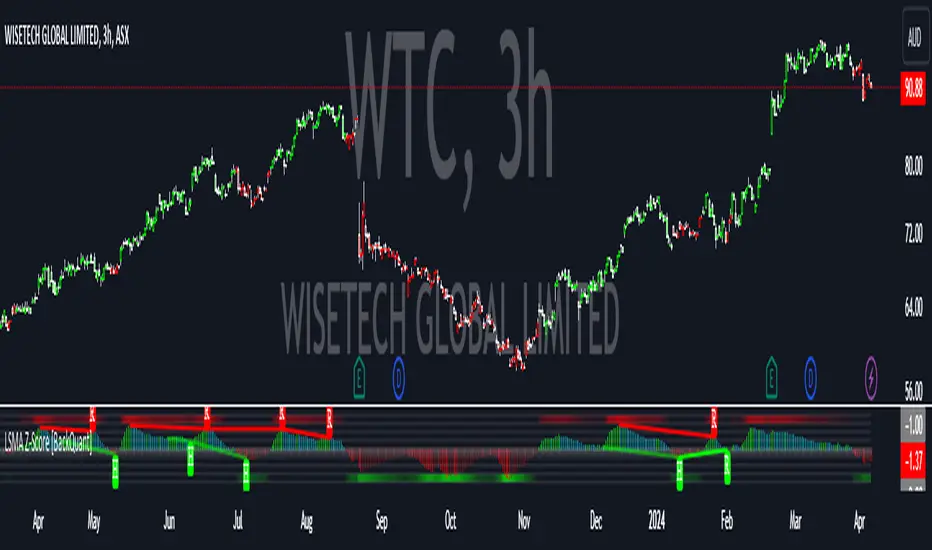
LSMA Z-Score [BackQuant]LSMA Z-Score
Main Features and Use in the Trading Strategy
- The indicator normalizes the LSMA into a detrended Z-Score, creating an oscillator with standard deviation levels to indicate trend strength.
- Adaptive coloring highlights the rate of change and potential reversals, with different colors for positive and negative changes above and below the midline.
- Extreme levels with adaptive coloring indicate the probability of a reversion, providing strategic entry or exit points.
- Alert conditions for crossing the midline or significant shifts in trend direction enhance its utility within a trading strategy.
1. What is an LSMA?
The Least Squares Moving Average (LSMA) is a technical indicator that smoothens price data to help identify trends. It uses the least squares regression method to fit a straight line through the selected price points over a specified period. This approach minimizes the sum of the squares of the distances between the line and the price points, providing a more statistically grounded moving average that can adapt more smoothly to price changes.
2. What is a Z-Score?
A Z-Score is a statistical measurement that describes a value's relationship to the mean of a group of values, measured in terms of standard deviations from the mean. If a Z-Score is 0, it indicates that the data point's score is identical to the mean score. A Z-Score helps in understanding if a data point is typical for a given data set or if it is atypical. In finance, a Z-Score is often used to measure how far a piece of data is from the average of a set, which can be helpful in identifying outliers or unusual data points.
3. Why Turning LSMA into a Z-Score is Innovative and Its Benefits
Converting LSMA into a Z-Score is innovative because it combines the trend identification capabilities of the LSMA with the statistical significance testing of Z-Scores. This transformation normalizes the LSMA, creating a detrended oscillator that oscillates around a mean (zero line), with standard deviation levels to show trend strength. This method offers several benefits:
Enhanced Trend Detection:
- By normalizing the LSMA, traders can more easily identify when the price is deviating significantly from its trend, which can signal potential trading opportunities.
Standardization:
- The Z-Score transformation allows for comparisons across different assets or time frames, as the score is standardized.
Objective Measurement of Trend Strength:
- The use of standard deviation levels provides an objective measure of trend strength and volatility.
4. How It Can Be Used in the Context of a Trading System
This indicator can serve as a versatile tool within a trading system for a range of things:
Trend Confirmation:
- A positive Z-Score can confirm an uptrend, while a negative Z-Score can confirm a downtrend, providing traders with signals to enter or exit trades.
Oversold/Overbought Conditions:
- Extreme Z-Score levels can indicate overbought or oversold conditions, suggesting potential reversals or pullbacks.
Volatility Assessment:
- The standard deviation levels can help traders assess market volatility, with wider bands indicating higher volatility.
5. How It Can Be Used for Trend Following
For trend following strategies, this indicator can be particularly useful:
Trend Strength Indicator:
- By monitoring the Z-Score's distance from zero, traders can gauge the strength of the current trend, with larger absolute values indicating stronger trends.
Directional Bias:
- Positive Z-Scores can be used to establish a bullish bias, while negative Z-Scores can establish a bearish bias, guiding trend following entries and exits.
Color-Coding for Trend Changes :
- The adaptive coloring of the indicator based on the rate of change and extreme levels provides visual cues for potential trend reversals or continuations.
Thus following all of the key points here are some sample backtests on the 1D Chart
Disclaimer: Backtests are based off past results, and are not indicative of the future.
This is using the Midline Crossover:
INDEX:BTCUSD
INDEX:ETHUSD
BINANCE:SOLUSD
Leastsquares
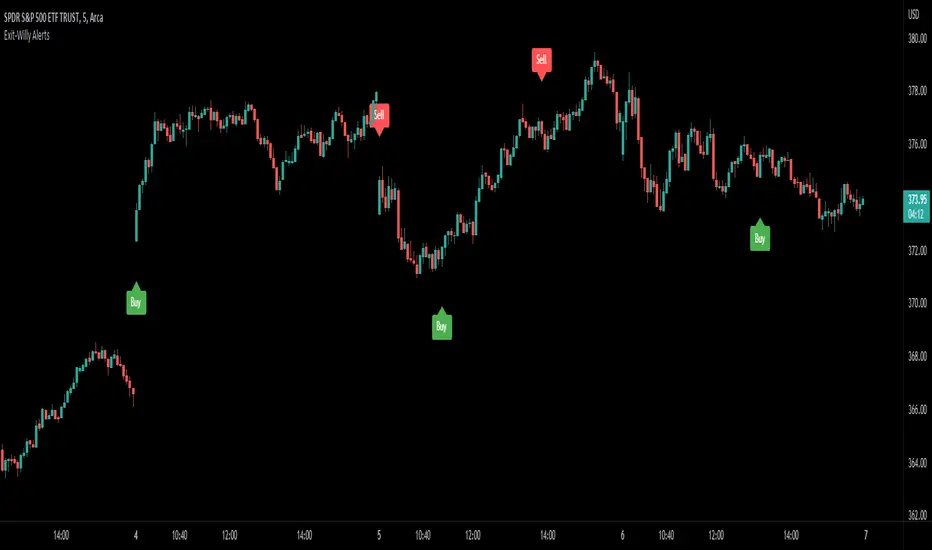
Exit-Willy AlertsThis is the Exit-Willy indicator. It issues Buy and Sell signals based on exit data from different moving averages and the Williams Percent R. It also has a LSMA filter. All values are adjustable. I like to use it with a higher Exit value being as it filters some of the false signals. There are multiple different settings to change and alter.
