Live Economic Calendar by toodegrees⚠️ PLEASE READ ⚠️
Although this indicator is accurate in showcasing live and upcoming News Events, checking the original sources is always suggested. This indicator aims to save Time, but due to limitations it may not be 100% correct 100% of the Time.
Description:
The Live Economic Calendar indicator seamlessly integrates with external news sources to provide real-Time, upcoming, and past financial news directly on your Tradingview chart.
By having a clear understanding of when news are planned to be released, as well as their respective impact, analysts can prepare their weeks and days in advance. These injections of volatility can be harnessed by analysts to support their thesis, or may want to be avoided to ensure higher probability market conditions. Fundamentals and news releases transcend the boundaries of technical analysis, as their effects are difficult to predict or estimate.
Designed for both novice and experienced traders, the Live Economic Calendar indicator enhances your analysis by keeping you informed of the latest and upcoming market-moving news.
This is achieved with three different visual components:
News Table: A dedicated News Table shows the Day of the Week, Date, Time of the Day, Currency, Expected Impact, and News Name for each event (in chronological order). Once a news event has occurred, or the day is over, it will be greyed out – helping to focus on the next upcoming news events.
News Lines: Vertical lines plotted in the future help analysts monitor upcoming news events; vertical lines in the past help analysts spot and backtest previous news events that already occurred.
News Labels: Color-coded news labels will plot once the news events have occurred. This not only gives analysts a minimalistic visual cue, but also retains the information of which news were released at that Time in their tooltips.
Forex Factory Calendar News Feed:
The Forex Factory Data Feed includes news events from January 2007 to the present. The data is updated daily. Please see the Technical Description below for more information.
Forex Factory provides news for all major currencies and markets:
Australia (AUD)
Canada (CAD)
Switzerland (CHF)
China (CNY)
European Union (EUR)
United Kingdom (GBP)
Japan (JPY)
New Zealand (NZD)
United States of America (USD)
Further, there are four types of news impact, defined by respective color-coding which is retained to avoid confusion:
⚪ Holiday
🟡 Low Impact
🟠 Medium Impact
🔴 High Impact
News' Time of the day data is in 24H format, and 'All Day' news are marked at Daily candle open.
⚠️ Original Release Notes ⚠️
The original release of this indicator supports the Forex Factory News Calendar in EST (New York Time). Future updates will include multiple news sources, as well as supporting different Timezones.
Given Data limitations, the Daily chart can omit some data due to the market being close on some days. This will be fixed in the future once an efficient solution is implemented.
Key Features:
Impact-Based News Filtering: Filter news items based on their expected impact (holiday, low, medium, high) to focus on the most market-critical information.
Symbol-Specific News: Automatically filter news to display only what's relevant to the currency pair or trading symbol you are analyzing.
Custom Currency News: Want to see more than the news relevant to the current symbol? Toggle which markets' news you are most interested in.
Chart History: Keep your charts clean by displaying only the drawings of Today's news, or This Week's news.
Custom Lookback: Look further back in Time by choosing a custom number of Lookback Days, allowing you to backtest and keep in mind salient news events from the past.
Line and Label Customization: Both the News Lines and Labels are highly customizable (except the colors), allowing you to make the indicator yours.
Table History: Choose whether to focus on Today's news only, or the news for This Week.
Table Customization: The table colors and position are highly customizable, allowing you to make it fit your visual preference and your layouts' aesthetic.
"Wondering how it's done? 👇"
Technical Description:
This script utilizes Pine Seeds , a service integrated with TradingView for importing custom data. This stunning feature enables users to upload and access custom End Of Day (EOD) data, which can be updated as frequently as five times daily.
This data can be imported in one of two formats:
Single Value: integer or float
Candle Data: open, high, low, close, volume
Upon encountering Pine Seeds, I recognized its potential for importing financial news events. Given that Forex Factory is a primary source of financial news in my personal analysis, integrating it into my layouts seemed like an exciting opportunity. This integration is expected to provide significant value to users looking to integrate additional news feeds all in one place.
Development Challenges:
Format Limitations: News events must be converted into numerical values for import, due to the required Pine Seeds format.
Amount of Data: With all currencies considered, the system may encounter over 40 news events in a single day.
Data Availability: The reliance on End Of Day (EOD) data means that information for the current day is displayed with a delay, and accessing future data is not possible.
Solutions:
Encoding: Each news event is encoded as an integer in the "DCHHMMITYP" format.
D = day of the week
C = currency
HHMM = Time of day
I = news impact
TYP = event ID (see Event Library A and Event Library B )
To ensure data assignment for each candle across the open, high, low, close, and volume series, the value "999" is used as a placeholder:
Importing: Utilizing the encoding system, up to five news events per day can be imported for a singular Pine Seeds custom symbol.
By creating multiple custom Pine Seeds Symbols, efficient imports of a larger number of events is then easily achievable. Nine unique symbols have been established, accommodating up to 45 news events per day.
These symbols are searchable, and accessible as " TOODEGREES_FOREX_FACTORY_SLOT_N " where N ranges from 1 to 9.
The Pine Seeds data feed appears as follows:
Uploading Schedule: To ensure analysts are informed about current and upcoming week's news, events are uploaded one week in advance.
This approach is vital for preparing for potential market impacts across various asset classes and currencies, allowing visibility of an entire week's news ahead of Time.
Data Scraping:
Unfortunately Forex Factory doesn't offer an API to fetch their news feed.
Hence an ad hoc python scraper was developed to read and save news events from January 2007 till the present leveraging Selenium. The scraper algorithm is part of a larger script responsible for scraping data, formatting data, and creating all necessary datasets.
The pseudo-code for the python script is as follows:
Read and save news event data on Forex Factory
Format day of the week, currency, Time of the day, and impact data for the Encoding
Encode and save News Event IDs – Event ID dataset is created
Format news data for Pine Seeds (roll-back date by one week, assign news to open, high, low, close, and volume values)
Create Pine Seeds Datasets
This script is ran everyday at Futures market close (16:00 EST) to update the last part of the each dataset, ensuring accuracy, and taking into account last-minute news additions or revisions.
Once the data (next week's news) is imported by the Live Economic Calendar indicator, it's immediately decoded by leveraging the Forex Factory Decoding Library , and saved into an array.
Upon a new week open, the decoded data is used to plot news events on the chart and in the news table.
See the inner workings of these processes in the Forex Factory Utility Library .
Although these libraries are specifically built for this indicator, feel free to use them to create your own scripts. Looking forward to see what the Pine Script community comes up with!
Thank you for making it this far. Enjoy!
Ciao,
toodegrees
This tool is available ONLY on the TradingView platform.
Terms and Conditions
Our charting tools are provided for informational and educational purposes only and do not constitute financial, investment, or trading advice. Our charting tools are not designed to predict market movements or provide specific recommendations. Users should be aware that past performance is not indicative of future results and should not be relied upon for making financial decisions. By using our charting tools, the user agrees that Toodegrees and the Toodegrees Team are not responsible for any decisions made based on the information provided by these charting tools. The user assumes full responsibility and liability for any actions taken and the consequences thereof, including any loss of money or investments that may occur as a result of using these products. Hence, by using these charting tools, the user accepts and acknowledges that Toodegrees and the Toodegrees Team are not liable nor responsible for any unwanted outcome that arises from the development, or the use of these charting tools. Finally, the user indemnifies Toodegrees and the Toodegrees Team from any and all liability.
By continuing to use these charting tools, the user acknowledges and agrees to the Terms and Conditions outlined in this legal disclaimer.
Cari dalam skrip untuk "one一季度财报"

VIX Statistical Sentiment Index [Nasan]** THIS IS ONLY FOR US STOCK MARKET**
The indicator analyzes market sentiment by computing the Rate of Change (ROC) for the VIX and S&P 500, visualizing the data as histograms with conditional coloring. It measures the correlation between the VIX, the specific stock, and the S&P 500, displaying the results on the chart. The reliability measure combines these correlations, offering an overall assessment of data robustness. One can use this information to gauge the inverse relationship between VIX and S&P 500, the alignment of the specific stock with the market, and the overall reliability of the correlations for informed decision-making based on the inverse relationship of VIX and price movement.
**WHEN THE VIX ROC IS ABOVE ZERO (RED COLOR) AND RASING ONE CAN EXPECT THE PRICE TO MOVE DOWNWARDS, WHEN THE VIX ROC IS BELOW ZERO (GREEN)AND DECREASING ONE CAN EXPECT THE PRICE TO MOVE UPWARDS"
Understanding the VIX Concept:
The VIX, or Volatility Index, is a widely used indicator in finance that measures the market's expectation of volatility over the next 30 days. Here are key points about the VIX:
Fear Gauge:
Often referred to as the "fear gauge," the VIX tends to rise during periods of market uncertainty or fear and fall during calmer market conditions.
Inverse Relationship with Market:
The VIX typically has an inverse relationship with the stock market. When the stock market experiences a sell-off, the VIX tends to rise, indicating increased expected volatility.
Implied Volatility:
The VIX is derived from the prices of options on the S&P 500. It represents the market's expectations for future volatility and is often referred to as "implied volatility."
Contrarian Indicator:
Extremely high VIX levels may indicate oversold conditions, suggesting a potential market rebound. Conversely, very low VIX levels may signal complacency and a potential reversal.
VIX vs. SPX Correlation:
This correlation measures the strength and direction of the relationship between the VIX (Volatility Index) and the S&P 500 (SPX).
A negative correlation indicates an inverse relationship. When the VIX goes up, the SPX tends to go down, and vice versa.
The correlation value closer to -1 suggests a stronger inverse relationship between VIX and SPX.
Stock vs. SPX Correlation:
This correlation measures the strength and direction of the relationship between the closing price of the stock (retrieved using src1) and the S&P 500 (SPX).
This correlation helps assess how closely the stock's price movements align with the broader market represented by the S&P 500.
A positive correlation suggests that the stock tends to move in the same direction as the S&P 500, while a negative correlation indicates an opposite movement.
Reliability Measure:
Combines the squared values of the VIX vs. SPX and Stock vs. SPX correlations and takes the square root to create a reliability measure.
This measure provides an overall assessment of how reliable the correlation information is in guiding decision-making.
Interpretation:
A higher reliability measure implies that the correlations between VIX and SPX, as well as between the stock and SPX, are more robust and consistent.
One can use this reliability measure to gauge the confidence they can place in the correlations when making decisions about the specific stock based on VIX data and its correlation with the broader market.

Liquidity Price Depth Chart [LuxAlgo]The Liquidity Price Depth Chart is a unique indicator inspired by the visual representation of order book depth charts, highlighting sorted prices from bullish and bearish candles located on the chart's visible range, as well as their degree of liquidity.
Note that changing the chart's visible range will recalculate the indicator.
🔶 USAGE
The indicator can be used to visualize sorted bullish/bearish prices (in descending order), with bullish prices being highlighted on the left side of the chart, and bearish prices on the right. Prices are highlighted by dots, and connected by a line.
The displacement of a line relative to the x-axis is an indicator of liquidity, with a higher displacement highlighting prices with more volume.
These can also be easily identified by only keeping the dots, visible voids can be indicative of a price associated with significant volume or of a large price movement if the displacement is more visible for the price axis. These areas could play a key role in future trends.
Additionally, the location of the bullish/bearish prices with the highest volume is highlighted with dotted lines, with the returned horizontal lines being useful as potential support/resistances.
🔹 Liquidity Clusters
Clusters of liquidity can be spotted when the Liquidity Price Depth Chart exhibits more rectangular shapes rather than "V" shapes.
The steepest segments of the shape represent periods of non-stationarity/high volatility, while zones with clustered prices highlight zones of potential liquidity clusters, that is zones where traders accumulate positions.
🔹 Liquidity Sentiment
At the bottom of each area, a percentage can be visible. This percentage aims to indicate if the traded volume is more often associated with bullish or bearish price variations.
In the chart above we can see that bullish price variations make 63.89% of the total volume in the range visible range.
🔶 SETTINGS
🔹 Bullish Elements
Bullish Price Highest Volume Location: Shows the location of the bullish price variation with the highest associated volume using one horizontal and one vertical line.
Bullish Volume %: Displays the bullish volume percentage at the bottom of the depth chart.
🔹 Bearish Elements
Bearish Price Highest Volume Location: Shows the location of the bearish price variation with the highest associated volume using one horizontal and one vertical line.
Bearish Volume %: Displays the bearish volume percentage at the bottom of the depth chart.
🔹 Misc
Volume % Box Padding: Width of the volume % boxes at the bottom of the Liquidity Price Depth Chart as a percentage of the chart visible range

MACD_RSI_trend_followingINFO:
This indicator can be used to build-up a strategy for trading of assets which are currently in trending phase.
My preference is to use it on slowly moving assets like GOLD and on higher timeframes, but practice may show that we find more usefull cases.
This script uses two indicators - MACD and RSI, as the timeframe that those are extracted for is configurable (defaults with the Chart TF, but can be any other selected by the user).
The strategy has the following simple idea - buy if any if the conditions below is true:
The selected TF MACD line crosses above the signal line and the TF RSI is above the user selected trigger value
The selected TF MACD line is above the signal line and the TF RSI crosses above the user selected trigger value
Once we're in position we wait for the selected TF MACD line to cross below the signal line, and then we set a SL at the low of that bar
DETAILS and USAGE:
In the current implementation I find two possible use cases for the indicator:
as a stand-alone indicator on the chart which can also fire alerts that can help to determine if we want to manually enter/exit trades based on them
can be used to connect to the Signal input of the TTS (TempalteTradingStrategy) by jason5480 in order to backtest it, thus effectively turning it into a strategy (instructions below in TTS CONNECTIVITY section)
In the example below we see a position opened at the bar after the buy indicator from the script has been triggered, and then later after the SL indicator from the script has been triggered a SL has been set on the lower wick of the closing candle, and the position eventually got closed once the price hit that level. Note that most of the drawing on the example snapshot below are from the TTS indicator following the buy/sell/SL conditions themseves:
Trading period can be selected from the indicator itself to limit to more interesting periods.
Arrow indications are drawn on the chart to indicate the trading conditions met in the script - green arrow for a buy signal indication and orange for LTF crossunder to indicate setting of SL.
SETTINGS:
Leaving all of the settings as in vanilla use case, as both the MACD and RSI indicator's settings follow the default ones for the stand-alone indicators themselves.
