlighter must be enabled in order for alerts to function.
— Visuals
Bar metric dots are gradient colored the following way:
Relative volatility & volume
0x -> 1x / Neutral (white) -> Light (yellow)
1x -> 1.7x / Light (yellow) -> Medium (orange)
1.7x -> 2.4x / Medium (orange) -> Heavy (red)
Relative close
0% -> 25% / Heavy bearish (red) -> Light bearish (dark red)
25% -> 45% / Light bearish (dark red) -> Neutral (white)
45% - 55% / Neutral (white)
55% -> 75% / Neutral (white) -> Light bullish (dark green)
75% -> 100% / Light bullish (dark green) -> Heavy bullish (green)
All colors can be adjusted via input menu. Label size, label distance from bar (offset) and text format (regular/stealth) can be adjusted via input menu as well:
— Practical guide
As interpretation of bar metrics is highly contextual, it is especially important to use other means in conjunction with the metrics. Levels, oscillators, moving averages, whatever you have found useful for your process. In short, relative close indicates directional bias and relative volume/volatility indicates "weight" of directional bias.
General interpretation
High relative close, low relative volume/volatility = mildly bullish, bias up/consolidation
High relative close, medium relative volume/volatility = bullish, bias up
High relative close, high relative volume/volatility = exuberantly bullish, bias up/down depending on context
Medium relative close, low relative volume/volatility = noise, no bias
Medium relative close, medium to high relative volume/volatility = indecision, further evidence needed to evaluate bias
Low relative close, low relative volume/volatility = mildly bearish, bias down/consolidation
Low relative close, medium relative volume/volatility = bearish, bias down
Low relative close, high relative volume/volatility = exuberantly bearish, bias down/up depending on context
Nuances & considerations
As to relative close, it's important to note that each bar is a trading range when viewed on a lower timeframe, ES 1W vs. ES 4H:
When relative close is high, bulls were able to push price to range high by the time of close. When relative close is low, bears were able to push price to range low by the time of close. In other words, bulls/bears were able to gain the upper hand over a given trading range, hinting strength for the side that made the final push. When relative close is around middle range (40-60%), it can be said neither side is clearly dominating the range, hinting neutral/indecision bias from a relative close perspective.
As to relative volume/volatility, low values (less than ~0.7x) imply bar has low market participant interest and therefore is likely insignificant, as it is "lacking weight". Values close to or above 1x imply meaningful market participant interest, whereas values well above 1x (greater than ~1.3x) imply exuberance. This exuberance can manifest as initiation (beginning of a trend) or as exhaustion (end of a trend):