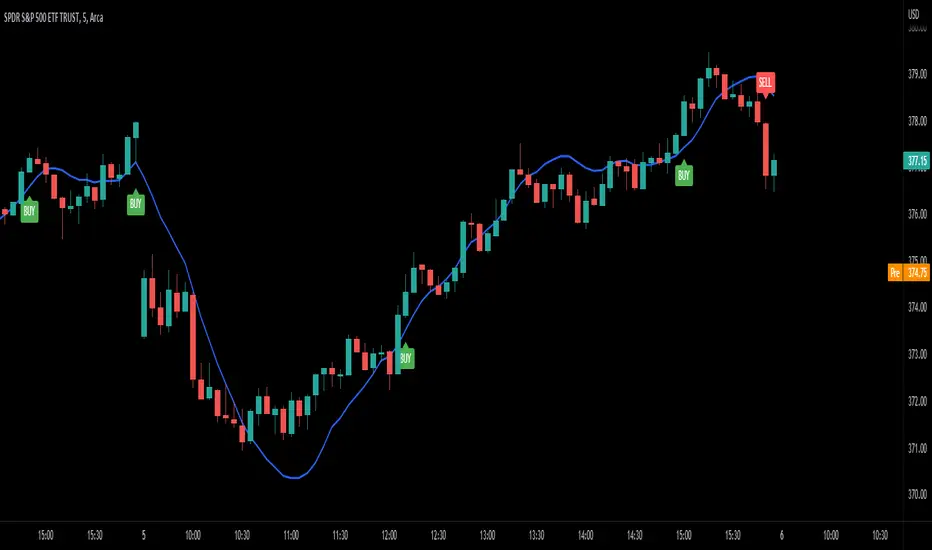
Channel SurfingThis is my Channel Surfing indicator. It fires Buy and Sell signals based on multiple conditions. You can use EMAs or LSMAs. You will have to check the box of which moving averages to use once you add it to the chart. It plots EMAs or LSMAs using the different sources Close, Low, and High as the channel to surf. It fires a Buy signal if price crosses the channel up and if there is a pullback into the channel followed by a breakout to the upside. It fires a Sell signal if price crosses the channel down and if there is a pullback into the channel followed buy a breakdown to the down side. I find it works great on the 5 minute SPY chart and the 1 minute chart of ES with the default settings when scalping. You are able to switch between 2 different channels using LSMAs or EMAs. The EMAs has an optional LSMA slope filter for getting rid of some false signals. Let me know if you guys find any other settings or ways to use this and as always I hope it helps.

Olympus MonsThis is the Olympus Mons indicator. It uses Braid Filter, LSMA, and Hawkeye Volume to fire Buy and Sell signals. I use this on the 5 Min. SPY chart to play 1 point scalp targets with options. I have been able to get a pretty consistent win rate using it like this. The default settings are what I use. Hope it helps any of you guys. Let me know if you see any settings that are better.
Fourier Extrapolator of Price w/ Projection Forecast [Loxx]Due to popular demand, I'm pusblishing Fourier Extrapolator of Price w/ Projection Forecast.. As stated in it's twin indicator, this one is also multi-harmonic (or multi-tone) trigonometric model of a price series xi, i=1..n, is given by:
xi = m + Sum( a*Cos(w*i) + b*Sin(w*i), h=1..H )
Where:
xi - past price at i-th bar, total n past prices;
m - bias;
a and b - scaling coefficients of harmonics;
w - frequency of a harmonic ;
h - harmonic number;
H - total number of fitted harmonics.
Fitting this model means finding m, a, b, and w that make the modeled values to be close to real values. Finding the harmonic frequencies w is the most difficult part of fitting a trigonometric model. In the case of a Fourier series, these frequencies are set at 2*pi*h/n. But, the Fourier series extrapolation means simply repeating the n past prices into the future.
This indicator uses the Quinn-Fernandes algorithm to find the harmonic frequencies. It fits harmonics of the trigonometric series one by one until the specified total number of harmonics H is reached. After fitting a new harmonic , the coded algorithm computes the residue between the updated model and the real values and fits a new harmonic to the residue.
see here: A Fast Efficient Technique for the Estimation of Frequency , B. G. Quinn and J. M. Fernandes, Biometrika, Vol. 78, No. 3 (Sep., 1991), pp . 489-497 (9 pages) Published By: Oxford University Press
The indicator has the following input parameters:
src - input source
npast - number of past bars, to which trigonometric series is fitted;
Nfut - number of predicted future bars;
nharm - total number of harmonics in model;
frqtol - tolerance of frequency calculations.
The indicator plots two curves: the green/red curve indicates modeled past values and the yellow/fuchsia curve indicates the modeled future values.
The purpose of this indicator is to showcase the Fourier Extrapolator method to be used in future indicators.

Fourier Extrapolator of Price [Loxx]Fourier Extrapolator of Price is a multi-harmonic (or multi-tone) trigonometric model of a price series xi, i=1..n, is given by:
xi = m + Sum( a *Cos(w *i) + b *Sin(w *i), h=1..H )
Where:
xi - past price at i-th bar, total n past prices;
m - bias;
a and b - scaling coefficients of harmonics;
w - frequency of a harmonic;
h - harmonic number;
H - total number of fitted harmonics.