The start-end date is a time filter that can be extermely usefull when backtesting different time periods.
Pesonal preference is using the script on a D/W timeframe, while the indicator is configured to use Monthly chart.
The default value of the RSI filter is left to 50, which can be changed. I.e. if the RSI is above 50 we have a regime filter based on the MACD criteria.
EXTERNAL LIBRARIES:
The script uses a couple of external libraries:
HeWhoMustNotBeNamed/enhanced_ta/14 - collection of TA indicators
jason5480/tts_convention/3 - more details about the Template Trading Strategy below
I would like to highly appreciate and credit the work of both HeWhoMustNotBeNamed and jason5480 for providing them to the community.
TTS SETTINGS (NEEDED IF USED TO BACKTEST WITH TTS):
The TempalteTradingStrategy is a strategy script developed in Pine by jason5480, which I recommend for quick turn-around of testing different ideas on a proven and tested framework
I cannot give enough credit to the developer for the efforts put in building of the infrastructure, so I advice everyone that wants to use it first to get familiar with the concept and by checking
by checking jason5480's profile www.tradingview.com
The TTS itself is extremely functional and have a lot of properties, so its functionality is beyond the scope of the current script -
Again, I strongly recommend to be thoroughly epxlored by everyone that plans on using it.
In the nutshell it is a script that can be feed with buy/sell signals from an external indicator script and based on many configuration options it can determine how to execute the trades.
The TTS has many settings that can be applied, so below I will cover only the ones that differ from the default ones, at least according to my testing - do your own research, you may find something even better :)
The current/latest version that I've been using as of writing and testing this script is TTSv48
Settings which differ from the default ones:
from - False (time filter is from the indicator script itself)
Deal Conditions Mode - External (take enter/exit conditions from an external script)
🔌Signal 🛈➡ - MACD_RSI_trend_following: 🔌Signal to TTSv48 (this is the output from the indicator script, according to the TTS convention)
Sat/Sun - true (for crypto, in order to trade 24/7)
Order Type - STOP (perform stop order)
Distance Method - HHLL (HigherHighLowerLow - in order to set the SL according to the strategy definition from above)
The next are just personal preferenes, you can feel free to experiment according to your trading style
Take Profit Targets - 0 (either 100% in or out, no incremental stepping in or out of positions)
Dist Mul|Len Long/Short- 10 (make sure that we don't close on profitable trades by any reason)
Quantity Method - EQUITY (personal backtesting preference is to consider each backtest as a separate portfolio, so determine the position size by 100% of the allocated equity size)
Equity % - 100 (note above)

A_Traders_Edge__LibraryLibrary "A_Traders_Edge__Library"
- A Trader's Edge (ATE)_Library was created to assist in constructing Market Overview Scanners (MOS)
LabelLocation(_firstLocation)
This function is used when there's a desire to print an assets ALERT LABELS at a set location on the scale that will
NOT change throughout the progression of the script. This is created so that if a lot of alerts are triggered, they
will stay relatively visible and not overlap each other. Ex. If you set your '_firstLocation' parameter as 1, since
there are a max of 40 assets that can be scanned, the 1st asset's location is assigned the value in the '_firstLocation' parameter,
the 2nd asset's location is the (1st asset's location+1)...and so on. If your first location is set to 81 then
the 1st asset is 81 and 2nd is 82 and so on until the 40th location = 120(in this particular example).
Parameters:
_firstLocation (simple int) : (simple int)
Optional(starts at 1 if no parameter added).
Location that you want the first asset to print its label if is triggered to do so.
ie. loc2=loc1+1, loc3=loc2+1, etc.
Returns: Returns 40 output variables each being a different location to print the labels so that an asset is asssigned to
a particular location on the scale. Regardless of if you have the maximum amount of assets being screened (40 max), this
function will output 40 locations… So there needs to be 40 variables assigned in the tuple in this function. What I
mean by that is you need to have 40 output location variables within your tuple (ie. between the ' ') regarless of
if your scanning 40 assets or not. If you only have 20 assets in your scripts input settings, then only the first 20
variables within the ' ' Will be assigned to a value location and the other 20 will be assigned 'NA', but their
variables still need to be present in the tuple.
SeparateTickerids(_string)
You must form this single tickerID input string exactly as described in the scripts info panel (little gray 'i' that
is circled at the end of the settings in the settings/input panel that you can hover your cursor over this 'i' to read the
details of that particular input). IF the string is formed correctly then it will break up this single string parameter into
a total of 40 separate strings which will be all of the tickerIDs that the script is using in your MO scanner.
Parameters:
_string (simple string) : (string)
A maximum of 40 Tickers (ALL joined as 1 string for the input parameter) that is formulated EXACTLY as described
within the tooltips of the TickerID inputs in my MOS Scanner scripts:
assets = input.text_area(tIDset1, title="TickerID (MUST READ TOOLTIP)", tooltip="Accepts 40 TICKERID's for each
copy of the script on the chart. TEXT FORMATTING RULES FOR TICKERID'S:
(1) To exclude the EXCHANGE NAME in the Labels, de-select the next input option.
(2) MUST have a space (' ') AFTER each TickerID.
(3) Capitalization in the Labels will match cap of these TickerID's.
(4) If your asset has a BaseCurrency & QuoteCurrency (ie. ADAUSDT ) BUT you ONLY want Labels
to show BaseCurrency(ie.'ADA'), include a FORWARD SLASH ('/') between the Base & Quote (ie.'ADA/USDT')", display=display.none)
Returns: Returns 40 output variables of the different strings of TickerID's (ie. you need to output 40 variables within the
tuple ' ' regardless of if you were scanning using all possible (40) assets or not.
If your scanning for less than 40 assets, then once the variables are assigned to all of the tickerIDs, the rest
of the 40 variables in the tuple will be assigned "NA".
TickeridForLabelsAndSecurity(_includeExchange, _ticker)
This function accepts the TickerID Name as its parameter and produces a single string that will be used in all of your labels.
Parameters:
_includeExchange (simple bool) : (bool)
Optional(if parameter not included in function it defaults to false ).
Used to determine if the Exchange name will be included in all labels/triggers/alerts.
_ticker (simple string) : (string)
For this parameter, input the varible named '_coin' from your 'f_main()' function for this parameter. It is the raw
Ticker ID name that will be processed.
Returns: ( )
Returns 2 output variables:
1st ('_securityTickerid') is to be used in the 'request.security()' function as this string will contain everything
TV needs to pull the correct assets data.
2nd ('lblTicker') is to be used in all of the labels in your MOS as it will only contain what you want your labels
to show as determined by how the tickerID is formulated in the MOS's input.
InvalidTID(_tablePosition, _stackVertical, _close, _securityTickerid, _invalidArray)
This is to add a table in the middle right of your chart that prints all the TickerID's that were either not formulated
correctly in the '_source' input or that is not a valid symbol and should be changed.
Parameters:
_tablePosition (simple string) : (string)
Optional(if parameter not included, it defaults to position.middle_right). Location on the chart you want the table printed.
Possible strings include: position.top_center, position.top_left, position.top_right, position.middle_center,
position.middle_left, position.middle_right, position.bottom_center, position.bottom_left, position.bottom_right.
_stackVertical (simple bool) : (bool)
Optional(if parameter not included, it defaults to true). All of the assets that are counted as INVALID will be
created in a list. If you want this list to be prited as a column then input 'true' here.
_close (float) : (float)
If you want them printed as a single row then input 'false' here.
This should be the closing value of each of the assets being tested to determine in the TickerID is valid or not.
_securityTickerid (string) : (string)
Throughout the entire charts updates, if a '_close' value is never regestered then the logic counts the asset as INVALID.
This will be the 1st TickerID varible (named _securityTickerid) outputted from the tuple of the TickeridForLabels()
function above this one.
_invalidArray (string ) : (array string)
Input the array from the original script that houses all of the invalidArray strings.
Returns: (na)
Returns a table with the screened assets Invalid TickerID's. Table draws automatically if any are Invalid, thus,
no output variable to deal with.
LabelSizes(_barCnt, _lblSzRfrnce)
This function sizes your Alert Trigger Labels according to the amount of Printed Bars the chart has printed within
a set time period, while also keeping in mind the smallest relative reference size you input in the 'lblSzRfrnceInput'
parameter of this function. A HIGHER % of Printed Bars(aka...more trades occurring for that asset on the exchange),
the LARGER the Name Label will print, potentially showing you the better opportunities on the exchange to avoid
exchange manipulation liquidations.
*** SHOULD NOT be used as size of labels that are your asset Name Labels next to each asset's Line Plot...
if your MOS includes these as you want these to be the same size for every asset so the larger ones dont cover the
smaller ones if the plots are all close to each other ***
Parameters:
_barCnt (float) : (float)
Get the 1st variable('barCnt') from the 'PrintedBarCount' function's tuple and input it as this functions 1st input
parameter which will directly affect the size of the 2nd output variable ('alertTrigLabel') outputted by this function.
_lblSzRfrnce (string) : (string)
Optional(if parameter not included, it defaults to size.small). This will be the size of the 1st variable outputted
by this function ('assetNameLabel') BUT also affects the 2nd variable outputted by this function.
Returns: ( )
Returns 2 variables:
1st output variable ('AssetNameLabel') is assigned to the size of the 'lblSzRfrnceInput' parameter.
2nd output variable('alertTrigLabel') can be of variying sizes depending on the 'barCnt' parameter...BUT the smallest
size possible for the 2nd output variable ('alertTrigLabel') will be the size set in the 'lblSzRfrnceInput' parameter.
AssetColor()
This function is used to assign 40 different colors to 40 variables to be used for the different labels/plots.
Returns: Returns 40 output variables each with a different color assigned to them to be used in your plots & labels.
Regardless of if you have the maximum amount of assets your scanning(40 max) or less,
this function will assign 40 colors to 40 variables that you have between the ' '.
PrintedBarCount(_time, _barCntLength, _barCntPercentMin)
The Printed BarCount Filter looks back a User Defined amount of minutes and calculates the % of bars that have printed
out of the TOTAL amount of bars that COULD HAVE been printed within the same amount of time.
Parameters:
_time (int) : (int)
The time associated with the chart of the particular asset that is being screened at that point.
_barCntLength (int) : (int)
The amount of time (IN MINUTES) that you want the logic to look back at to calculate the % of bars that have actually
printed in the span of time you input into this parameter.
_barCntPercentMin (int) : (int)
The minimum % of Printed Bars of the asset being screened has to be GREATER than the value set in this parameter
for the output variable 'bc_gtg' to be true.
Returns: ( )
Returns 2 outputs:
1st is the % of Printed Bars that have printed within the within the span of time you input in the '_barCntLength' parameter.
2nd is true/false according to if the Printed BarCount % is above the threshold that you input into the '_barCntPercentMin' parameter.
RCI(_rciLength, _source, _interval)
You will see me using this a lot. DEFINITELY my favorite oscillator to utilize for SO many different things from
timing entries/exits to determining trends.Calculation of this indicator based on Spearmans Correlation.
Parameters:
_rciLength (int) : (int)
Amount of bars back to use in RCI calculations.
_source (float) : (float)
Source to use in RCI calculations (can use ANY source series. Ie, open,close,high,low,etc).
_interval (int) : (int)
Optional(if parameter not included, it defaults to 3). RCI calculation groups bars by this amount and then will.
rank these groups of bars.
Returns: (float)
Returns a single RCI value that will oscillates between -100 and +100.
RCIAVG(firstLength, _amtBtLengths, _rciSMAlen, _source, _interval)
20 RCI's are averaged together to get this RCI Avg (Rank Correlation Index Average). Each RCI (of the 20 total RCI)
has a progressively LARGER Lookback Length. Though the RCI Lengths are not individually adjustable,
there are 2 factors that ARE:
(1) the Lookback Length of the 1st RCI and
(2) the amount of values between one RCI's Lookback Length and the next.
*** If you set 'firstLength' to it's default of 200 and '_amtBtLengths' to it's default of 120 (aka AMOUNT BETWEEN LENGTHS=120)...
then RCI_2 Length=320, RCI_3 Length=440, RCI_4 Length=560, and so on.
Parameters:
firstLength (int) : (int)
Optional(if parameter is not included when the function is called, then it defaults to 200).
This parameter is the Lookback Length for the 1st RCI used in the RCI Avg.
_amtBtLengths (int) : (int)
Optional(if parameter not included when the function is called, then it defaults to 120).
This parameter is the value amount between each of the progressively larger lengths used for the 20 RCI's that
are averaged in the RCI Avg.
***** BEWARE ***** Too large of a value here will cause the calc to look back too far, causing an error(thus the value must be lowered)
_rciSMAlen (int) : (int)
Unlike the Single RCI Function, this function smooths out the end result using an SMA with a length value that is this parameter.
_source (float) : (float)
Source to use in RCI calculations (can use ANY source series. Ie, open,close,high,low,etc).
_interval (int) : (int)
Optional(if parameter not included, it defaults to 3). Within the RCI calculation, bars next to each other are grouped together
and then these groups are Ranked against each other. This parameter is the number of adjacent bars that are grouped together.
Returns: (float)
Returns a single RCI value that is the Avg of many RCI values that will oscillate between -100 and +100.
PercentChange(_startingValue, _endingValue)
This is a quick function to calculate how much % change has occurred between the '_startingValue' and the '_endingValue'
that you input into the function.
Parameters:
_startingValue (float) : (float)
The source value to START the % change calculation from.
_endingValue (float) : (float)
The source value to END the % change caluclation from.
Returns: Returns a single output being the % value between 0-100 (with trailing numbers behind a decimal). If you want only
a certain amount of numbers behind the decimal, this function needs to be put within a formatting function to do so.
Rescale(_source, _oldMin, _oldMax, _newMin, _newMax)
Rescales series with a known '_oldMin' & '_oldMax'. Use this when the scale of the '_source' to
rescale is known (bounded).
Parameters:
_source (float) : (float)
Source to be normalized.
_oldMin (int) : (float)
The known minimum of the '_source'.
_oldMax (int) : (float)
The known maximum of the '_source'.
_newMin (int) : (float)
What you want the NEW minimum of the '_source' to be.
_newMax (int) : (float)
What you want the NEW maximum of the '_source' to be.
Returns: Outputs your previously bounded '_source', but now the value will only move between the '_newMin' and '_newMax'
values you set in the variables.
