OPEN-SOURCE SCRIPT
Telah dikemas kini KNN Regression [SS]
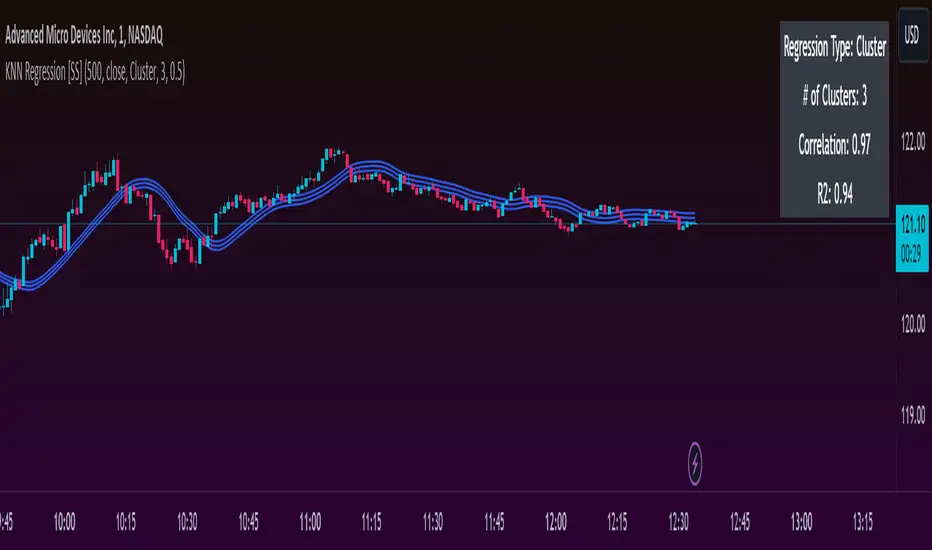
Another indicator release, I know.
But note, this isn't intended to be a stand-alone indicator, this is just a functional addition for those who program Machine Learning algorithms in Pinescript! There isn't enough content here to merit creating a library for (it's only 1 function), but it's a really useful function for those who like machine learning and Nearest Known Neighbour Algos (or KNN).
About the indicator:
This indicator creates a function to perform KNN-based regression.
In contrast to traditional linear regression, KNN-based regression has the following advantages over linear regression:
Advantages of KNN Regression vs. Linear Regression:
🎯 Non-linearity: KNN is a non-parametric method, meaning it makes no assumptions about the underlying data distribution. This allows it to capture non-linear relationships between features and the target variable.
🎯Simple Implementation: KNN is conceptually simple and easy to understand. It doesn't require the estimation of parameters, making it straightforward to implement.
🎯Robust to Outliers: KNN is less sensitive to outliers compared to linear regression. Outliers can have a significant impact on linear regression models, but KNN tends to be less affected.
Disadvantages of KNN Regression vs. Linear Regression:
🎯 Resource Intensive for Computation: Because KNN operates on identifying the nearest neighbors in a dataset, each new instance has to be searched for and identified within the dataset, vs. linear regression which can create a coefficient-based model and draw from the coefficient for each new data point.
🎯Curse of Dimensionality: KNN performance can degrade with an increasing number of features, leading to a "curse of dimensionality." This is because, in high-dimensional spaces, the concept of proximity becomes less meaningful.
🎯Sensitive to Noise: KNN can be sensitive to noisy data, as it relies on the local neighborhood for predictions. Noisy or irrelevant features may affect its performance.
Which is better?
I am very biased, coming from a statistics background. I will always love linear regression and will always prefer it over KNN. But depending on what you want to accomplish, KNN makes sense. If you are using highly skewed data or data that you cannot identify linearity in, KNN is probably preferable.
However, if you require precise estimations of ranges and outliers, such as creating co-integration models, I would advise sticking with linear regression. However, out of curiosity, I exported the function into a separate dummy indicator and pulled in data from QQQ to predict SPY close, and the results are actually very admirable:

And plotted with showing the standard error variance:

Pretty impressive, I must say I was a little shocked, it's really giving linear regression a run for its money. In school I was taught LinReg is the gold standard for modeling, nothing else compares. So as with most things in trading, this is challenging some biases of mine ;).