Fitting this model means finding m, a , b , and w that make the modeled values to be close to real values. Finding the harmonic frequencies w is the most difficult part of fitting a trigonometric model. In the case of a Fourier series, these frequencies are set at 2*pi*h/n. But, the Fourier series extrapolation means simply repeating the n past prices into the future.
This indicator uses the Quinn-Fernandes algorithm to find the harmonic frequencies. It fits harmonics of the trigonometric series one by one until the specified total number of harmonics H is reached. After fitting a new harmonic, the coded algorithm computes the residue between the updated model and the real values and fits a new harmonic to the residue.
see here: A Fast Efficient Technique for the Estimation of Frequency , B. G. Quinn and J. M. Fernandes, Biometrika, Vol. 78, No. 3 (Sep., 1991), pp. 489-497 (9 pages) Published By: Oxford University Press
The indicator has the following input parameters:
src - input source
npast - number of past bars, to which trigonometric series is fitted;
nharm - total number of harmonics in model;
frqtol - tolerance of frequency calculations.
The indicator plots the modeled past values
The purpose of this indicator is to showcase the Fourier Extrapolator method to be used in future indicators. While this method can also prediction future price movements, for our purpose here we will avoid doing.

Poly Cycle [Loxx]This is an example of what can be done by combining Legendre polynomials and analytic signals. I get a way of determining a smooth period and relative adaptive strength indicator without adding time lag.
This indicator displays the following:
The Least Squares fit of a polynomial to a DC subtracted time series - a best fit to a cycle.
The normalized analytic signal of the cycle (signal and quadrature).
The Phase shift of the analytic signal per bar.
The Period and HalfPeriod lengths, in bars of the current cycle.
A relative strength indicator of the time series over the cycle length. That is, adaptive relative strength over the cycle length.
The Relative Strength Indicator, is adaptive to the time series, and it can be smoothed by increasing the length of decreasing the number of degrees of freedom.
Other adaptive indicators based upon the period and can be similarly constructed.
There is some new math here, so I have broken the story up into 5 Parts:
Part 1:
Any time series can be decomposed into a orthogonal set of polynomials .
This is just math and here are some good references:
Legendre polynomials - Wikipedia, the free encyclopedia
Peter Seffen, "On Digital Smoothing Filters: A Brief Review of Closed Form Solutions and Two New Filter Approaches", Circuits Systems Signal Process, Vol. 5, No 2, 1986
I gave some thought to what should be done with this and came to the conclusion that they can be used for basic smoothing of time series. For the analysis below, I decompose a time series into a low number of degrees of freedom and discard the zero mode to introduce smoothing.
That is:
time series => c_1 t + c_2 t^2 ... c_Max t^Max
This is the cycle. By construction, the cycle does not have a zero mode and more physically, I am defining the "Trend" to be the zero mode.
The data for the cycle and the fit of the cycle can be viewed by setting
ShowDataAndFit = TRUE;
There, you will see the fit of the last bar as well as the time series of the leading edge of the fits. If you don't know what I mean by the "leading edge", please see some of the postings in . The leading edges are in grayscale, and the fit of the last bar is in color.
I have chosen Length = 17 and Degree = 4 as the default. I am simply making sure by eye that the fit is reasonably good and degree 4 is the lowest polynomial that can represent a sine-like wave, and 17 is the smallest length that lets me calculate the Phase Shift (Part 3 below) using the Hilbert Transform of width=7 (Part 2 below).
Depending upon the fit you make, you will capture different cycles in the data. A fit that is too "smooth" will not see the smaller cycles, and a fit that is too "choppy" will not see the longer ones. The idea is to use the fit to try to suppress the smaller noise cycles while keeping larger signal cycles.
Part 2:
Every time series has an Analytic Signal, defined by applying the Hilbert Transform to it. You can think of the original time series as amplitude * cosine(theta) and the transformed series, called the quadrature, can be thought of as amplitude * sine(theta). By taking the ratio, you can get the angle theta, and this is exactly what was done by John Ehlers in . It lets you get a frequency out of the time series under consideration.
Amazon.com: Rocket Science for Traders: Digital Signal Processing Applications (9780471405672): John F. Ehlers: Books
It helps to have more references to understand this. There is a nice article on Wikipedia on it.
Read the part about the discrete Hilbert Transform:
en.wikipedia.org
If you really want to understand how to go from continuous to discrete, look up this article written by Richard Lyons:
www.dspguru.com
In the indicator below, I am calculating the normalized analytic signal, which can be written as:
s + i h where i is the imagery number, and s^2 + h^2 = 1;
s= signal = cosine(theta)
h = Hilbert transformed signal = quadrature = sine(theta)
The angle is therefore given by theta = arctan(h/s);
The analytic signal leading edge and the fit of the last bar of the cycle can be viewed by setting
ShowAnalyticSignal = TRUE;
The leading edges are in grayscale fit to the last bar is in color. Light (yellow) is the s term, and Dark (orange) is the quadrature (hilbert transform). Note that for every bar, s^2 + h^2 = 1 , by construction.
I am using a width = 7 Hilbert transform, just like Ehlers. (But you can adjust it if you want.) This transform has a 7 bar lag. I have put the lag into the plot statements, so the cycle info should be quite good at displaying minima and maxima (extrema).
Part 3:
The Phase shift is the amount of phase change from bar to bar.
It is a discrete unitary transformation that takes s + i h to s + i h
explicitly, T = (s+ih)*(s -ih ) , since s *s + h *h = 1.
writing it out, we find that T = T1 + iT2
where T1 = s*s + h*h and T2 = s*h -h*s
and the phase shift is given by PhaseShift = arctan(T2/T1);
Alas, I have no reference for this, all I doing is finding the rotation what takes the analytic signal at bar to the analytic signal at bar . T is the transfer matrix.
Of interest is the PhaseShift from the closest two bars to the present, given by the bar and bar since I am using a width=7 Hilbert transform, bar is the earliest bar with an analytic signal.
I store the phase shift from bar to bar as a time series called PhaseShift. It basically gives you the (7-bar delayed) leading edge the amount of phase angle change in the series.
You can see it by setting
ShowPhaseShift=TRUE
The green points are positive phase shifts and red points are negative phase shifts.
On most charts, I have looked at, the indicator is mostly green, but occasionally, the stock "retrogrades" and red appears. This happens when the cycle is "broken" and the cycle length starts to expand as a trend occurs.