Normalize_Historical(_source, _minimumLvl, _maximumLvl)
Normalizes '_source' that has a previously unknown min/max(unbounded) determining the max & min of the '_source'
FROM THE ENTIRE CHARTS HISTORY. ]
Parameters:
_source (float) : (float)
Source to be normalized.
_minimumLvl (int) : (float)
The Lower Boundary Level.
_maximumLvl (int) : (float)
The Upper Boundary Level.
Returns: Returns your same '_source', but now the value will MOSTLY stay between the minimum and maximum values you set in the
'_minimumLvl' and '_maximumLvl' variables (ie. if the source you input is an RSI...the output is the same RSI value but
instead of moving between 0-100 it will move between the maxand min you set).
Normailize_Local(_source, _length, _minimumLvl, _maximumLvl)
Normalizes series with previously unknown min/max(unbounded). Much like the Normalize_Historical function above this one,
but rather than using the Highest/Lowest Values within the ENTIRE charts history, this on looks for the Highest/Lowest
values of '_source' within the last ___ bars (set by user as/in the '_length' parameter. ]
Parameters:
_source (float) : (float)
Source to be normalized.
_length (int) : (float)
The amount of bars to look back to determine the highest/lowest '_source' value.
_minimumLvl (int) : (float)
The Lower Boundary Level.
_maximumLvl (int) : (float)
The Upper Boundary Level.
Returns: Returns a single output variable being the previously unbounded '_source' that is now normalized and bound between
the values used for '_minimumLvl'/'_maximumLvl' of the '_source' within the user defined lookback period.
UtilsLibrary "Utils"
A collection of convenience and helper functions for indicator and library authors on TradingView
formatNumber(num)
My version of format number that doesn't have so many decimal places...
Parameters:
num (float) : (float) the number to be formatted
Returns: (string) The formatted number
getDateString(timestamp)
Convenience function returns timestamp in yyyy/MM/dd format.
Parameters:
timestamp (int) : (int) The timestamp to stringify
Returns: (int) The date string
getDateTimeString(timestamp)
Convenience function returns timestamp in yyyy/MM/dd hh:mm format.
Parameters:
timestamp (int) : (int) The timestamp to stringify
Returns: (int) The date string
getInsideBarCount()
Gets the number of inside bars for the current chart. Can also be passed to request.security to get the same for different timeframes.
Returns: (int) The # of inside bars on the chart right now.
getLabelStyleFromString(styleString, acceptGivenIfNoMatch)
Tradingview doesn't give you a nice way to put the label styles into a dropdown for configuration settings. So, I specify them in the following format: . This function takes care of converting those custom strings back to the ones expected by tradingview scripts.
Parameters:
styleString (string)
acceptGivenIfNoMatch (bool) : (bool) If no match for styleString is found and this is true, the function will return styleString, otherwise it will return tradingview's preferred default
Returns: (string) The string expected by tradingview functions
getTime(hourNumber, minuteNumber)
Given an hour number and minute number, adds them together and returns the sum. To be used by getLevelBetweenTimes when fetching specific price levels during a time window on the day.
Parameters:
hourNumber (int) : (int) The hour number
minuteNumber (int) : (int) The minute number
Returns: (int) The sum of all the minutes
getHighAndLowBetweenTimes(start, end)
Given a start and end time, returns the high or low price during that time window.
Parameters:
start (int) : The timestamp to start with (# of seconds)
end (int) : The timestamp to end with (# of seconds)
Returns: (float) The high or low value
getPremarketHighsAndLows()
Returns an expression that can be used by request.security to fetch the premarket high & low levels in a tuple.
Returns: (tuple)
getAfterHoursHighsAndLows()
Returns an expression that can be used by request.security to fetch the after hours high & low levels in a tuple.
Returns: (tuple)
getOvernightHighsAndLows()
Returns an expression that can be used by request.security to fetch the overnight high & low levels in a tuple.
Returns: (tuple)
getNonRthHighsAndLows()
Returns an expression that can be used by request.security to fetch the high & low levels for premarket, after hours and overnight in a tuple.
Returns: (tuple)
getLineStyleFromString(styleString, acceptGivenIfNoMatch)
Tradingview doesn't give you a nice way to put the line styles into a dropdown for configuration settings. So, I specify them in the following format: . This function takes care of converting those custom strings back to the ones expected by tradingview scripts.
Parameters:
styleString (string) : (string) Plain english (or TV Standard) version of the style string
acceptGivenIfNoMatch (bool) : (bool) If no match for styleString is found and this is true, the function will return styleString, otherwise it will return tradingview's preferred default
Returns: (string) The string expected by tradingview functions
getPercentFromPrice(price)
Get the % the current price is away from the given price.
Parameters:
price (float)
Returns: (float) The % the current price is away from the given price.
getPositionFromString(position)
Tradingview doesn't give you a nice way to put the positions into a dropdown for configuration settings. So, I specify them in the following format: . This function takes care of converting those custom strings back to the ones expected by tradingview scripts.
Parameters:
position (string) : (string) Plain english position string
Returns: (string) The string expected by tradingview functions
getTimeframeOfChart()
Get the timeframe of the current chart for display
Returns: (string) The string of the current chart timeframe
getTimeNowPlusOffset(candleOffset)
Helper function for drawings that use xloc.bar_time to help you know the time offset if you want to place the end of the drawing out into the future. This determines the time-size of one candle and then returns a time n candleOffsets into the future.
Parameters:
candleOffset (int) : (int) The number of items to find singular/plural for.
Returns: (int) The future time
getVolumeBetweenTimes(start, end)
Given a start and end time, returns the sum of all volume across bars during that time window.
Parameters:
start (int) : The timestamp to start with (# of seconds)
end (int) : The timestamp to end with (# of seconds)
Returns: (float) The volume
isToday()
Returns true if the current bar occurs on today's date.
Returns: (bool) True if current bar is today
padLabelString(labelText, labelStyle)
Pads a label string so that it appears properly in or not in a label. When label.style_none is used, this will make sure it is left-aligned instead of center-aligned. When any other type is used, it adds a single space to the right so there is padding against the right end of the label.
Parameters:
labelText (string) : (string) The string to be padded
labelStyle (string) : (string) The style of the label being padded for.
Returns: (string) The padded string
plural(num, singular, plural)
Helps format a string for plural/singular. By default, if you only provide num, it will just return "s" for plural and nothing for singular (eg. plural(numberOfCats)). But you can optionally specify the full singular/plural words for more complicated nomenclature (eg. plural(numberOfBenches, 'bench', 'benches'))
Parameters:
num (int) : (int) The number of items to find singular/plural for.
singular (string) : (string) The string to return if num is singular. Defaults to an empty string.
plural (string) : (string) The string to return if num is plural. Defaults to 's' so you can just add 's' to the end of a word.
Returns: (string) The singular or plural provided strings depending on the num provided.
timeframeInSeconds(timeframe)
Get the # of seconds in a given timeframe. Tradingview's timeframe.in_seconds() expects a simple string, and we often need to use series string, so this is an alternative to get you the value you need.
Parameters:
timeframe (string)
Returns: (int) The number of secondsof that timeframe
timeframeToString(tf)
Convert a timeframe string to a consistent standard.
Parameters:
tf (string) : (string) The timeframe string to convert
Returns: (string) The standard format for the string, or the unchanged value if it is unknown.

Volume and Price Z-Score [Multi-Asset] - By LeviathanThis script offers in-depth Z-Score analytics on price and volume for 200 symbols. Utilizing visualizations such as scatter plots, histograms, and heatmaps, it enables traders to uncover potential trade opportunities, discern market dynamics, pinpoint outliers, delve into the relationship between price and volume, and much more.
A Z-Score is a statistical measurement indicating the number of standard deviations a data point deviates from the dataset's mean. Essentially, it provides insight into a value's relative position within a group of values (mean).
- A Z-Score of zero means the data point is exactly at the mean.
- A positive Z-Score indicates the data point is above the mean.
- A negative Z-Score indicates the data point is below the mean.
For instance, a Z-Score of 1 indicates that the data point is 1 standard deviation above the mean, while a Z-Score of -1 indicates that the data point is 1 standard deviation below the mean. In simple terms, the more extreme the Z-Score of a data point, the more “unusual” it is within a larger context.
If data is normally distributed, the following properties can be observed:
- About 68% of the data will lie within ±1 standard deviation (z-score between -1 and 1).
- About 95% will lie within ±2 standard deviations (z-score between -2 and 2).
- About 99.7% will lie within ±3 standard deviations (z-score between -3 and 3).
Datasets like price and volume (in this context) are most often not normally distributed. While the interpretation in terms of percentage of data lying within certain ranges of z-scores (like the ones mentioned above) won't hold, the z-score can still be a useful measure of how "unusual" a data point is relative to the mean.
The aim of this indicator is to offer a unique way of screening the market for trading opportunities by conveniently visualizing where current volume and price activity stands in relation to the average. It also offers features to observe the convergent/divergent relationships between asset’s price movement and volume, observe a single symbol’s activity compared to the wider market activity and much more.
Here is an overview of a few important settings.
Z-SCORE TYPE
◽️ Z-Score Type: Current Z-Score
Calculates the z-score by comparing current bar’s price and volume data to the mean (moving average with any custom length, default is 20 bars). This indicates how much the current bar’s price and volume data deviates from the average over the specified period. A positive z-score suggests that the current bar's price or volume is above the mean of the last 20 bars (or the custom length set by the user), while a negative z-score means it's below that mean.
Example: Consider an asset whose current price and volume both show deviations from their 20-bar averages. If the price's Z-Score is +1.5 and the volume's Z-Score is +2.0, it means the asset's price is 1.5 standard deviations above its average, and its trading volume is 2 standard deviations above its average. This might suggest a significant upward move with strong trading activity.
◽️ Z-Score Type: Average Z-Score
Calculates the custom-length average of symbol's z-score. Think of it as a smoothed version of the Current Z-Score. Instead of just looking at the z-score calculated on the latest bar, it considers the average behavior over the last few bars. By doing this, it helps reduce sudden jumps and gives a clearer, steadier view of the market.
Example: Instead of a single bar, imagine the average price and volume of an asset over the last 5 bars. If the price's 5-bar average Z-Score is +1.0 and the volume's is +1.5, it tells us that, over these recent bars, both the price and volume have been consistently above their longer-term averages, indicating sustained increase.
◽️ Z-Score Type: Relative Z-Score
Calculates a relative z-score by comparing symbol’s current bar z-score to the mean (average z-score of all symbols in the group). This is essentially a z-score of a z-score, and it helps in understanding how a particular symbol's activity stands out not just in its own historical context, but also in relation to the broader set of symbols being analyzed. In other words, while the primary z-score tells you how unusual a bar's activity is for that specific symbol, the relative z-score informs you how that "unusualness" ranks when compared to the entire group's deviations. This can be particularly useful in identifying symbols that are outliers even among outliers, indicating exceptionally unique behaviors or opportunities.
Example: If one asset's price Z-Score is +2.5 and volume Z-Score is +3.0, but the group's average Z-Scores are +0.5 for price and +1.0 for volume, this asset’s Relative Z-Score would be high and therefore stand out. This means that asset's price and volume activities are notably high, not just by its own standards, but also when compared to other symbols in the group.
DISPLAY TYPE
◽️ Display Type: Scatter Plot
The Scatter Plot is a visual tool designed to represent values for two variables, in this case the Z-Scores of price and volume for multiple symbols. Each symbol has it's own dot with x and y coordinates:
X-Axis: Represents the Z-Score of price. A symbol further to the right indicates a higher positive deviation in its price from its average, while a symbol to the left indicates a negative deviation.
Y-Axis: Represents the Z-Score of volume. A symbol positioned higher up on the plot suggests a higher positive deviation in its trading volume from its average, while one lower down indicates a negative deviation.
Here are some guideline insights of plot positioning:
- Top-Right Quadrant (High Volume-High Price): Symbols in this quadrant indicate a scenario where both the trading volume and price are higher than their respective mean.
- Top-Left Quadrant (High Volume-Low Price): Symbols here reflect high trading volumes but prices lower than the mean.
- Bottom-Left Quadrant (Low Volume-Low Price): Assets in this quadrant have both low trading volume and price compared to their mean.
- Bottom-Right Quadrant (Low Volume-High Price): Symbols positioned here have prices that are higher than their mean, but the trading volume is low compared to the mean.
The plot also integrates a set of concentric squares which serve as visual guides:
- 1st Square (1SD): Encapsulates symbols that have Z-Scores within ±1 standard deviation for both price and volume. Symbols within this square are typically considered to be displaying normal behavior or within expected range.
- 2nd Square (2SD): Encapsulates those with Z-Scores within ±2 standard deviations. Symbols within this boundary, but outside the 1 SD square, indicate a moderate deviation from the norm.
- 3rd Square (3SD): Represents symbols with Z-Scores within ±3 standard deviations. Any symbol outside this square is deemed to be a significant outlier, exhibiting extreme behavior in terms of either its price, its volume, or both.
By assessing the position of symbols relative to these squares, traders can swiftly identify which assets are behaving typically and which are showing unusual activity. This visualization simplifies the process of spotting potential outliers or unique trading opportunities within the market. The farther a symbol is from the center, the more it deviates from its typical behavior.
◽️ Display Type: Columns
In this visualization, z-scores are represented using columns, where each symbol is presented horizontally. Each symbol has two distinct nodes:
- Left Node: Represents the z-score of volume.
- Right Node: Represents the z-score of price.
The height of these nodes can vary along the y-axis between -4 and 4, based on the z-score value:
- Large Positive Columns: Signify a high or positive z-score, indicating that the price or volume is significantly above its average.
- Large Negative Columns: Represent a low or negative z-score, suggesting that the price or volume is considerably below its average.
- Short Columns Near 0: Indicate that the price or volume is close to its mean, showcasing minimal deviation.
This columnar representation provides a clear, intuitive view of how each symbol's price and volume deviate from their respective averages.
◽️ Display Type: Circles
In this visualization style, z-scores are depicted using circles. Each symbol is horizontally aligned and represented by:
- Solid Circle: Represents the z-score of price.
- Transparent Circle: Represents the z-score of volume.
The vertical position of these circles on the y-axis ranges between -4 and 4, reflecting the z-score value:
- Circles Near the Top: Indicate a high or positive z-score, suggesting the price or volume is well above its average.