Functionality of the function
I have permitted 3 types of KNN regression. Traditional KNN regression, as I understand it, revolves around clustering. (Clustering refers to identifying a cluster, normally 3, of identical cases and averaging out the Dependent variable in each of those cases). Clustering is great, but when you are working with a finite dataset, identifying exact matches for 2 or 3 clusters can be challenging when you are only looking back at 500 candles or 1000 candles, etc.
So to accommodate this, I have added a functionality to clustering called "Tolerance". And it allows you to set a tolerance level for your Euclidean distance parameters. As a default, I have tested this with a default of 0.5 and it has worked great and no need to change even when working with large numbers such as NQ and ES1!.
However, I have added 2 additional regression types that can be done with KNN.
#1 One is a regression by the last IDENTICAL instance, which will find the most recent instance of a similar Independent variable and pull the Dependent variable from that instance. Or
#2 Average from all IDENTICAL instances.
Using the function
The code has the instructions for integrating the function into your own code, the parameters, and such, so I won't exhaust you with the boring details about that here.
But essentially, it exports 3, float variables, the Result, the Correlation, and the simplified R2.
As this is KNN regression, there are no coefficients, slopes, or intercepts and you do not need to test for linearity before applying it.
Also, the output can be a bit choppy, so I tend to like to throw in a bit of smoothing using the ta.sma function at a deault of 14.
For example, here is SPY from QQQ smoothed as a 14 SMA:

And it is unsmoothed:

It seems relatively similar but it does make a bit of an aesthetic difference. And if you are doing it over 14, there is no data loss and it is still quite reactive to changes in data.
And that's it! Hopefully you enjoy and find some interesting uses for this function in your own scripts :-).
Safe trades everyone!
But note, this isn't intended to be a stand-alone indicator, this is just a functional addition for those who program Machine Learning algorithms in Pinescript! There isn't enough content here to merit creating a library for (it's only 1 function), but it's a really useful function for those who like machine learning and Nearest Known Neighbour Algos (or KNN).
About the indicator:
This indicator creates a function to perform KNN-based regression.
In contrast to traditional linear regression, KNN-based regression has the following advantages over linear regression:
Advantages of KNN Regression vs. Linear Regression:
🎯 Non-linearity: KNN is a non-parametric method, meaning it makes no assumptions about the underlying data distribution. This allows it to capture non-linear relationships between features and the target variable.
🎯Simple Implementation: KNN is conceptually simple and easy to understand. It doesn't require the estimation of parameters, making it straightforward to implement.
🎯Robust to Outliers: KNN is less sensitive to outliers compared to linear regression. Outliers can have a significant impact on linear regression models, but KNN tends to be less affected.
Disadvantages of KNN Regression vs. Linear Regression:
🎯 Resource Intensive for Computation: Because KNN operates on identifying the nearest neighbors in a dataset, each new instance has to be searched for and identified within the dataset, vs. linear regression which can create a coefficient-based model and draw from the coefficient for each new data point.
🎯Curse of Dimensionality: KNN performance can degrade with an increasing number of features, leading to a "curse of dimensionality." This is because, in high-dimensional spaces, the concept of proximity becomes less meaningful.
🎯Sensitive to Noise: KNN can be sensitive to noisy data, as it relies on the local neighborhood for predictions. Noisy or irrelevant features may affect its performance.
Which is better?
I am very biased, coming from a statistics background. I will always love linear regression and will always prefer it over KNN. But depending on what you want to accomplish, KNN makes sense. If you are using highly skewed data or data that you cannot identify linearity in, KNN is probably preferable.
However, if you require precise estimations of ranges and outliers, such as creating co-integration models, I would advise sticking with linear regression. However, out of curiosity, I exported the function into a separate dummy indicator and pulled in data from QQQ to predict SPY close, and the results are actually very admirable:
And plotted with showing the standard error variance:
Pretty impressive, I must say I was a little shocked, it's really giving linear regression a run for its money. In school I was taught LinReg is the gold standard for modeling, nothing else compares. So as with most things in trading, this is challenging some biases of mine ;).