Part 4:
The Period:
The Period is the number of bars required to generate a sum of PhaseShifts equal to 360 degrees.
The Half-period is the number of bars required to generate a sum of phase shifts equal to 180 degrees. It is usually not equal to 1/2 of the period.
You can see the Period and Half-period by setting
ShowPeriod=TRUE
The code is very simple here:
Value1=0;
Value2=0;
while Value1 < bar_index and math.abs(Value2) < 360 begin
Value2 = Value2 + PhaseShift ;
Value1 = Value1 + 1;
end;
Period = Value1;
The period is sensitive to the input length and degree values but not overly so. Any insight on this would be appreciated.
Part 5:
The Relative Strength indicator:
The Relative Strength is just the current value of the series minus the minimum over the last cycle divided by the maximum - minimum over the last cycle, normalized between +1 and -1.
RelativeStrength = -1 + 2*(Series-Min)/(Max-Min);
It therefore tells you where the current bar is relative to the cycle. If you want to smooth the indicator, then extend the period and/or reduce the polynomial degree.
In code:
NewLength = floor(Period + HilbertWidth+1);
Max = highest(Series,NewLength);
Min = lowest(Series,NewLength);
if Max>Min then
Note that the variable NewLength includes the lag that comes from the Hilbert transform, (HilbertWidth=7 by default).
Conclusion:
This is an example of what can be done by combining Legendre polynomials and analytic signals to determine a smooth period without adding time lag.
________________________________
Changes in this one : instead of using true/false options for every single way to display, use Type parameter as following :
1. The Least Squares fit of a polynomial to a DC subtracted time series - a best fit to a cycle.
2. The normalized analytic signal of the cycle (signal and quadrature).
3. The Phase shift of the analytic signal per bar.
4. The Period and HalfPeriod lengths, in bars of the current cycle.
5. A relative strength indicator of the time series over the cycle length. That is, adaptive relative strength over the cycle length.

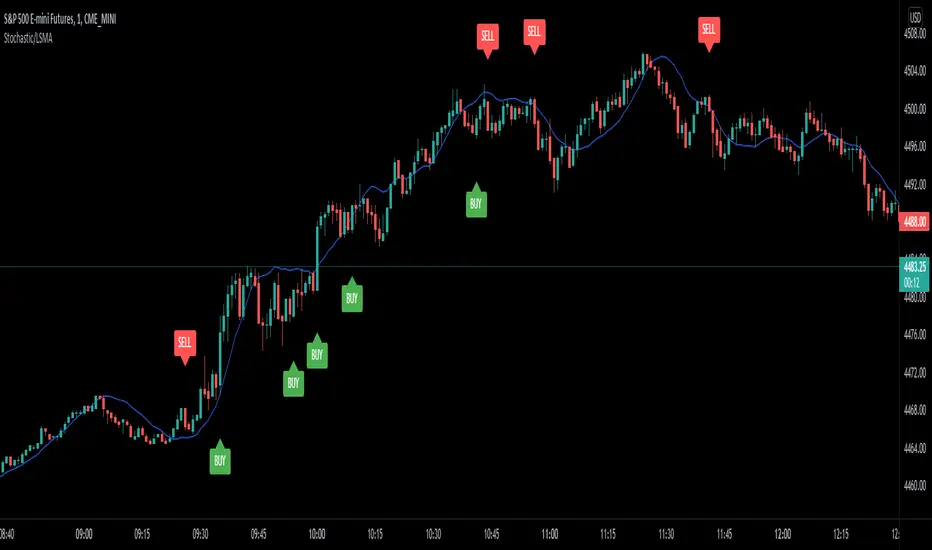
Stochastic/LSMA This is the Stochastic/LSMA Buy and Sell indicator. The Buy signal is generated when the %K line crosses up above the %D line from the stochastics while the signal candle is green and has come after a red candle. The Sell signal is generated when the %K line crosses down below the %D line from the stochastics while the signal candle is red and has come after a green candle. The default settings are %K Length is 5, the %K Smoothing is 3, and the %D Smoothing is 3 with the LSMA period being 30. I use this indicator to scalp 2 points at a time on the E-Mini (ES) on a 1 minute timeframe. I like to use a stop loss of 2 points and a target of 2 points. The LSMA helps to reduce fake signals and should also be used to see the overall trend. I hope this helps.
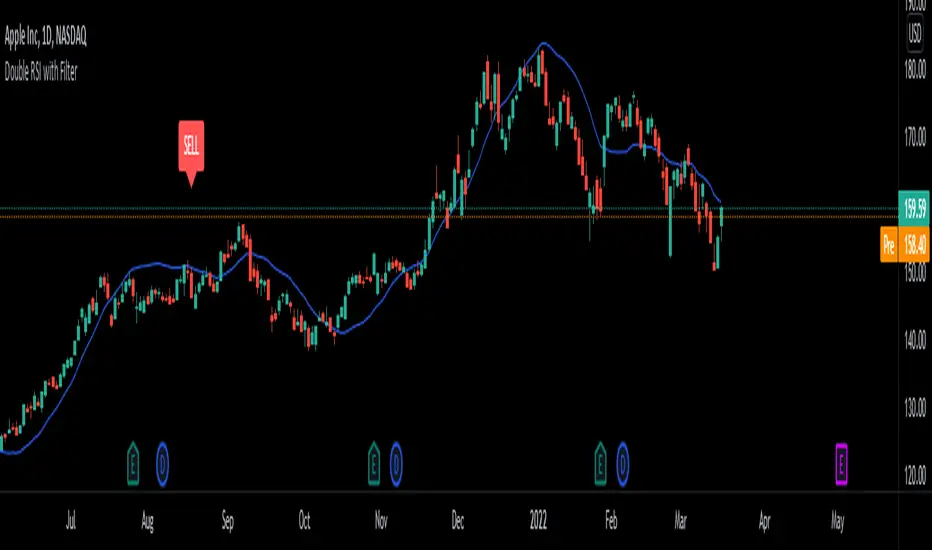
Double RSI/LSMA Double RSI uses a Slow RSI combined with a Fast RSI to generate Buy and Sell signals. Least Squares Moving Average is only here for filtering signals. It is very good on certain stocks or ETFs on longer timeframes for swing trading. If you get a Buy signal look at the LSMA trend and if the candle is above the LSMA. It works great for me on lower timeframes scalping futures and on higher timeframes swinging options. It is better than paying for Buy and Sell signals. Its my first script/indicator so play with it and see what you think. Let me know if you guys find anything that makes it better. Hopefully this helps some traders out there.