- Circles Near the Bottom: Represent a low or negative z-score, pointing to the price or volume being notably below its average.
- Circles Around the Midline (0): Highlight that the price or volume is close to its mean, with minimal deviation.
◽️ Display Type: Delta Columns
There's also an option to utilize Z-Score Delta Columns. For each symbol, a single column is presented, depicting the difference between the z-score of price and the z-score of volume.
The z-score delta essentially captures the disparity between how much the price and volume deviate from their respective mean:
- Positive Delta: Indicates that the z-score of price is greater than the z-score of volume. This suggests that the price has deviated more from its average than the volume has from its own average. Such a scenario could point to price movements being more significant or pronounced compared to the changes in volume.
- Negative Delta: Represents that the z-score of volume is higher than the z-score of price. This might mean that there are substantial volume changes, yet the price hasn't moved as dramatically. This can be indicative of potential build-up in trading interest without an equivalent impact on price.
- Delta Close to 0: Means that the z-scores for price and volume are almost equal, indicating their deviations from the average are in sync.
◽️ Display Type: Z-Volume/Z-Price Heatmap
This visualization offers a heatmap either for volume z-scores or price z-scores across all symbols. Here's how it's presented:
Each symbol is allocated its own horizontal row. Within this row, bar-by-bar data is displayed using a color gradient to represent the z-score values. The heatmap employs a user-defined gradient scale, where a chosen "cold" color represents low z-scores and a chosen "hot" color signifies high z-scores. As the z-score increases or decreases, the colors transition smoothly along this gradient, providing an intuitive visual indication of the z-score's magnitude.
- Cold Colors: Indicate values significantly below the mean (negative z-score)
- Mild Colors: Represent values close to the mean, suggesting minimal deviation.
- Hot Colors: Indicate values significantly above the mean (positive z-score)
This heatmap format provides a rapid, visually impactful means to discern how each symbol's price or volume is behaving relative to its average. The color-coded rows allow you to quickly spot outliers.
VOLUME TYPE
The "Volume Type" input allows you to choose the nature of volume data that will be factored into the volume z-score calculation. The interpretation of indicator’s data changes based on this input. You can opt between:
- Volume (Regular Volume): This is the classic measure of trading volume, which represents the volume traded in a given time period - bar.
- OBV (On-Balance Volume): OBV is a momentum indicator that accumulates volume on up bars and subtracts it on down bars, making it a cumulative indicator that sort of measures buying and selling pressure.
Interpretation Implications:
- For Volume Type: Regular Volume:
Positive Z-Score: Indicates that the trading volume is above its average, meaning there's unusually high trading activity .
Negative Z-Score: Suggests that the trading volume is below its average, signifying unusually low trading activity.
- For Volume Type: OBV:
Positive Z-Score: Signifies that “buying pressure” is above its average.
Negative Z-Score: Signifies that “selling pressure” is above its average.
When comparing Z-Score of OBV to Z-Score of price, we can observe several scenarios. If Z-Price and Z-Volume are convergent (have similar z-scores), we can say that the directional price movement is supported by volume. If Z-Price and Z-Volume are divergent (have very different z-scores or one of them being zero), it suggests a potential misalignment between price movement and volume support, which might hint at possible reversals or weakness.

Machine Learning using Neural Networks | EducationalThe script provided is a comprehensive illustration of how to implement and execute a simplistic Neural Network (NN) on TradingView using PineScript.
It encompasses the entire workflow from data input, weight initialization, implicit neuron calculation, feedforward computation, backpropagation for weight adjustments, generating predictions, to visualizing the Mean Squared Error (MSE) Loss Curve for monitoring the training phase.
In the visual example above, you can see that the prediction is not aligned with the actual value. This is intentional for demonstrative purposes, and by incrementing the Epochs or Learning Rate, you will see these two values converge as the accuracy increases.
Hyperparameters:
Learning Rate, Epochs, and the choice between Simple Backpropagation and a verbose version are declared as script inputs, allowing users to tailor the training process.
Initialization:
Random initialization of weight matrices (w1, w2) is performed to ensure asymmetry, promoting effective gradient updates. A seed is added for reproducibility.
Utility Functions:
Functions for matrix randomization, sigmoid activation, MSE loss calculation, data normalization, and standardization are defined to streamline the computation process.
Neural Network Computation:
The feedforward function computes the hidden and output layer values given the input.
Two variants of the backpropagation function are provided for weight adjustment, with one offering a more verbose step-by-step computation of gradients.
A wrapper train_nn function iterates through epochs, performing feedforward, loss computation, and backpropagation in each epoch while logging and collecting loss values.
Training Invocation:
The input data is prepared by normalizing it to a value between 0 and 1 using the maximum standardized value, and the training process is invoked only on the last confirmed bar to preserve computational resources.
Output Forecasting and Visualization:
Post training, the NN's output (predicted price) is computed, standardized and visualized alongside the actual price on the chart.
The MSE loss between the predicted and actual prices is visualized, providing insight into the prediction accuracy.
Optionally, the MSE Loss Curve is plotted on the chart, illustrating the loss trajectory through epochs, assisting in understanding the training performance.
Customizable Visualization:
Various inputs control visualization aspects like Chart Scaling, Chart Horizontal Offset, and Chart Vertical Offset, allowing users to adapt the visualization to their preference.
-------------------------------------------------------
The following is this Neural Network structure, consisting of one hidden layer, with two hidden neurons.
Through understanding the steps outlined in my code, one should be able to scale the NN in any way they like, such as changing the input / output data and layers to fit their strategy ideas.
Additionally, one could forgo the backpropagation function, and load their own trained weights into the w1 and w2 matrices, to have this code run purely for inference.
-------------------------------------------------------
While this demonstration does create a “prediction”, it is on historical data. The purpose here is educational, rather than providing a ready tool for non-programmer consumers.
Normally in Machine Learning projects, the training process would be split into two segments, the Training and the Validation parts. For the purpose of conveying the core concept in a concise and non-repetitive way, I have foregone the Validation part. However, it is merely the application of your trained network on new data (feedforward), and monitoring the loss curve.
Essentially, checking the accuracy on “unseen” data, while training it on “seen” data.
-------------------------------------------------------
I hope that this code will help developers create interesting machine learning applications within the Tradingview ecosystem.

Heatmap MACD Strategy - Pineconnector (Dynamic Alerts)Hello traders
This script is an upgrade of this template script.
Heatmap MACD Strategy
Pineconnector
Pineconnector is a trading bot software that forwards TradingView alerts to your Metatrader 4/5 for automating trading.
Many traders don't know how to dynamically create Pineconnector-compatible alerts using the data from their TradingView scripts.
Traders using trading bots want their alerts to reflect the stop-loss/take-profit/trailing-stop/stop-loss to breakeven options from your script and then create the orders accordingly.
This script showcases how to create Pineconnector alerts dynamically.
Pineconnector doesn't support alerts with multiple Take Profits.
As a workaround, for 2 TPs, I had to open two trades.
It's not optimal, as we end up paying more spreads for that extra trade - however, depending on your trading strategy, it may not be a big deal.
TradingView Alerts
1) You'll have to create one alert per asset X timeframe = 1 chart.
Example : 1 alert for EUR/USD on the 5 minutes chart, 1 alert for EUR/USD on the 15-minute chart (assuming you want your bot to trade the EUR/USD on the 5 and 15-minute timeframes)
2) For each alert, the alert message is pre-configured with the text below
{{strategy.order.alert_message}}
Please leave it as it is.
It's a TradingView native variable that will fetch the alert text messages built by the script.
3) Don't forget to set the webhook URL in the Notifications tab of the TradingView alerts UI.
EA configuration
The Pyramiding in the EA on Metatrader must be set to 2 if you want to trade with 2 TPs => as it's opening 2 trades.
If you only want 1 TP, set the EA Pyramiding to 1.
Regarding the other EA settings, please refer to the Pineconnector documentation on their website.
Logger
The Pineconnector commands are logged in the TradingView logger.
You'll find more information about it from this TradingView blog post
Important Notes
1) This multiple MACDs strategy doesn't matter much.
I could have selected any other indicator or concept for this script post.
I wanted to share an example of how you can quickly upgrade your strategy, making it compatible with Pineconnector.
2) The backtest results aren't relevant for this educational script publication.
I used realistic backtesting data but didn't look too much into optimizing the results, as this isn't the point of why I'm publishing this script.
3) This template is made to take 1 trade per direction at any given time.
Pyramiding is set to 1 on TradingView.
The strategy default settings are:
Initial Capital: 100000 USD
Position Size: 1 contract
Commission Percent: 0.075%
Slippage: 1 tick
No margin/leverage used
For example, those are realistic settings for trading CFD indices with low timeframes but not the best possible settings for all assets/timeframes.
Concept
The Heatmap MACD Strategy allows selecting one MACD in five different timeframes.
You'll get an exit signal whenever one of the 5 MACDs changes direction.
Then, the strategy re-enters whenever all the MACDs are in the same direction again.
It takes:
long trades when all the 5 MACD histograms are bullish
short trades when all the 5 MACD histograms are bearish
You can select the same timeframe multiple times if you don't need five timeframes.
For example, if you only need the 30min, the 1H, and 2H, you can set your timeframes as follow:
30m
30m
30m
1H
2H
Risk Management Features
All the features below are pips-based.
Stop-Loss
Trailing Stop-Loss
Stop-Loss to Breakeven after a certain amount of pips has been reached
Take Profit 1st level and closing X% of the trade
Take Profit 2nd level and close the remaining of the trade
Custom Exit
I added the option ON/OFF to close the opened trade whenever one of the MACD diverges with the others.
Help me help the community
If you see any issue when adding your strategy logic to that template regarding the orders fills on your Metatrader, please let me know in the comments.
I'll use your feedback to make this template more robust. :)
What's next?
I'll publish a more generic template built as a connector so you can connect any indicator to that Pineconnector template.
Then, I'll publish a template for Capitalise AI, ProfitView, AutoView, and Alertatron.
Thank you
Dave
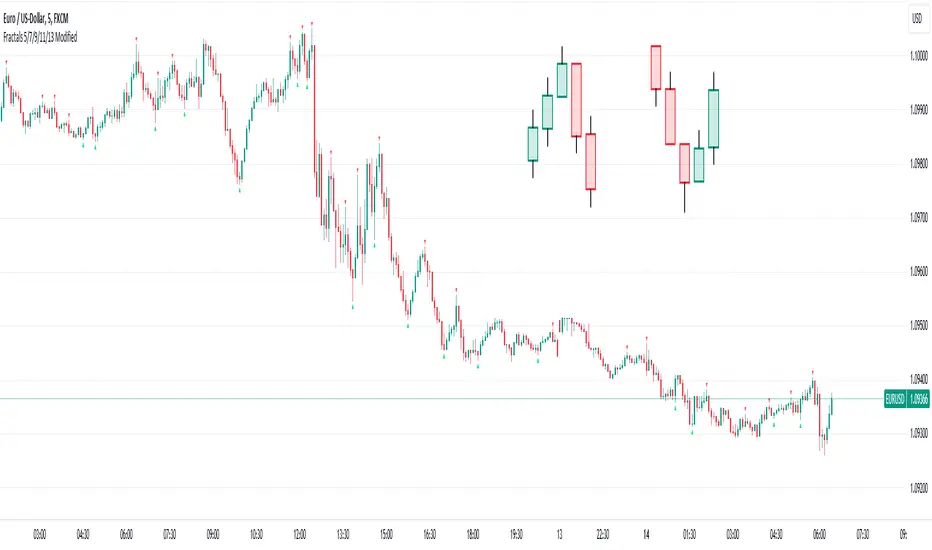
Fractals 5/7/9/11/13 ModifiedDescription:
The Modified Fractals Indicator is designed to help traders identify specific fractal patterns on a chart. Unlike traditional Williams Fractals, this indicator focuses on highlighting two distinct types of fractals:
- UpFractals: These fractals are identified when each preceding candle has a higher high than the one before it, and each succeeding candle has a higher high than the one following it.
- DownFractals: Conversely, DownFractals are detected when each preceding candle has a lower low than the one before it, and each succeeding candle has a lower low than the one following it.
This unique approach sets it apart from standard Fractal indicators.
Features:
1. Originality and Uniqueness: This indicator employs a distinctive algorithm to detect and display modified fractals, providing a fresh perspective on price reversals.
2. Customizable Parameters: Users can fine-tune the indicator to their trading strategy by adjusting the candle count and arrow size.
3. Easy-to-Understand Chart: The Modified Fractals Indicator is designed to provide clear and easily identifiable signals on your chart, enhancing your trading experience.
4. User-Friendly Interface: This indicator is user-friendly and can be easily integrated into your TradingView setup.
How it Works:
The Modified Fractals Indicator scans the price action on your chart and identifies specific fractal patterns based on the criteria mentioned above for both UpFractals and DownFractals.
Usage:
- Add the Modified Fractals Indicator to your TradingView chart.
- Customize the settings, including the candle count and arrow size, to align with your trading strategy.
- Observe the chart for the appearance of UpFractals and DownFractals as marked by the indicator's arrows.
- Use the signals provided by the indicator to inform your trading decisions, such as potential entry or exit points.
Please note that this Modified Fractals Indicator offers a unique approach to fractal analysis, focusing on specific price patterns that differ from traditional Williams Fractals. It provides traders with an additional tool for identifying potential trend reversals and market opportunities.
Machine Learning: MFI Heat Map [YinYangAlgorithms]Overview:
MFI Heat Maps are a visually appealing way to display the values of 29 different MFIs at the same time while being able to make sense of it. Each plot within the Indicator represents a different MFI value. The higher you get up, the longer the length that was used for this MFI. This Indicator also features the use of Machine Learning to help balance the MFI levels. It doesn’t solely rely upon Machine Learning but instead incorporates a growing length MFI averaged with the Machine Learning MFI at any given index.
For instance, say we are calculating the 10th plot from the bottom, the MFI would be an average of:
MFI(source, 11)
Machine Learning MFI at Index of 10
We do it this way as they both help smooth each other out without relying solely on just one calculation method.
Due to plot limitations, you are capped at 28 Plot Amounts within this indicator, but that is still quite a bit of information you can glean from a Heat Map.