Functionality of the function
I have permitted 3 types of KNN regression. Traditional KNN regression, as I understand it, revolves around clustering. (Clustering refers to identifying a cluster, normally 3, of identical cases and averaging out the Dependent variable in each of those cases). Clustering is great, but when you are working with a finite dataset, identifying exact matches for 2 or 3 clusters can be challenging when you are only looking back at 500 candles or 1000 candles, etc.
So to accommodate this, I have added a functionality to clustering called "Tolerance". And it allows you to set a tolerance level for your Euclidean distance parameters. As a default, I have tested this with a default of 0.5 and it has worked great and no need to change even when working with large numbers such as NQ and ES1!.
However, I have added 2 additional regression types that can be done with KNN.
#1 One is a regression by the last IDENTICAL instance, which will find the most recent instance of a similar Independent variable and pull the Dependent variable from that instance. Or
#2 Average from all IDENTICAL instances.
Using the function
The code has the instructions for integrating the function into your own code, the parameters, and such, so I won't exhaust you with the boring details about that here.
But essentially, it exports 3, float variables, the Result, the Correlation, and the simplified R2.
As this is KNN regression, there are no coefficients, slopes, or intercepts and you do not need to test for linearity before applying it.
Also, the output can be a bit choppy, so I tend to like to throw in a bit of smoothing using the ta.sma function at a deault of 14.
For example, here is SPY from QQQ smoothed as a 14 SMA:
And it is unsmoothed:
It seems relatively similar but it does make a bit of an aesthetic difference. And if you are doing it over 14, there is no data loss and it is still quite reactive to changes in data.
And that's it! Hopefully you enjoy and find some interesting uses for this function in your own scripts :-).
Safe trades everyone!
Nota Keluaran
Modified some things to make the indicator more usable as a standalone indicator and also adjusted the cluster type. I did testing mostly on ES1! and SPY, but in looking at bigger tickers like YM1! it fares better with a larger tolerance.I had to check to be sure that increasing the tolerance does not skew across tickers and it indeed does not 🤯.
In terms of functionality, I have now added the ability to toggle off and on the outerbands, as well as the ability to smooth or unsmooth the indicator. And additionally, I have permitted it to allow external tickers to be imported and do a regression comparison.
It just overall gives the demo some more practical functionality and applications.
I hope you enjoy!
Nota Keluaran
Noticed a slight error in the regression logic.Fixed.
Skrip sumber terbuka
Dalam semangat TradingView sebenar, pencipta skrip ini telah menjadikannya sumber terbuka, jadi pedagang boleh menilai dan mengesahkan kefungsiannya. Terima kasih kepada penulis! Walaupuan anda boleh menggunakan secara percuma, ingat bahawa penerbitan semula kod ini tertakluk kepada Peraturan Dalaman.
Get:
- Live Updates,
- Discord access,
- Access to my Proprietary Merlin Software,
- Access to premium indicators,
patreon.com/steversteves
Now on X!
- Live Updates,
- Discord access,
- Access to my Proprietary Merlin Software,
- Access to premium indicators,
patreon.com/steversteves
Now on X!
Penafian
Maklumat dan penerbitan adalah tidak bertujuan, dan tidak membentuk, nasihat atau cadangan kewangan, pelaburan, dagangan atau jenis lain yang diberikan atau disahkan oleh TradingView. Baca lebih dalam Terma Penggunaan.
Skrip sumber terbuka
Dalam semangat TradingView sebenar, pencipta skrip ini telah menjadikannya sumber terbuka, jadi pedagang boleh menilai dan mengesahkan kefungsiannya. Terima kasih kepada penulis! Walaupuan anda boleh menggunakan secara percuma, ingat bahawa penerbitan semula kod ini tertakluk kepada Peraturan Dalaman.
Get:
- Live Updates,
- Discord access,
- Access to my Proprietary Merlin Software,
- Access to premium indicators,
patreon.com/steversteves
Now on X!
- Live Updates,
- Discord access,
- Access to my Proprietary Merlin Software,
- Access to premium indicators,
patreon.com/steversteves
Now on X!
Penafian
Maklumat dan penerbitan adalah tidak bertujuan, dan tidak membentuk, nasihat atau cadangan kewangan, pelaburan, dagangan atau jenis lain yang diberikan atau disahkan oleh TradingView. Baca lebih dalam Terma Penggunaan.