Bollinger Bands With User Selectable MABollinger Bands with user selection options to calculate the moving average basis and bands from a variety of different moving averages.
The user selects their choice of moving average, and the bands automatically adjust. The user may select a MA that reacts faster to volatility or slower/smoother.
Added additional options to color the bands or basis based on the current trend and alternate candle colors for band touches. Options:
REACT SLOW/SMOOTH TO VOLATILITY
simple moving average (Regular Bollinger Bands)
REACT SMOOTH TO VOLATILITY
exponential moving average (EMA Bollinger Bands)
weighted moving average (Weighted MA Bollinger Bands)
exponential hull moving average (Hull Bollinger Bands with better smoothing)
HIGHLY ADJUSTABLE TO VOLATILITY
Arnaud Legoux Moving average (ALMA Bollinger Bands)
Note: 0.85 ALMA default for more smoothing, set offset=1 to turn off smoothing
REACT HARSH TO VOLATILITY
least squares moving average (Least Squares Bollinger Bands)
REACT VERY FAST TO VOLATILITY
hull moving average (Hull Bollinger Bands or Hullinger Bands)
VALUE ADDED: This script is unique in that no other Bollinger Bands indicator offers a user selection for moving average, and some of the options do not exist yet as Bollinger Bands indicators.
Definitions:
Bollinger Bands: A Bollinger Band® is a technical analysis tool defined by a set of trendlines plotted two standard deviations (positively and negatively) away from a simple moving average (SMA) of a security's price, but which can be adjusted to user preferences.
Exponential Bollinger Bands: The most important characteristics of the Exponential Bollinger Bands indicator are: When the market is flat, the bands will stay much closer to prices. When the volatility is high, the bands move away from prices faster.
Hull Bollinger Bands: Bollinger Bands calculated by Hull moving average, rather than simple moving average or ema. The Hull Moving Average (HMA), developed by Alan Hull, is an extremely fast and smooth moving average. In fact, the HMA almost eliminates lag altogether and manages to improve smoothing at the same time.
Exponential Hull Bollinger Bands: Bollinger Bands calculated by Exponential Hull moving average, rather than simple moving average or ema. The Exponential Hull Moving Average is similar to the standard Hull MA, but with superior smoothing. The standard Hull Moving Average is derived from the weighted moving average (WMA). As other moving average built from weighted moving averages it has a tendency to exaggerate price movement.
Weighted Moving Average Bollinger Bands: A Weighted Moving Average (WMA) is similar to the simple moving average (SMA), except the WMA adds significance to more recent data points.
Arnaud Legoux Moving Average Bollinger Bands: ALMA removes small price fluctuations and enhances the trend by applying a moving average twice, once from left to right, and once from right to left. At the end of this process the phase shift (price lag) commonly associated with moving averages is significantly reduced. Zero-phase digital filtering reduces noise in the signal. Conventional filtering reduces noise in the signal, but adds a delay.
Least Squares Bollinger Bands: The indicator is based on sum of least squares method to find a straight line that best fits data for the selected period. The end point of the line is plotted and the process is repeated on each succeeding period.
Pump blaster based on Pump FinderThis is based on a video I watched while searching for good indicators to use for scanning pumps across the crypto market.
You can probably find the video by searching for "Pump Finder On 15 Minute Chart With Best Trading Indicators".
The approach presented uses LSMA and BB B% to detect pumps.
Results:
It does detect many pumps, it also detects many dumps...
I'm not very impressed after this first attempt but might give it another try if I come up with maybe something I'm doing wrong while trying to automate in a script the original strategy from the video.
Instructions:
This indicator is compatible with the backtest script we use.
It plots 1 for buy and 2 for sell. The rest of the plots are for debugging the strategy and can be ignored.
It's meant to be used on 15mins tf

Raff Regression Channel by DGTRᴀꜰꜰ Rᴇɢʀᴇꜱꜱɪᴏɴ Cʜᴀɴɴᴇʟ (RRC)
This study aims to automate Raff Regression Channel drawing either based on ZigZag Indicator or optionally User Preference
The Raff Regression Channel , developed by Gilbert Raff, is based on a linear regression, which is the least-squares line-of-best-fit for a price series, with evenly spaced trend lines above and below . The width of the channel is set by determining the high or low that is the furthest from the linear regression.
Because the channel distance is based off the largest pullback or highest peak within a trend, for effectively drawing and using a Raff Regression Channel it is recommend/required that a Raff Regression Channel is applied to “mature” trends. Knowing this requirement, for better automated drawing results this study benefits from the Zig Zag Indicator, where the Zig Zag indicator is used to help identify price trends and changes in price trends. Option to manually adjust lengths for drawing a Raff Regression Channel is also made available.
Using a Raff Regression Channel
Once The Raff Regression Channel is drawn, covering an existing trend, Exᴛᴇɴꜱɪᴏɴ Lɪɴᴇꜱ are drawn to identify ᴛʜᴇ ꜱᴜᴘᴘᴏʀᴛ﹐ʀᴇꜱɪꜱᴛᴀɴᴄᴇ ᴏʀ ʀᴇᴠᴇʀꜱᴀʟ ᴘᴏɪɴᴛꜱ
The trend is up as long as prices rise within this channel. An uptrend may be reversing (not always, but likely) when price breaks below the channel extension . The trend is down as long as prices decline within the channel. Similarly, a downtrend may be reversing (not always, but likely) when price breaks above the channel extension . Moves outside the channel extensions can be indication of a reversal or can denote overbought or oversold conditions
For further details please refer to education post Raff Regression Channel
█ FEATURES
- AUTO or MANUALLY adjusted Raff Regression Channel and Channel Extentions drawing
- ALERTs, for Linear Regression Line, Raff Regression Upper and Lower Channel Extentions
- LSMA , Least Squares Moving Average, in other words Linear Regression Curve
█ SETTINGS
Setting Loopback and Number of Bars are the most important part for The Raff Regression Channel, where ;
- Lookback, defines where the Raff Regression Channel is starting, it is recommended to set to a trend begining
- Number of Bars, defines how many bars to be assumed for calculation, or simply stated the end of the Raff Regression Channel drawing (not extentions but the main channel, extentions by default will be drawn till the last bar)
Setting of Loopback and Number of Bars is performed eigher automatically based on Zig Zag indicator or users may prefer to set them manually. If selected automatically then
- Deviation and Depth values of Zig Zag indicator are used for calculations (enabling visually plotting of ZigZag Lines will help to identify better visually the points), where ;
Deviation, is a multiplier that affects how much the price should deviate from the previous pivot in order for the bar to become a new pivot.