The Machine Learning used in this indicator is of the K-Nearest Neighbor (KNN). It uses a Fast and Slow MFI calculation then sorts through them over Machine Learning Length and calculates the differences between them. It then slices off KNN length to create our Max/Min Distances allotted. It adds the average between Fast and Slow MFIs to a Viable Distances array if their distances are within the KNN Min/Max distance. It then averages all distances in the Viable Distances array and returns the result.
The result of the KNN Function is saved to another ML Data array whose length is that of Plot Amount (Heat Map Size). This way each Index of the ML Data array can be indexed according to the Heat Map Size.
The Average of the ML Data array is the MFI line (white) that you’ll see plotted on the Indicator. There is also the SMA of the MFI Average (orange) which is likewise plotted. These plots allow you to visualize where the ML MFI is sitting and can potentially be useful for seeing when the MFI Average and SMA cross over and under each other.
We’ve heard many people talk highly of RSI, but sadly not too many even refer to MFI. MFI oftentimes may be overlooked, especially with new traders who may not even know what it is. Essentially MFI is an RSI but it also incorporates Volume into its calculations, which in our opinion leads to a more accurate reading; afterall, what is price movement without Volume.
Tutorial:
You may be thinking, this Indicator looks appealing to the eye, but how do I benefit from it trading wise?
Before we get into our visual examples, let's talk briefly about what makes Heat Maps in general a useful tool for trading. Heat Maps give us the ability to visualize and understand lots of data while removing the clutter. We can understand the data of 29 different MFIs without having to look at and decipher 29 different MFI plots. When you overlay too many MFI lines on top of each other, they can be very difficult to read and oftentimes end up actually hindering your Technical Analysis. For this reason, we have a simple solution to this problem; Heat Maps. This MFI Heat Map allows you to easily know (in a relative %) what the MFI level is for varying lengths. For Instance, the First (bottom) plot indexes an MFI of (K(0) (loop of Plot Amount) + Smoothing Length (default 1)) = 1. Since this is indexing (usually) a very low length, it will change much quicker. Whereas the Last (top) plot indexes an MFI of (K(27) (loop of Plot Amount) + Smoothing Length (default 1)) = 28. This is indexing a much higher length of MFI which results in the MFI the higher you go up in the Heat Map to move much slower.
Heat Maps give us the ability to see changes happening over multiple MFIs at the same time, which can be very useful for seeing shifts in MFI / Momentum. Remember, MFI incorporates Volume, so even if the price goes up a lot, if there was low volume, the MFI won’t move as much as an RSI would. However, likewise, if there is high volume but low price movement, the MFI will move slightly more than the RSI.
Heat Maps change color based on their MFI level. If the MFI is >= 90 it is HOT (red), if the MFI <= 9 it is COLD (teal, think of ICE). Green represents an MFI of 50-59 and Dark Blue represents an MFI of 40-49. Green and Dark blue are the most common colors as all the others are more ‘Extreme’ MFI levels.
Okay, time to get to the Examples :
Since there is so much going on in Heat Maps, we’ve decided to focus this tutorial to this specific area and talk about individual locations before talking about it as a whole.
If you refer to the example above where there are 2 white circles; these white circles are highlighting a key location you’ll be wanting to identify within your Heat Maps, many things are happening here:
The MFI crossed over the SMA (bullish).
The Heat Map started changing from mid/dark Blue (30-50 MFI) to Green (50-59 MFI) around the midline (the 50% dashed like).
The Lower levels of the Heat Map are turning Yellow/Orange/Red (60-100 MFI).
The Upper Levels of the Heat Map are still Light Blue - Green (10-50 MFI).
The 4 Key points above, all point towards potential Bullish Momentum changes. You’re likely wondering, but why? Let's discuss about each one in more specific detail:
1. The MFI crossed over the SMA (bullish): What this tells us is that the current MFI Average is now greater than its average over the last (default) 16 bars. This means there's been a large amount of Money Flow (Price and Volume) recently (subjectively based on the last (default) 16 average). This is one of the leading Bullish / Bearish signals you will see within this Indicator. You can enable Signals within the Settings and/or even add Alerts for when these crossings occur.
2. The Heat Map started changing from mid/dark Blue (30-50 MFI) to Green (50-59 MFI) around the midline (the 50% dashed like): This shows us that the index’s in the mid (if using all 28 heat map plots it would be at 14) has already received some of this momentum change. If you look at the second white circle (right), you’ll also notice the higher MFI plot indexes are also green. This is because since their length is long they still have some momentum and strength from the first white circle (left). Just because the first white circle failed in its bullish push, doesn’t mean it didn’t achieve momentum that would later on help to push the price up.
3. The Lower levels of the Heat Map are turning Yellow/Orange/Red (60-100 MFI): It occurred somewhat in the left white circle, but mainly in the right white circle. This shows us the MFI is very high on the lower lengths, this may lead to the current, middle and higher length MFIs following suit soon. Remember it has to work its way up, the higher levels can’t go red unless the lower levels go red first and the higher levels can also lag quite a bit behind and take awhile to catch up, this is normal, expected and meant to happen. Vice versa is also true with getting higher levels to go cold (light teal (think of ICE)).
4. The Upper Levels of the Heat Map are still Light Blue - Green (10-50 MFI): You might think at first that this is a bad thing, but it's not! Remember you want to be Fearful when others are Greedy and Greedy when others are Fearful! You don’t want to buy when the higher levels have a high MFI, you want to buy when you see the momentum pushing up in the lower MFI levels (getting yellow/orange/red in the low levels) while it is still Cold in the higher levels (BLUE OR GREEN, nothing higher than green as it is already slightly too high). There will be many times that it is Yellow or possibly Orange in the high levels and the bullish push still happens, but this is much more risky! The key to trading is to minimize risks while maximizing potential.
Hopefully now you’re getting an idea of how to spot potential bullish momentum changes, but what about bearish momentum changes? Technically they are the exact opposite, so we don’t need to go into as much detail, but lets still take a look at a few examples:
In the example above we marked the 3 times where it was displaying overly bullish characteristics. We marked the bullish momentum occurring with arrows. If you look closely at the start of the arrow to where it finishes, you’ll notice how the heat (HOT)(RED) works its way up from the lower levels to the higher levels. We then see the MFI to SMA cross under. In all 3 of these examples the heat made it all the way to the top of the chart. These are all very bearish signals that represent a bearish momentum movement that may occur soon.
Also, please note, the level the MFI is at DOES matter! That line isn’t there simply for you to see when there are crosses over and under. The MFI is considered to be Overbought when it is greater than 70 (the upper white dashed line, it is just formatted to be on a different scale cause there are 28 plots, but it represents 70). The MFI is considered to be Oversold when it is less than 30 (the lower white dashed line).
If we look to the left a little here where a big drop in price occurred shortly after our MFI and SMA crossed, would we have been able to identify it using the Heat Maps? Likely, No. There was some color change in the lower levels a few bars prior that went yellow/orange/red but before this cross happened they all went back to Dark Blue. In the middle section when the cross happened it was only Green and Yellow and in the upper section we are Blue. This would be a very risky trade to go on as the only real Bearish Indication was the MFI to SMA cross under. Remember, you want to reduce risk, you don’t want to simply trade on everytime the MFI and SMA cross each other or you’ll be getting yourself into many risky trades based on false signals.
Based on what you’ve learned above, can you see the signs that are indicating where this white circle may have potential for a bullish momentum change?
Now that we are more zoomed in, you may also be noticing there are colors to the price bars. This can be disabled in the settings, but just so you know what they mean, let’s zoom in a little more and talk about it.
We’ve condensed the Indicator a bit so you can see the bars better here. The colors that are displayed on these bars are the Heat Map value for your MFI (the white line in the Indicator). This way you can better see when the Price is Hot and Cold. As you may see while looking, the colors generally go from cold to hot when bullish momentum is happening and hot to cold when bearish momentum is happening. We don’t recommend solely looking at the bars as indicators to MFI momentum change, as seeing the Heat Map will give you much more data; however it can be nice to see the Heat Map projected on the bars rather than trying to eyeball it yourself or hover over each bar specifically to see their levels.
We will conclude our Tutorial here. Hopefully this has given you some insight to how useful Heat Maps can be and why it works well with a Machine Learning (KNN) Model applied to the MFI.
PLEASE NOTE: You can adjust the line width for the Heat Map within the settings. If you condense the Indicator a lot or have a small screen, likely use a length of 1-2. If you have it stretched out or a large screen, a length of 2-3 will work nice. You just don’t want to have the lines overlapping or it defeats the purpose of a Heat Map. Also, the bigger the linewidth, generally you’ll want to increase the Transparency within the Settings also as it can get quite bright and hurt your eyes over time.
Settings:
MFI:
Show MFI and SMA Crossing Signals: MFI and SMA Crossing is one of the leading Bullish and Bearish Signals in this Indicator. You can also add alerts for these signals.
Plot Amount: How many plots are used in this Heat Map. (2 - 28).
Source: The Source to use in all MFI calculations.
Smooth Initial MFI Length: How much to smooth the Fast and Slow MFI calculation by. 1 = No smoothing.
MFI SMA Length: What length we smooth the MFI Average over to get our MFI SMA.
Machine Learning:
Average MFI data by adding a lookback to the Source: While populating our Heat Map with the MFI's, should use use the Source each MFI Length increase or should we also lookback a Source each MFI Length Increase.
KNN Distance Requirement: To be a valid KNN, it needs to abide by a Distance calculation. Generally only Max is used, but you can change it if it suits your trading style better.
Machine Learning Length: How much ML data should we store? The longer the length generally the smoother the result; which may not be as accurate for something like a Heat Map, so keeping this relatively low may lead to more accurate results.
KNN Length: How many KNN are used in the slice to calculate max/min distance allowed.
Fast Length: Fast MFI length used in KNN to calculate distances by comparing its distance with the Slow MFI Length.
Slow Length: Slow MFI length used in KNN to calculate distances by comparing its distance with the Fast MFI Length.
Smoothing Length: When populating our Heat Map, at what length do we start our MFI calculations with (A Higher value with result in a slower and more smoothed MFI / Heat Map).
Colors:
Change Bar Color: Change bar colors to MFI Avg Color.
Heat Map Transparency: If there isn't any transparency it can be a little hard on the eyes. The Greater the Line Width, generally the more transparency you'll want for your eyes.
Line Width: Set how wide the Heat Map lines are
MFI 90-100 Color: Color when the MFI is between these levels.
MFI 80-89 Color: Color when the MFI is between these levels.
MFI 70-79 Color: Color when the MFI is between these levels.
MFI 60-69 Color: Color when the MFI is between these levels.
MFI 50-59 Color: Color when the MFI is between these levels.
MFI 40-49 Color: Color when the MFI is between these levels.
MFI 30-39 Color: Color when the MFI is between these levels.
MFI 20-29 Color: Color when the MFI is between these levels.
MFI 10-19 Color: Color when the MFI is between these levels.
MFI 0-100 Color: Color when the MFI is between these levels.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!

Tribute to David PaulI made this indicator as a tribute to the late David Paul .
He mentioned quite a lot about 89 periods moving average (especially on 4h), also the 21 and 55.
I put up some entries when three ma are crossed by price in the same direction, bull/bear backgrounds and a color code for candles because who doesn't love the feeling of a lasting trend.
To be more specific :
The indicator plots sma21, sma55, sma89 and AMA = (sma21+sma55+sma89)/3
When the closing price crosses the highest of the 3 sma, it is considered a bullish confirmation.
At this moment two lines appear, one on the bottom of the candle that crossed, one on the crossing point.
The lowest line can be used as the stop loss value of a long.
The highest line can be used as an entry point for a long.
When the closing price crosses the lowest of the 3 sma, it is considered a bearish confirmation.
At this moment two lines appear, one on the top of the candle that crossed, one on the crossing point.
The highest line can be used as the stop loss value of a short.
The lowest line can be used as an entry point for shorts.
When the closing price is above AMA, it is considered a bullish confirmation.
At this time a blue background appears at the crossing point.
The highest line can be used as the stop loss value for a long.
The starting point of the background can be used as the entry point for a long.
When the closing price is below AMA, it is considered a bearish confirmation.
At this time a red background appears at the crossing point.
The highest line can be used as the stop loss value for a short.
The starting point of the background can be used as the entry point for a short.
When the price is above 3 sma the candles turn blue. Signifying an upward trend.
When the price is below 3 sma the candles turn red. Signifying a bearish trend.
When the price is neither simultaneously above nor below the 3 sma, the candles are gray and the background linked to AMA becomes less vivid. Meaning a loss of vitality of the current trend or an absence of a clear trend.
Ideally, you should take a position towards "Real Long/Short Entry", set your stop loss towards "Ideal Long/Short Entry", and close the trade either when the background ends (riskier but more potential), or when the candles become gray (more conservative but noisier).
In the inputs, you can modify the display rules (explained in the tooltips), by default everything is displayed.

RSI Trend Detector PSAR BasedRSI Trend Detector is based on the Direction of PSAR. This indicator helps the easy detection of Trend Direction and Sideways Movement of Price. It was difficult to determine the RSI Trend Direction in a basic RSI indicator. one cannot decide the exact entry point where to enter.
RSI Trend Detector helps with the direction of trend using PSAR direction which is almost instant direction changing indicator with Zero Lag. The color of the RSI changes immediately based on PSAR direction. One can determine the trend whether its in UP / Down or Sideways.
One can easily detect Pullback and entry points using this indicator.
The basic working can be interpreted with a normal default RSI, The only additional feature is the direction of trend using a SAR signal.
Oversold Zone is below 30
Overbought Zone is above 70
how ever RSI above 50 is treated a UP trend and Below 50 as Down Trend.
when RSI is between 40 and 60 price must be considered as Sideways. One can easily interpret the TREND.
Yellow Line = RSI Moving Average
RED and Green Line= RSI
Grey Zone = Sideways
Horizontal line = RSI level 50
Settings can be changed as required.
RSI Line:
RSI Above 50 up trend and Entry when color is green
RSI Below 50 down trend and Entry when color is Red
RSI in Grey Zone is sideways, wait for a breakout
RSI above 50 and color is red then its a pullback in uptrend
RSI below 50 and color is green then its a pullback in downtrend
ALERTS:
Up signal and Down Signal are provided when ever RSI crosses RSIMA
Up Signal: RSI crosses RSI Moving Average upwards
Down Signal: RSI crosses RSI Moving Average Downwards
Hope the Tradingview community likes this.