Depth, affects the minimum number of bars that will be taken into account when building
Short-term traders may wish to apply the channel to small waves of a trend so they can reduce the value of the Deviation and Depth
█ OTHER CHANNEL CONSEPTS
Linear Regression Channels, , what linear regression channels are? and linear regression channel/curve/slope study
Fibonacci Channels, how to apply fibonacci channels and automated fibonacci channels study
Andrews’ Pitchfork, how to apply pitchfork and automated pitchfork study
Special Thanks to @Kiss66000 for his kind suggestion, je vous remercie beaucoup @Kiss66000
Disclaimer :
Trading success is all about following your trading strategy and the indicators should fit within your trading strategy, and not to be traded upon solely
The script is for informational and educational purposes only. Use of the script does not constitute professional and/or financial advice. You alone have the sole responsibility of evaluating the script output and risks associated with the use of the script. In exchange for using the script, you agree not to hold dgtrd TradingView user liable for any possible claim for damages arising from any decision you make based on use of the script
Polynomial Regression Bands + Channel [DW]This is an experimental study designed to calculate polynomial regression for any order polynomial that TV is able to support.
This study aims to educate users on polynomial curve fitting, and the derivation process of Least Squares Moving Averages (LSMAs).
I also designed this study with the intent of showcasing some of the capabilities and potential applications of TV's fantastic new array functions.
Polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modeled as a polynomial of nth degree (order).
For clarification, linear regression can also be described as a first order polynomial regression. The process of deriving linear, quadratic, cubic, and higher order polynomial relationships is all the same.
In addition, although deriving a polynomial regression equation results in a nonlinear output, the process of solving for polynomials by least squares is actually a special case of multiple linear regression.
So, just like in multiple linear regression, polynomial regression can be solved in essentially the same way through a system of linear equations.
In this study, you are first given the option to smooth the input data using the 2 pole Super Smoother Filter from John Ehlers.
I chose this specific filter because I find it provides superior smoothing with low lag and fairly clean cutoff. You can, of course, implement your own filter functions to see how they compare if you feel like experimenting.
Filtering noise prior to regression calculation can be useful for providing a more stable estimation since least squares regression can be rather sensitive to noise.
This is especially true on lower sampling lengths and higher degree polynomials since the regression output becomes more "overfit" to the sample data.
Next, data arrays are populated for the x-axis and y-axis values. These are the main datasets utilized in the rest of the calculations.
To keep the calculations more numerically stable for higher periods and orders, the x array is filled with integers 1 through the sampling period rather than using current bar numbers.
This process can be thought of as shifting the origin of the x-axis as new data emerges.
This keeps the axis values significantly lower than the 10k+ bar values, thus maintaining more numerical stability at higher orders and sample lengths.
The data arrays are then used to create a pseudo 2D matrix of x power sums, and a vector of x power*y sums.
These matrices are a representation the system of equations that need to be solved in order to find the regression coefficients.
Below, you'll see some examples of the pattern of equations used to solve for our coefficients represented in augmented matrix form.
For example, the augmented matrix for the system equations required to solve a second order (quadratic) polynomial regression by least squares is formed like this:
(∑x^0 ∑x^1 ∑x^2 | ∑(x^0)y)
(∑x^1 ∑x^2 ∑x^3 | ∑(x^1)y)
(∑x^2 ∑x^3 ∑x^4 | ∑(x^2)y)
The augmented matrix for the third order (cubic) system is formed like this:
(∑x^0 ∑x^1 ∑x^2 ∑x^3 | ∑(x^0)y)
(∑x^1 ∑x^2 ∑x^3 ∑x^4 | ∑(x^1)y)
(∑x^2 ∑x^3 ∑x^4 ∑x^5 | ∑(x^2)y)
(∑x^3 ∑x^4 ∑x^5 ∑x^6 | ∑(x^3)y)
This pattern continues for any n ordered polynomial regression, in which the coefficient matrix is a n + 1 wide square matrix with the last term being ∑x^2n, and the last term of the result vector being ∑(x^n)y.
Thanks to this pattern, it's rather convenient to solve the for our regression coefficients of any nth degree polynomial by a number of different methods.
In this script, I utilize a process known as LU Decomposition to solve for the regression coefficients.
Lower-upper (LU) Decomposition is a neat form of matrix manipulation that expresses a 2D matrix as the product of lower and upper triangular matrices.
This decomposition method is incredibly handy for solving systems of equations, calculating determinants, and inverting matrices.
For a linear system Ax=b, where A is our coefficient matrix, x is our vector of unknowns, and b is our vector of results, LU Decomposition turns our system into LUx=b.
We can then factor this into two separate matrix equations and solve the system using these two simple steps:
1. Solve Ly=b for y, where y is a new vector of unknowns that satisfies the equation, using forward substitution.
2. Solve Ux=y for x using backward substitution. This gives us the values of our original unknowns - in this case, the coefficients for our regression equation.
After solving for the regression coefficients, the values are then plugged into our regression equation:
Y = a0 + a1*x + a1*x^2 + ... + an*x^n, where a() is the ()th coefficient in ascending order and n is the polynomial degree.
From here, an array of curve values for the period based on the current equation is populated, and standard deviation is added to and subtracted from the equation to calculate the channel high and low levels.
The calculated curve values can also be shifted to the left or right using the "Regression Offset" input
Changing the offset parameter will move the curve left for negative values, and right for positive values.
This offset parameter shifts the curve points within our window while using the same equation, allowing you to use offset datapoints on the regression curve to calculate the LSMA and bands.
The curve and channel's appearance is optionally approximated using Pine's v4 line tools to draw segments.
Since there is a limitation on how many lines can be displayed per script, each curve consists of 10 segments with lengths determined by a user defined step size. In total, there are 30 lines displayed at once when active.
By default, the step size is 10, meaning each segment is 10 bars long. This is because the default sampling period is 100, so this step size will show the approximate curve for the entire period.
When adjusting your sampling period, be sure to adjust your step size accordingly when curve drawing is active if you want to see the full approximate curve for the period.
Note that when you have a larger step size, you will see more seemingly "sharp" turning points on the polynomial curve, especially on higher degree polynomials.
The polynomial functions that are calculated are continuous and differentiable across all points. The perceived sharpness is simply due to our limitation on available lines to draw them.
The approximate channel drawings also come equipped with style inputs, so you can control the type, color, and width of the regression, channel high, and channel low curves.
I also included an input to determine if the curves are updated continuously, or only upon the closing of a bar for reduced runtime demands. More about why this is important in the notes below.
For additional reference, I also included the option to display the current regression equation.
This allows you to easily track the polynomial function you're using, and to confirm that the polynomial is properly supported within Pine.
There are some cases that aren't supported properly due to Pine's limitations. More about this in the notes on the bottom.
In addition, I included a line of text beneath the equation to indicate how many bars left or right the calculated curve data is currently shifted.
The display label comes equipped with style editing inputs, so you can control the size, background color, and text color of the equation display.
The Polynomial LSMA, high band, and low band in this script are generated by tracking the current endpoints of the regression, channel high, and channel low curves respectively.
The output of these bands is similar in nature to Bollinger Bands, but with an obviously different derivation process.
By displaying the LSMA and bands in tandem with the polynomial channel, it's easy to visualize how LSMAs are derived, and how the process that goes into them is drastically different from a typical moving average.
The main difference between LSMA and other MAs is that LSMA is showing the value of the regression curve on the current bar, which is the result of a modelled relationship between x and the expected value of y.
With other MA / filter types, they are typically just averaging or frequency filtering the samples. This is an important distinction in interpretation. However, both can be applied similarly when trading.
An important distinction with the LSMA in this script is that since we can model higher degree polynomial relationships, the LSMA here is not limited to only linear as it is in TV's built in LSMA.
Bar colors are also included in this script. The color scheme is based on disparity between source and the LSMA.
This script is a great study for educating yourself on the process that goes into polynomial regression, as well as one of the many processes computers utilize to solve systems of equations.
Also, the Polynomial LSMA and bands are great components to try implementing into your own analysis setup.
I hope you all enjoy it!
--------------------------------------------------------
NOTES:
- Even though the algorithm used in this script can be implemented to find any order polynomial relationship, TV has a limit on the significant figures for its floating point outputs.
This means that as you increase your sampling period and / or polynomial order, some higher order coefficients will be output as 0 due to floating point round-off.
There is currently no viable workaround for this issue since there isn't a way to calculate more significant figures than the limit.
However, in my humble opinion, fitting a polynomial higher than cubic to most time series data is "overkill" due to bias-variance tradeoff.
Although, this tradeoff is also dependent on the sampling period. Keep that in mind. A good rule of thumb is to aim for a nice "middle ground" between bias and variance.
If TV ever chooses to expand its significant figure limits, then it will be possible to accurately calculate even higher order polynomials and periods if you feel the desire to do so.
To test if your polynomial is properly supported within Pine's constraints, check the equation label.
If you see a coefficient value of 0 in front of any of the x values, reduce your period and / or polynomial order.
- Although this algorithm has less computational complexity than most other linear system solving methods, this script itself can still be rather demanding on runtime resources - especially when drawing the curves.
In the event you find your current configuration is throwing back an error saying that the calculation takes too long, there are a few things you can try:
-> Refresh your chart or hide and unhide the indicator.
The runtime environment on TV is very dynamic and the allocation of available memory varies with collective server usage.
By refreshing, you can often get it to process since you're basically just waiting for your allotment to increase. This method works well in a lot of cases.
-> Change the curve update frequency to "Close Only".
If you've tried refreshing multiple times and still have the error, your configuration may simply be too demanding of resources.
v4 drawing objects, most notably lines, can be highly taxing on the servers. That's why Pine has a limit on how many can be displayed in the first place.
By limiting the curve updates to only bar closes, this will significantly reduce the runtime needs of the lines since they will only be calculated once per bar.
Note that doing this will only limit the visual output of the curve segments. It has no impact on regression calculation, equation display, or LSMA and band displays.
-> Uncheck the display boxes for the drawing objects.
If you still have troubles after trying the above options, then simply stop displaying the curve - unless it's important to you.
As I mentioned, v4 drawing objects can be rather resource intensive. So a simple fix that often works when other things fail is to just stop them from being displayed.
-> Reduce sampling period, polynomial order, or curve drawing step size.
If you're having runtime errors and don't want to sacrifice the curve drawings, then you'll need to reduce the calculation complexity.
If you're using a large sampling period, or high order polynomial, the operational complexity becomes significantly higher than lower periods and orders.
When you have larger step sizes, more historical referencing is used for x-axis locations, which does have an impact as well.
By reducing these parameters, the runtime issue will often be solved.
Another important detail to note with this is that you may have configurations that work just fine in real time, but struggle to load properly in replay mode.
This is because the replay framework also requires its own allotment of runtime, so that must be taken into consideration as well.
- Please note that the line and label objects are reprinted as new data emerges. That's simply the nature of drawing objects vs standard plots.
I do not recommend or endorse basing your trading decisions based on the drawn curve. That component is merely to serve as a visual reference of the current polynomial relationship.
No repainting occurs with the Polynomial LSMA and bands though. Once the bar is closed, that bar's calculated values are set.
So when using the LSMA and bands for trading purposes, you can rest easy knowing that history won't change on you when you come back to view them.
- For those who intend on utilizing or modifying the functions and calculations in this script for their own scripts, I included debug dialogues in the script for all of the arrays to make the process easier.
To use the debugs, see the "Debugs" section at the bottom. All dialogues are commented out by default.
The debugs are displayed using label objects. By default, I have them all located to the right of current price.