Volume Crossover StrategyThis script shows us the strength and acceleration of the trend, not the direction. ! . The indicator is built on the collision of two volumes (the collision of one-hour and four-hour volumes), where as a result one upward arrow shows us (acceleration, pressing the gas on the pedal), and the downward one shows deceleration (i.e. braking).
Recommendation: Be sure to attach:
a) any trend direction indicator (SMA, EMA), through which we will have an idea where the market is going and going:
b) volatility indicator
c) AD accumulation distribution (let's have a real picture, is there a buying or selling trend)
It is suitable for a one-hour timeframe
P.S. The script does not make any guarantee of profit, it is published only for the purpose of sharing my opinion about this strategy.
an hour ago
Comment:
The green signal is the start of the marathon, and the red signal is the end. For example, if the downward trend has ended (we can see it through the blue signal), it does not mean that the next marathon will necessarily be a reflected trend. It is not excluded that the next marathon will also develop on a downward trend...and therefore in the opposite case as well..
Composite Momentum IndicatorComposite Momentum Indicator" combines the signals from several oscillators, including Stochastic, RSI, Ultimate Oscillator, and Commodity Channel Index (CCI) by averaging the standardized values (Z-Scores). Since it is a Z-Score based indicators the values will be typically be bound between +3 and -3 oscillating around 0. Here's a summary of the code:
Input Parameters: Users can customize the look-back period and set threshold values for overbought and oversold conditions. They can also choose which oscillators to include in the composite calculation.
Oscillator Calculations: The code calculates four separate oscillators - Stochastic, RSI, Ultimate Oscillator, and CCI - each measuring different aspects of market momentum.
Z-Scores Calculation: For each oscillator, the code calculates a Z-Score, which normalizes the oscillator's values based on its historical standard deviation and mean. This allows for a consistent comparison of oscillator values across different timeframes.
Composite Z-Score: The code aggregates the Z-Scores from the selected oscillators, taking into account user preferences (whether to include each oscillator). It then calculates an average Z-Score to create the "Composite Momentum Oscillator."
Conditional Color Coding: The composite oscillator is color-coded based on its average Z-Score value. It turns green when it's above the overbought threshold, red when it's below the oversold threshold, and blue when it's within the specified range.
Horizontal Lines: The code plots horizontal lines at key levels, including 0, ±3, ±2, and ±1, to help users identify important momentum levels.
Gradient Fills: It adds gradient fills above the overbought threshold and below the oversold threshold to visually highlight extreme momentum conditions.
Combining the Stochastic, RSI, Ultimate Oscillator, and Commodity Channel Index (CCI) into one composite indicator offers several advantages for traders and technical analysts:
Comprehensive Insight: Each of these oscillators measures different aspects of market momentum and price action. Combining them into one indicator provides a more comprehensive view of the market's behavior, as it takes into account various dimensions of momentum simultaneously.
Reduced Noise: Standalone oscillators can generate conflicting signals and produce noisy readings, especially during choppy market conditions. A composite indicator smoothes out these discrepancies by averaging the signals from multiple indicators, potentially reducing false signals.
Confirmation and Divergence: By combining multiple oscillators, traders can seek confirmation or divergence signals. When multiple oscillators align in the same direction, it can strengthen a trading signal. Conversely, divergence between the oscillators can warn of potential reversals or weakening trends.
Customization: Traders can tailor the composite indicator to their specific trading strategies and preferences. They have the flexibility to include or exclude specific oscillators, adjust look-back periods, and set threshold levels. This adaptability allows for a more personalized approach to technical analysis.
Clarity and Efficiency: Rather than cluttering the chart with multiple individual oscillators, a composite indicator condenses the information into a single plot. This enhances the clarity of the chart and makes it easier for traders to quickly interpret market conditions.
Overbought/Oversold Identification: Combining these oscillators can improve the identification of overbought and oversold conditions. It reduces the likelihood of false signals since multiple indicators must align to trigger these extreme conditions.
Educational Tool: For novice traders and analysts, a composite indicator can serve as an educational tool by demonstrating how different oscillators interact and influence each other's signals. It allows users to learn about multiple technical indicators in one glance.
Efficient Use of Screen Space: A single composite indicator occupies less screen space compared to multiple separate indicators. This is especially beneficial when analyzing multiple markets or timeframes simultaneously.
Holistic Approach: Instead of relying on a single indicator, a composite approach encourages a more holistic assessment of market conditions. Traders can consider a broader range of factors before making trading decisions.
Increased Confidence: A composite indicator can boost traders' confidence in their decisions. When multiple reliable indicators align, it can provide a stronger basis for taking action in the market.
In summary, combining the Stochastic, RSI, Ultimate Oscillator, and CCI into one composite indicator enhances the depth and reliability of technical analysis. It simplifies the decision-making process, reduces noise, and offers a more complete picture of market momentum, ultimately helping traders make more informed and well-rounded trading decisions.
* Feel free to compare against individual oscillatiors*
[GTH decimals heatmap] (wide screen advised)Preface
I share my personal general view on indicators below; skip ahead to the Description below if you are not interested.
It is my personal conviction that most - if not all - indicators rely mainly on trader's belief that they work, and in a feedback system like free markets they might become a self-fulfilling prophecy as a result, if (!) a big part of the traders believes in it, because some famous trader releases an indicator, or such person's public statement goes viral.
One of those voodoo indicators is the famous "follow-through day". There is zero statistical evidence for its validity, beyond the validity of a statement like "If it's bright at day it's usually the sun shining". The uselessness was proven exactly on its inventor's YT channel, Investors Business Daily. According to the examiner, its inventor William J. O'Neil himself could not explain the values used for this indicator. It might have been an incidental observation at some point without general validity. A.k.a "curve fitting". Still, it's being used by many today.
Another one of those indicators is the three points reversal on the S&P 500 Volatility Index (VIX) which allegedly might potentially maybe indicate a possible shift in trend. Both indicators share an immediately problematic feature: They use absolute values. Nothing is ever absolute in a highly subjective and emotionally driven game like the markets where a lot of money can be made and lost.
Most indicators can not produce additional information since they can only re-pack price/volume action. Many times an interpretion of the distance between price and a moving average and/or the slope of a moving average deliver very similar - if not better - results than MACD, RSI etc., especially with standard settings, the origin of which are usually unknown (always a warning sign). Very few indicators can deliver information which is otherwise hard to quantify, e. g. market noise (Kaufman's Efficiency Ratio or Price Density) or volatility, standard deviation etc.
It is common knowledge that trading the markets is a game of probability. No indicator works all the time (or at all, see above). In order to make decisions based on any indicator, the probability for its validity and the conditions under which validity seemed to have occurred, must be known. Otherwise it is just coffee grounds reading under the illusion of adding to the edge, when in fact it is only adding to the trees, making it even harder to see the forest.
Description
A common belief is that whole or half-dollar prices tend to be attraction points in price action, so a number of traders include those into decision making. But are they really...?
Spoiler Alert:
Generally, it is safe to say that for the big majority of stocks there is very thin evidence for it. It depends vastly on the asset, the timeframe used and the market period (pre/post/main trading times). If at all, there seems to be an above random but still thin evidence for whole prices being significant attraction points. Interesting/surprising patterns are visible on many stocks/timeframes/session periods, though.
The screenshot shows TSLA, 30m timeframe, two heatmaps added. The top one shows pre/post-market data only, the bottom one main market data only. The cyan fields indicate the strongest occurrence, the dark blue fields indicate the weakest occurrence of open/high/low/close prices at the respective decimal. The red field indicates the current/last price decimal.
Clearly, TSLA displays a strong pre-market attraction for .00, followed by .33 and .67 and .50. This pattern of thirds seems to be a unique feature of TSLA. In the main trading session it is being diluted by a more random distribution.
Other interesting equities to examine:
SPY: No significant pattern on any timeframe!
META: Generally weak patterns on all timeframes, but interestingly on the 1D there is evidence for less randomness on O and H, more on L and most on C.
AAPL: 1D, foggy attraction areas around .35 and .12. Whole price is no attraction area at all! Very weak attraction around .73.
AMD: Strong pattern on D, W, M, attraction areas around 1/16th intervals. No patterns on lower timeframes.
AMZN: Significant differences between pre/post and main session. Strong 1/16th pattern below D in pre/post.
TAOP: Strong 1/5th pattern on all timeframes.
Read the tool tips and go explore!
Support & Resistance AI (K means/median) [ThinkLogicAI]█ OVERVIEW
K-means is a clustering algorithm commonly used in machine learning to group data points into distinct clusters based on their similarities. While K-means is not typically used directly for identifying support and resistance levels in financial markets, it can serve as a tool in a broader analysis approach.
Support and resistance levels are price levels in financial markets where the price tends to react or reverse. Support is a level where the price tends to stop falling and might start to rise, while resistance is a level where the price tends to stop rising and might start to fall. Traders and analysts often look for these levels as they can provide insights into potential price movements and trading opportunities.
█ BACKGROUND
The K-means algorithm has been around since the late 1950s, making it more than six decades old. The algorithm was introduced by Stuart Lloyd in his 1957 research paper "Least squares quantization in PCM" for telecommunications applications. However, it wasn't widely known or recognized until James MacQueen's 1967 paper "Some Methods for Classification and Analysis of Multivariate Observations," where he formalized the algorithm and referred to it as the "K-means" clustering method.
So, while K-means has been around for a considerable amount of time, it continues to be a widely used and influential algorithm in the fields of machine learning, data analysis, and pattern recognition due to its simplicity and effectiveness in clustering tasks.
█ COMPARE AND CONTRAST SUPPORT AND RESISTANCE METHODS
1) K-means Approach:
Cluster Formation: After applying the K-means algorithm to historical price change data and visualizing the resulting clusters, traders can identify distinct regions on the price chart where clusters are formed. Each cluster represents a group of similar price change patterns.
Cluster Analysis: Analyze the clusters to identify areas where clusters tend to form. These areas might correspond to regions of price behavior that repeat over time and could be indicative of support and resistance levels.
Potential Support and Resistance Levels: Based on the identified areas of cluster formation, traders can consider these regions as potential support and resistance levels. A cluster forming at a specific price level could suggest that this level has been historically significant, causing similar price behavior in the past.
Cluster Standard Deviation: In addition to looking at the means (centroids) of the clusters, traders can also calculate the standard deviation of price changes within each cluster. Standard deviation is a measure of the dispersion or volatility of data points around the mean. A higher standard deviation indicates greater price volatility within a cluster.
Low Standard Deviation: If a cluster has a low standard deviation, it suggests that prices within that cluster are relatively stable and less likely to exhibit sudden and large price movements. Traders might consider placing tighter stop-loss orders for trades within these clusters.
High Standard Deviation: Conversely, if a cluster has a high standard deviation, it indicates greater price volatility within that cluster. Traders might opt for wider stop-loss orders to allow for potential price fluctuations without getting stopped out prematurely.
Cluster Density: Each data point is assigned to a cluster so a cluster that is more dense will act more like gravity and
2) Traditional Approach:
Trendlines: Draw trendlines connecting significant highs or lows on a price chart to identify potential support and resistance levels.
Chart Patterns: Identify chart patterns like double tops, double bottoms, head and shoulders, and triangles that often indicate potential reversal points.
Moving Averages: Use moving averages to identify levels where the price might find support or resistance based on the average price over a specific period.
Psychological Levels: Identify round numbers or levels that traders often pay attention to, which can act as support and resistance.
Previous Highs and Lows: Identify significant previous price highs and lows that might act as support or resistance.
The key difference lies in the approach and the foundation of these methods. Traditional methods are based on well-established principles of technical analysis and market psychology, while the K-means approach involves clustering price behavior without necessarily incorporating market sentiment or specific price patterns.
It's important to note that while the K-means approach might provide an interesting way to analyze price data, it should be used cautiously and in conjunction with other traditional methods. Financial markets are influenced by a wide range of factors beyond just price behavior, and the effectiveness of any method for identifying support and resistance levels should be thoroughly tested and validated. Additionally, developments in trading strategies and analysis techniques could have occurred since my last update.
█ K MEANS ALGORITHM
The algorithm for K means is as follows:
Initialize cluster centers
assign data to clusters based on minimum distance
calculate cluster center by taking the average or median of the clusters
repeat steps 1-3 until cluster centers stop moving
█ LIMITATIONS OF K MEANS
There are 3 main limitations of this algorithm:
Sensitive to Initializations: K-means is sensitive to the initial placement of centroids. Different initializations can lead to different cluster assignments and final results.
Assumption of Equal Sizes and Variances: K-means assumes that clusters have roughly equal sizes and spherical shapes. This may not hold true for all types of data. It can struggle with identifying clusters with uneven densities, sizes, or shapes.
Impact of Outliers: K-means is sensitive to outliers, as a single outlier can significantly affect the position of cluster centroids. Outliers can lead to the creation of spurious clusters or distortion of the true cluster structure.
█ LIMITATIONS IN APPLICATION OF K MEANS IN TRADING
Trading data often exhibits characteristics that can pose challenges when applying indicators and analysis techniques. Here's how the limitations of outliers, varying scales, and unequal variance can impact the use of indicators in trading:
Outliers are data points that significantly deviate from the rest of the dataset. In trading, outliers can represent extreme price movements caused by rare events, news, or market anomalies. Outliers can have a significant impact on trading indicators and analyses:
Indicator Distortion: Outliers can skew the calculations of indicators, leading to misleading signals. For instance, a single extreme price spike could cause indicators like moving averages or RSI (Relative Strength Index) to give false signals.
Risk Management: Outliers can lead to overly aggressive trading decisions if not properly accounted for. Ignoring outliers might result in unexpected losses or missed opportunities to adjust trading strategies.
Different Scales: Trading data often includes multiple indicators with varying units and scales. For example, prices are typically in dollars, volume in units traded, and oscillators have their own scale. Mixing indicators with different scales can complicate analysis:
Normalization: Indicators on different scales need to be normalized or standardized to ensure they contribute equally to the analysis. Failure to do so can lead to one indicator dominating the analysis due to its larger magnitude.
Comparability: Without normalization, it's challenging to directly compare the significance of indicators. Some indicators might have a larger numerical range and could overshadow others.
Unequal Variance: Unequal variance in trading data refers to the fact that some indicators might exhibit higher volatility than others. This can impact the interpretation of signals and the performance of trading strategies:
Volatility Adjustment: When combining indicators with varying volatility, it's essential to adjust for their relative volatilities. Failure to do so might lead to overemphasizing or underestimating the importance of certain indicators in the trading strategy.
Risk Assessment: Unequal variance can impact risk assessment. Indicators with higher volatility might lead to riskier trading decisions if not properly taken into account.
█ APPLICATION OF THIS INDICATOR
This indicator can be used in 2 ways:
1) Make a directional trade:
If a trader thinks price will go higher or lower and price is within a cluster zone, The trader can take a position and place a stop on the 1 sd band around the cluster. As one can see below, the trader can go long the green arrow and place a stop on the one standard deviation mark for that cluster below it at the red arrow. using this we can calculate a risk to reward ratio.
Calculating risk to reward: targeting a risk reward ratio of 2:1, the trader could clearly make that given that the next resistance area above that in the orange cluster exceeds this risk reward ratio.
2) Take a reversal Trade:
We can use cluster centers (support and resistance levels) to go in the opposite direction that price is currently moving in hopes of price forming a pivot and reversing off this level.
Similar to the directional trade, we can use the standard deviation of the cluster to place a stop just in case we are wrong.
In this example below we can see that shorting on the red arrow and placing a stop at the one standard deviation above this cluster would give us a profitable trade with minimal risk.
Using the cluster density table in the upper right informs the trader just how dense the cluster is. Higher density clusters will give a higher likelihood of a pivot forming at these levels and price being rejected and switching direction with a larger move.
█ FEATURES & SETTINGS
General Settings:
Number of clusters: The user can select from 3 to five clusters. A good rule of thumb is that if you are trading intraday, less is more (Think 3 rather than 5). For daily 4 to 5 clusters is good.
Cluster Method: To get around the outlier limitation of k means clustering, The median was added. This gives the user the ability to choose either k means or k median clustering. K means is the preferred method if the user things there are no large outliers, and if there appears to be large outliers or it is assumed there are then K medians is preferred.
Bars back To train on: This will be the amount of bars to include in the clustering. This number is important so that the user includes bars that are recent but not so far back that they are out of the scope of where price can be. For example the last 2 years we have been in a range on the sp500 so 505 days in this setting would be more relevant than say looking back 5 years ago because price would have to move far to get there.
Show SD Bands: Select this to show the 1 standard deviation bands around the support and resistance level or unselect this to just show the support and resistance level by itself.
Features:
Besides the support and resistance levels and standard deviation bands, this indicator gives a table in the upper right hand corner to show the density of each cluster (support and resistance level) and is color coded to the cluster line on the chart. Higher density clusters mean price has been there previously more than lower density clusters and could mean a higher likelihood of a reversal when price reaches these areas.
█ WORKS CITED
Victor Sim, "Using K-means Clustering to Create Support and Resistance", 2020, towardsdatascience.com
Chris Piech, "K means", stanford.edu
█ ACKNOLWEDGMENTS
@jdehorty- Thanks for the publish template. It made organizing my thoughts and work alot easier.

Doji TrenderDoji Trender searches multiple timeframes for candles where open and close are less than dojiPercent apart (default 0.025%), and plots the trends between them.
Experiment with dojiPercent to change the number of "dojis" detected. I will add doji sub-type indication if it appears to be meaningful.
By default, it plots the 5m (red), 15m (orange), 1h (yellow), 4h (green), and chart (cyan). If the chart timeframe is any of the configurable ones, the chart copy won't be drawn. (I might reverse that, so that cyan is always drawn.)
Since doji points are somewhat sparse, and the lookback is short (default 10), the EMA's make drastic corrections toward new indecision. (I'm not convinced the EMA's are useful and/or relevant.)
This works on any timeframe, but seems to work best on the 1D. (5m is somewhat irrelevant on the 1D, so there are tweaks to be made.)
Dojis from a timeframe are corrections to a doji trend from a higher timeframe.
Red corrects to orange, corrects to yellow, corrects to green.
If the chart timeframe is > 4h, the others will correct to cyan.
Otherwise, cyan will fit in-between the adjacent timeframes.
Multiple indecision candles within a short timespan forming sharp peaks indicate retests, backtests, rejections, and bounces off of support/resistance.
With a correct larger-timeframe channel, one would expect lower-timeframe indecision at/along typical levels.
Although the doji's have unpredictable wicks, the dots printed by this indicator do not. Matched with volume, they reveal the prices where the most violent battles between bulls and bears took place, and are likely to take place, again.
One could:
1) Put trends on the longest segments, then look for confluence along them, and/or near the intersections.
2) Use lower-timeframe doji trends to estimate the direction of the higher-timeframe doji trends, before they become detectable to Doji Trender. Confirm by looking for confluence where those trends intersect with horizontal support/resistance, this indicator, and/or others.
3) Notice that multiple legs on the same trend line are close to parallel, if not colinear.
4) Notice that many of the doji segments point toward (very-distant) future dojis.
5) Drop horizontal lines on the dots where we previously reversed, and find confluence in VRVP when we revisit them.
6) Create parallel (fib/whatever) channels that more-closely match MM's intent. The segments one uses to set the angle of the channel, and those used to align the channel, vertically, are not always the same:
a) Match the channel slope to as many doji slopes as possible, considering every trend.
b) Figure out where the channel actually belongs, re-considering every trend.

SuperTrend AI (Clustering) [LuxAlgo]The SuperTrend AI indicator is a novel take on bridging the gap between the K-means clustering machine learning method & technical indicators. In this case, we apply K-Means clustering to the famous SuperTrend indicator.
🔶 USAGE
Users can interpret the SuperTrend AI trailing stop similarly to the regular SuperTrend indicator. Using higher minimum/maximum factors will return longer-term signals.
The displayed performance metrics displayed on each signal allow for a deeper interpretation of the indicator. Whereas higher values could indicate a higher potential for the market to be heading in the direction of the trend when compared to signals with lower values such as 1 or 0 potentially indicating retracements.
In the image above, we can notice more clear examples of the performance metrics on signals indicating trends, however, these performance metrics cannot perform or predict every signal reliably.
We can see in the image above that the trailing stop and its adaptive moving average can also act as support & resistance. Using higher values of the performance memory setting allows users to obtain a longer-term adaptive moving average of the returned trailing stop.
🔶 DETAILS
🔹 K-Means Clustering
When observing data points within a specific space, we can sometimes observe that some are closer to each other, forming groups, or "Clusters". At first sight, identifying those clusters and finding their associated data points can seem easy but doing so mathematically can be more challenging. This is where cluster analysis comes into play, where we seek to group data points into various clusters such that data points within one cluster are closer to each other. This is a common branch of AI/machine learning.
Various methods exist to find clusters within data, with the one used in this script being K-Means Clustering , a simple iterative unsupervised clustering method that finds a user-set amount of clusters.
A naive form of the K-Means algorithm would perform the following steps in order to find K clusters:
(1) Determine the amount (K) of clusters to detect.
(2) Initiate our K centroids (cluster centers) with random values.
(3) Loop over the data points, and determine which is the closest centroid from each data point, then associate that data point with the centroid.
(4) Update centroids by taking the average of the data points associated with a specific centroid.
Repeat steps 3 to 4 until convergence, that is until the centroids no longer change.
To explain how K-Means works graphically let's take the example of a one-dimensional dataset (which is the dimension used in our script) with two apparent clusters:
This is of course a simple scenario, as K will generally be higher, as well the amount of data points. Do note that this method can be very sensitive to the initialization of the centroids, this is why it is generally run multiple times, keeping the run returning the best centroids.
🔹 Adaptive SuperTrend Factor Using K-Means
The proposed indicator rationale is based on the following hypothesis:
Given multiple instances of an indicator using different settings, the optimal setting choice at time t is given by the best-performing instance with setting s(t) .
Performing the calculation of the indicator using the best setting at time t would return an indicator whose characteristics adapt based on its performance. However, what if the setting of the best-performing instance and second best-performing instance of the indicator have a high degree of disparity without a high difference in performance?
Even though this specific case is rare its however not uncommon to see that performance can be similar for a group of specific settings (this could be observed in a parameter optimization heatmap), then filtering out desirable settings to only use the best-performing one can seem too strict. We can as such reformulate our first hypothesis:
Given multiple instances of an indicator using different settings, an optimal setting choice at time t is given by the average of the best-performing instances with settings s(t) .
Finding this group of best-performing instances could be done using the previously described K-Means clustering method, assuming three groups of interest (K = 3) defined as worst performing, average performing, and best performing.
We first obtain an analog of performance P(t, factor) described as:
P(t, factor) = P(t-1, factor) + α * (∆C(t) × S(t-1, factor) - P(t-1, factor))
where 1 > α > 0, which is the performance memory determining the degree to which older inputs affect the current output. C(t) is the closing price, and S(t, factor) is the SuperTrend signal generating function with multiplicative factor factor .
We run this performance function for multiple factor settings and perform K-Means clustering on the multiple obtained performances to obtain the best-performing cluster. We initiate our centroids using quartiles of the obtained performances for faster centroids convergence.
The average of the factors associated with the best-performing cluster is then used to obtain the final factor setting, which is used to compute the final SuperTrend output.
Do note that we give the liberty for the user to get the final factor from the best, average, or worst cluster for experimental purposes.
🔶 SETTINGS
ATR Length: ATR period used for the calculation of the SuperTrends.
Factor Range: Determine the minimum and maximum factor values for the calculation of the SuperTrends.
Step: Increments of the factor range.
Performance Memory: Determine the degree to which older inputs affect the current output, with higher values returning longer-term performance measurements.
From Cluster: Determine which cluster is used to obtain the final factor.
🔹 Optimization
This group of settings affects the runtime performances of the script.
Maximum Iteration Steps: Maximum number of iterations allowed for finding centroids. Excessively low values can return a better script load time but poor clustering.
Historical Bars Calculation: Calculation window of the script (in bars).

Trend Correlation HeatmapHello everyone!
I am excited to release my trend correlation heatmap, or trend heatmap for short.
Per usual, I think its important to explain the theory before we get into the use of the indicator, so let's get into the theory!
The theory:
So what is a correlation?
Correlation is the relationship one variable has to another. Correlations are the basis of everything I do as a quantitative trader. From the correlation between the same variables (i.e. autocorrelation), the correlation between other variables (i.e. VIX and SPY, SPY High and SPY Low, DXY and ES1! close, etc.) and, as well, the correlation between price and time (time series correlation).
This may sound very familiar to you, especially if you are a user, observer or follower of my ideas and/or indicators. Ninety-five percent of my indicators are a function of one of those three things. Whether it be a time series based indicator (i.e.my time series indicator), whether it be autocorrelation (my autoregressive cloud indicator or my autocorrelation oscillator) or whether it be regressive in nature (i.e. my SPY Volume weighted close, or even my expected move which uses averages in lieu of regressive approaches but is foundational in regression principles. Or even my VIX oscillator which relies on the premise of correlations between tickers.) So correlation is extremely important to me and while its true I am more of a regression trader than anything, I would argue that I am more of a correlation trader, because correlations are the backbone of how I develop math models of stocks.
What I am trying to stress here is the importance of correlations. They really truly are foundational to any type of quantitative analysis for stocks. And as such, understanding the current relationship a stock has to time is pivotal for any meaningful analysis to be conducted.
So what is correlation to time and what does it tell us?
Correlation to time, otherwise known and commonly referred to as "Time Series", is the relationship a ticker's price has to the passing of time. It is displayed in the traditional Pearson Correlation Coefficient or R value and can be any value from -1 (strong negative relationship, i.e. a strong downtrend) to + 1 (i.e. a strong positive relationship, i.e. a strong uptrend). The higher or lower the value the stronger the up or downtrend is.
As such, correlation to time tells us two very important things. These are:
a) The direction of the stock; and
b) The strength of the trend.
Let's take a look at an example:
Above we have a chart of QQQ. We can see a trendline that seems to fit well. The questions we ask as traders are:
1. What is the likelihood QQQ breaks down from this trendline?
2. What is the likelihood QQQ continues up?
3. What is the likelihood QQQ does a false breakdown?
There are numerous mathematical approaches we can take to answer these questions. For example, 1 and 2 can be answered by use of a Cumulative Distribution Density analysis (CDDA) or even a linear or loglinear regression analysis and 3 can be answered, more or less, with a linear regression analysis and standard error ascertainment, or even just a general comparison using a data science approach (such as cosine similarity or Manhattan distance).
But, the reality is, all 3 of these questions can be visualized, at least in some way, by simply looking at the correlation to time. Let's look at this chart again, this time with the correlation heatmap applied:
If we look at the indicator we can see some pivotal things. These are:
1. We have 4, very strong uptrends that span both higher AND lower timeframes. We have a strong uptrend of 0.96 on the 5 minute, 50 candle period. We have a strong uptrend at the 300 candle lookback period on the 1 minute, we have a strong uptrend on the 100 day lookback on the daily timeframe period and we have a strong uptrend on the 5 minute on the 500 candle lookback period.
2. By comparison, we have 3 downtrends, all of which have correlations less than the 4 uptrends. All of the downtrends have a correlation above -0.8 (which we would want lower than -0.8 to be very strong), and all of the uptrends are greater than + 0.80.
3. We can also see that the uptrends are not confined to the smaller timeframes. We have multiple uptrends on multiple timeframes and both short term (50 to 100 candles) and long term (up to 500 candles).
4. The overall trend is strengthening to the upside manifested by a positive Max Change and a Positive Min change (to be discussed later more in-depth).
With this, we can see that QQQ is actually very strong and likely will continue at least some upside. If we let this play out:
We continued up, had one test and then bounced.
Now, I want to specify, this indicator is not a panacea for all trading. And in relation to the 3 questions posed, they are best answered, at least quantitatively, not only by correlation but also by the aforementioned methods (CDDA, etc.) but correlation will help you get a feel for the strength or weakness present with a stock.
What are some tangible applications of the indicator?
For me, this indicator is used in many ways. Let me outline some ways I generally apply this indicator in my day and swing trading:
1. Gauging the strength of the stock: The indictor tells you the most prevalent behavior of the stock. Are there more downtrends than uptrends present? Are the downtrends present on the larger timeframes vs uptrends on the shorter indicating a possible bullish reversal? or vice versa? Are the trends strengthening or weakening? All of these things can be visualized with the indicator.
2. Setting parameters for other indicators: If you trade EMAs or SMAs, you may have a "one size fits all" approach. However, its actually better to adjust your EMA or SMA length to the actual trend itself. Take a look at this:
This is QQQ on the 1 hour with the 200 EMA with 200 standard deviation bands added. If we look at the heatmap, we can see, yes indeed 200 has a fairly strong uptrend correlation of 0.70. But the strongest hourly uptrend is actually at 400 candles, with a correlation of 0.91. So what happens if we change the EMA length and standard deviation to 400? This:
The exact areas are circled and colour coded. You can see, the 400 offers more of a better reference point of supports and resistances as well as a better overall trend fit. And this is why I never advocate for getting married to a specific EMA. If you are an EMA 200 lover or 21 or 51, know that these are not always the best depending on the trend and situation.
Components of the indicator:
Ah okay, now for the boring stuff. Let's go over the functionality of the indicator. I tried to keep it simple, so it is pretty straight forward. If we open the menu here are our options:
We have the ability to toggle whichever timeframes we want. We also have the ability to toggle on or off the legend that displays the colour codes and the Max and Min highest change.
Max and Min highest change: The max and min highest change simply display the change in correlation over the previous 14 candles. An increasing Max change means that the Max trend is strengthening. If we see an increasing Max change and an increasing Min change (the Min correlation is moving up), this means the stock is bullish. Why? Because the min (i.e. ideally a big negative number) is going up closer to the positives. Therefore, the downtrend is weakening.
If we see both the Max and Min declining (red), that means the uptrend is weakening and downtrend is strengthening. Here are some examples:
Final Thoughts:
And that is the indicator and the theory behind the indicator.
In a nutshell, to summarize, the indicator simply tracks the correlation of a ticker to time on multiple timeframes. This will allow you to make judgements about strength, sentiment and also help you adjust which tools and timeframes you are using to perform your analyses.
As well, to make the indicator more user friendly, I tried to make the colours distinctively different. I was going to do different shades but it was a little difficult to visualize. As such, I have included a toggle-able legend with a breakdown of the colour codes!
That's it my friends, I hope you find it useful!
Safe trades and leave your questions, comments and feedback below!

Supply and Demand Based Pattern [RH]This indicator focuses on detecting RBR and DBD patterns, which signify periods of increased momentum and potential continuation or reversal of the prevailing trend.
The RBR pattern consists of a rally (upward movement), followed by a base (consolidation or retracement), and then another rally. It suggests that the upward momentum may persist and provide trading opportunities.
On the other hand, the DBD pattern comprises a drop (downward movement), followed by a base, and then another drop. It indicates that the downward momentum might continue, offering potential shorting opportunities.
Bullish(RBR) example:
Bearish(DBD) example:
1. The bullish (RBR) and bearish (DBD) patterns share the same underlying logic, only differing in their directionality.
2. For both RBR and DBD patterns, the first rise/drop can consist of one or multiple candles. However, in the case of multiple candles, all candles must exhibit a bullish nature for RBR and a bearish nature for DBD.
Example:
3. It is a prerequisite for the first rise/drop to include at least one candle with a defined percentage of health, as determined by the user.
4. The base, following the first rise/drop, may comprise one or multiple candles.
Example:
5. To maintain consistency, the base is not allowed to retrace beyond 80%, although this value can be adjusted by the user.
6. Similar to the first rise/drop, the second rise/drop in both RBR and DBD patterns can consist of one or multiple candles. However, all candles within this phase must demonstrate a bullish nature for RBR and a bearish nature for DBD.
7. Confirmation of the bullish (RBR) pattern occurs when a candle closes above the high of the first rise. Conversely, the bearish (DBD) pattern is confirmed when a candle closes below the low of the first drop.
Example:
Alerts can be set for all bullish and bearish pattern or for the first pattern in the range of similar pattern.
[DisDev] D-I-Y Gridbot🟩 This script is a “do-it-yourself” Grid Bot Simulator, used for visualizing support and resistance levels. Prices are divided into grids, or trade zones, that will trigger signals each time a new zone is entered. During ranging markets, each transaction is followed by a “take profit.” As the market starts to trend, transactions are stacked (compare to DCA ), until the market consolidates. No signals are triggered above the upper gridline or below the lower gridline. Unlike the previous version, all grids may be adjusted in real-time by dragging the gridlines up and down to the desired support and resistance levels.
When adding the indicator to a new chart, you must choose six grid levels by clicking on the desired support or resistance price. You can change all of these levels at any time directly on the chart.
⚡ OVERVIEW ⚡
The D-I-Y Gridbot is an interactive tool designed for visualizing support and resistance levels. As a continuation of the original Gridbot Simulator , which has received significant recognition on TradingView, earning over 4000 boosts and an Editor's Pick status. This tool serves not only as an evolved version of its predecessor, but also as an open-source template for developing future gridbots. It aims to foster discussions and facilitate innovations around grid-trading strategies.
One of the new features of this gridbot is the real-time adjustability of all gridlines. Users can move these lines up and down to set their desired support and resistance levels in response to changing market conditions. Additionally, the D-I-Y Gridbot is compatible with multiple timeframes and can be used on most TradingView charts.
Drag gridlines up or down to desired price level.
Key Features 🔑
All gridlines are adjustable in real-time, directly on the chart
Signals can be filtered by a customizable moving average or by VWAP
Customizable support and resistance levels
Potentially increases profitability in ranging markets
Benefits 💸
Customizable Support and Resistance Levels : The D-I-Y Gridbot allows users to set their preferred support and resistance levels, which can be changed at any time directly on the chart. This provides users with the ability to customize their trading parameters based on their strategy and risk tolerance.
Various Trading Strategies : The D-I-Y Gridbot supports various trading strategies, including Mean Reversion, Ranging Markets, and Dollar-cost averaging (DCA). This allows users to capitalize on price reversals, execute buy and sell orders at predetermined levels, and buy more of an asset as the price falls, respectively.
Multi-Timeframe and Versatility : The D-I-Y Gridbot is compatible with multiple timeframes and can be used on any TradingView chart.
Experimental and Educational : The D-I-Y Gridbot is considered a proof-of-concept tool that is both experimental and educational. This can provide traders with a deeper understanding of grid trading strategies and the ability to experiment with different trading parameters and strategies.
⚙️ CONFIGURATION & SETTINGS ⚙️
Inputs 🔧
Trigger : Candle location to trigger the signal. "Wick" will use either high or low, depending on the signal direction. "Close" will use the close price. “MA” will use the selected moving average or VWAP.
Confirmation : Market direction to confirm the candle trigger. "Reverse" will confirm the signal when the price crosses back over the trigger. "Breakout" will confirm when the price breaks out of the trigger.
Number of Support/Resistance zones : 1 = Only Top Grid is Support/Only Bottom Grid is Resistance. 2 = Top two grids are Resistance/Bottom two grids are Support. 3 = Top three grids are Resistance/Bottom three grids are Support
MA Type : Exponential Moving Average (EMA), Hull Moving Average (HMA), Simple Moving Average (SMA), Triple Exponential Moving Average (TEMA), Volume Weighted Moving Average (VWMA), Volume Weighted Average Price (VWAP)
MA Filter : Use Moving Average as a reversion filter for signals. When enabled, no buys when above MA, no sells when below. Use in conjunction with S/R zones to reduce false signals.
Allow Repeat Signals . When enabled, signals will reset when nearest gridline is triggered. When disabled, only one signal will be triggered per gridline.
Line/Fill colors
Gridlines . Adjusts gridline prices manually.
Left : Trigger = Wick. Confirm = Breakout. Buys are signaled when LOW breaks below gridline. Sells are triggered when HIGH breaks above gridline.
Right : Trigger = Close. Confirm = Breakout. Buys are signaled when the candle CLOSES below the gridline. Sells are triggered when the candle CLOSES above the gridline.
Left : Confirm=Breakout. Signals on breaking through the next gridline.
Right : Confirm=Reverse. Signals only when crossing back from the gridline.
S/R Zones=1. Upper gridline is Resistance / Lower is Support. Middle 4 are neutral.
S/R Zones = 3. Upper three gridlines are Resistance / Lower three are Support
Notes:
If gridlines are dragged out of order on a live chart, they will auto-sort into the correct order.
Price levels may be entered in settings, or adjusted in real-time directly on the chart.
When changing symbols, remember to adjust the gridlines to accommodate the new symbol.
Alerts 🔔
Users can set alerts based on their chosen parameters for triggers, confirmations, number of support/resistance zones, and smoothing type, enabling precise control over alert conditions.
💡 USAGE & STRATEGY 💡
Trading Strategies 📈
Mean Reversion: The script can be used to capitalize on price reversals back to the mean.
Ranging Markets: The script excels in ranging markets, executing buy and sell orders at predetermined levels.
Dollar-cost averaging (DCA): The script can be used to execute DCA orders, buying more of an asset as the price falls, and lowering the average cost per unit.
Timeframes and Symbols ⌚
Multi-Timeframe: The indicator is compatible with multiple timeframes.
Versatile: Can be used on any crypto trading pair on TradingView.
🤖 DETAILS & METHODOLOGY 🤖
Algorithm and Calculation 🛡️
Grids are set and adjusted when loading the indicator on the chart and may be customized anytime afterward by clicking and dragging the gridlines on the chart.
Gridlines are updated, sorted, and stored in a float array.
Signals are calculated based on candle trigger, market direction, and previous price level.
📚 ADDITIONAL RESOURCES 📚
Chart Examples 📊
S/R Zones = 3: Three Support and Three Resistance. Filter = 50-period Triple Exponential Moving Average (TEMA)
S/R Zones = 1: One Support, One Resistance, and Four Neutral Zones. Support Zones: Buys only. Resistance Zones: Sells only. Neutral Zones: Grid-dependent
When MA filter is enabled, Buys are only triggered below Moving Average, and Sells are only triggered above.
Trigger = Wick. Confirmation = Breakout. Buys are signaled when Low breaks above the next grid level. Sells are signaled when High breaks below the next grid level.
🚀 CONCLUSION 🚀
The D-I-Y Gridbot is a proof-of-concept, emphasizing its experimental and educational nature. In future versions, we will aim to incorporate concepts such as auto-adjusting grids and angled grids for trending markets. The script is designed to evolve through user feedback and suggestions, shaping its future iterations.
Credit: This is a continuation of the Gridbot series by xxattaxx-DisDev . Explicit permission was granted by user xxattaxx-disdev to re-use all Gridbot code and all materials without restrictions.
⚠️ DISCLAIMER ⚠️
This indicator is a proof-of-concept and is considered experimental and educational. When gridlines are drawn in hindsight, signals appear to be predictive and valid. Future results may always vary when the trend direction changes. Comments and suggestions are encouraged.
This indicator is provided as a tool for traders and should not be used as the sole basis for making trading decisions. Always conduct your own research and consider your risk tolerance before entering any trades.
Double Top Patterns [theEccentricTrader]█ OVERVIEW
This indicator automatically draws double top patterns and price projections derived from the ranges that constitute the patterns.
█ CONCEPTS
Green and Red Candles
• A green candle is one that closes with a close price equal to or above the price it opened.
• A red candle is one that closes with a close price that is lower than the price it opened.
Swing Highs and Swing Lows
• A swing high is a green candle or series of consecutive green candles followed by a single red candle to complete the swing and form the peak.
• A swing low is a red candle or series of consecutive red candles followed by a single green candle to complete the swing and form the trough.
Peak and Trough Prices (Basic)
• The peak price of a complete swing high is the high price of either the red candle that completes the swing high or the high price of the preceding green candle, depending on which is higher.
• The trough price of a complete swing low is the low price of either the green candle that completes the swing low or the low price of the preceding red candle, depending on which is lower.
Historic Peaks and Troughs
The current, or most recent, peak and trough occurrences are referred to as occurrence zero. Previous peak and trough occurrences are referred to as historic and ordered numerically from right to left, with the most recent historic peak and trough occurrences being occurrence one.
Broken and Unbroken Peaks and Troughs
Upon the completion of a new swing low the high of the green candle that completes the swing low will be above, below or equal to the current peak price. And similarly, upon the completion of a new swing high the low of the red candle that completes the swing high will be above, below or equal to the current trough price.
If the high price of the green candle that completes the current swing low is higher than or equal to the current peak price then the current peak is broken. If the high of the green candle that completes the current swing low is below the current peak price, then the current peak is unbroken.
Similarly, if the low price of the red candle that completes the current swing high is lower than or equal to the current trough price then the current trough is broken. If the low price of the red candle that completes the current swing high is above the current trough price, then the current trough is unbroken.
Range
The range is simply the difference between the current peak and current trough prices, generally expressed in terms of points or pips.
Retracement and Extension Ratios
Retracement and extension ratios are calculated by dividing the current range by the preceding range and multiplying the answer by 100. Retracement ratios are those that are equal to or below 100% of the preceding range and extension ratios are those that are above 100% of the preceding range.
Double Bottom and Double Top Patterns
• Double bottom patterns are composed of one peak and two troughs, with the second trough being roughly equal to the first trough.
• Double top patterns are composed of one trough and two peaks, with the second peak being roughly equal to the first peak.
Measurement Tolerances
In general, tolerance in measurements refers to the allowable variation or deviation from a specific value or dimension. It is the range within which a particular measurement is considered to be acceptable or accurate. In this script I have applied this concept to the measurement of double bottom and double top patterns to increase to the frequency of pattern occurrences.
For example, a perfect double bottom is very rare. We can increase the frequency of pattern occurrences by setting a tolerance. A ratio tolerance of 10% to both downside and upside, which is the default setting, means we would have a tolerable ratio measurement range between 90-110% for the second trough, thus increasing the frequency of occurrence.
█ FEATURES
Inputs
• Unbroken Troughs
• Lower Tolerance
• Upper Tolerance
• Pattern Color
• Neckline Color
• Extend Current Neckline
• Show Labels
• Label Color
• Show Projection Lines
• Extend Current Projection Lines
Alerts
Users can set alerts for when the patterns occur.
█ LIMITATIONS
All green and red candle calculations are based on differences between open and close prices, as such I have made no attempt to account for green candles that gap lower and close below the close price of the preceding candle, or red candles that gap higher and close above the close price of the preceding candle. This may cause some unexpected behaviour on some markets and timeframes. I can only recommend using 24-hour markets, if and where possible, as there are far fewer gaps and, generally, more data to work with.