If you wish to display multiple debugs at once, it will be up to you to decide on display locations at your leisure.
When using the debugs, I recommend commenting out the other drawing objects (or even all plots) in the script to prevent runtime issues and overlapping displays.
Triumph ChannelsChannel uses @KivancOzbilgic's VIDYA script as a basis and the maximum distance between Least Square Moving Average (14) over a specified number of periods (80) as size.
This combination is good as it uses one very slow MA and one highly overlapping one. Can be combined with ATR channels where Triumph will represent extreme in relevance to the previous days and ATR channels will work with current volatility.
I like to offset channel sizing by 3, so when the price gets outside the channel, it doesn't get engulfed by the blue just yet.
If you zoom out, this is good to spotting sideways price action too. When there is a trend, it will be big. Then, it will remain low in the contraction phase and it will make it easier to find the areas of contraction and trend in retrospective and study them before placing a new trade.
LSMA - A Fast And Simple Alternative CalculationIntroduction
At the start of 2019 i published my first post "Approximating A Least Square Moving Average In Pine", who aimed to provide alternatives calculation of the least squares moving average (LSMA), a moving average who aim to estimate the underlying trend in the price without excessive lag.
The LSMA has the form of a linear regression ax + b where x is a linear sequence 1.2.3..N and with time varying a and b , the exact formula of the LSMA is as follows :
a = stdev(close,length)/stdev(bar_index,length) * correlation(close,bar_index,length)
b = sma(close,length) - a*sma(bar_index,length)
lsma = a*bar_index + b
Such calculation allow to forecast future values however such forecast is rarely accurate and the LSMA is mostly used as a smoother. In this post an alternative calculation is proposed, such calculation is incredibly simple and allow for an extremely efficient computation of the LSMA.
Rationale
The LSMA is a FIR low-pass filter with the following impulse response :
The impulse response of a FIR filter gives us the weight of the filter, as we can see the weights of the LSMA are a linearly decreasing sequence of values, however unlike the linearly weighted moving average (WMA) the weights of the LSMA take on negative values, this is necessary in order to provide a better fit to the data. Based on such impulse response we know that the WMA can help calculate the LSMA, since both have weights representing a linearly decreasing sequence of values, however the WMA doesn't have negative weights, so the process here is to fit the WMA impulse response to the impulse response of the LSMA.
Based on such negative values we know that we must subtract the impulse response of the WMA by a constant value and multiply the result, such constant value can be given by the impulse response of a simple moving average, we must now make sure that the impulse response of the WMA and SMA cross at a precise point, the point where the impulse response of the LSMA is equal to 0.
We can see that 3WMA and 2SMA are equal at a certain point, and that the impulse response of the LSMA is equal to 0 at that point, if we proceed to subtraction we obtain :
Therefore :
LSMA = 3WMA - 2SMA = WMA + 2(WMA - SMA)
Comparison
On a graph the difference isn't visible, subtracting the proposed calculation with a regular LSMA of the same period gives :
the error is 0.0000000...and certainly go on even further, therefore we can assume that the error is due to rounding errors.
Conclusion
This post provided a different calculation of the LSMA, it is shown that the LSMA can be made from the linear combination of a WMA and a SMA : 3WMA + -2SMA. I encourage peoples to use impulse responses in order to estimate other moving averages, since some are extremely heavy to compute.
Thanks for reading !

Volume weighted LSMAQuick script made by reusing some functions written for other projects. This is a variation on the least squares moving average, but with custom weights on the linear regression. This gives higher weights to recent values and values with high volume.
Behaves very similarly to my volume weighted Hull moving average, especially with the hull smoothing option turned on.
Least Squares Bollinger BandsSimilar to Bollinger Bands but adjusted for momentum. Instead of having the centerline be a simply moving average and the bands showing the rolling variance, this does a linear regression, and shows the LSMA at the center, while the band width is the average deviation from the regression line instead of from the SMA.
This means that unlike for normal Bollinger bands, momentum does not make the bands wider, and that the bands tend to be much better centered around the price action with band walks being more reliable indicators of undersold/oversold conditions. They also give a much narrower estimate of current volatility/price range.
Fast/Slow Degree OscillatorIntroduction
The estimation of a least squares moving average of any degree isn't an interesting goal, this is due to the fact that lsma of high degrees would highly overshoot as well as overfit the closing price, which wouldn't really appear smooth. However i proposed an estimate of an lsma of any degree using convolution and a new sine wave series, all the calculation are described in the paper : "Pierrefeu, Alex (2019): A New Low-Pass FIR Filter For Signal Processing."
Today i want to make use of this filter as an oscillator providing fast entry points. The oscillator would be similar to the MACD in the sense that is consist on the difference between two filters, with one faster than the other, however unlike the MACD which use two moving averages of different length, here i'll use two filters of same length but different degrees.
The Indicator
The indicator consist in 3 elements, one main line (in green) the trigger line (in orange) and the histogram which is the difference between the green line and the red one. The main line is made from the difference between two filters of both period length and different degrees (fast, slow), fast should always be higher than slow. The signal line is just the exponential moving average of the main line, the period of the exponential moving average can be adjusted from the settings.
Both fast/slow determine the degree of the filters, higher values will create a faster filter.
For those who are curious, the filter use a kernel who estimate a polynomial function, this is how an lsma work, the kernel of an lsma of degree p is a polynomial of degree p . I achieved this estimation using a sine wave series.
When fast = 1 and slow = 0, the oscillator appear less periodic, this equivalent to : lsma - sma
Using 2/1 allow the indicator to highlight cycles more easily without being uncorrelated with the price. This is equivalent to qlsma - lsma, where qlsma is a quadratic least squares moving average. This is similar to my old indicator "Linear Quadratic Convergence Divergence Oscillator".
By default the indicator use 3 for fast and 2 for slow, but you can increase both values, here 4/3 :
In general higher values of fast/slow will create way more cyclical results, but they can be uncorrelated with the market price.
Conclusion
This indicator was rather made to show the filter calculation rather than proposing something interesting. However it can be funny to see how the difference between low lag filters create more cyclical outputs, it often allow indicators to have more predictive capabilities.
I invite you to read the paper made about the filter, codes for both pinescript and python are provided.
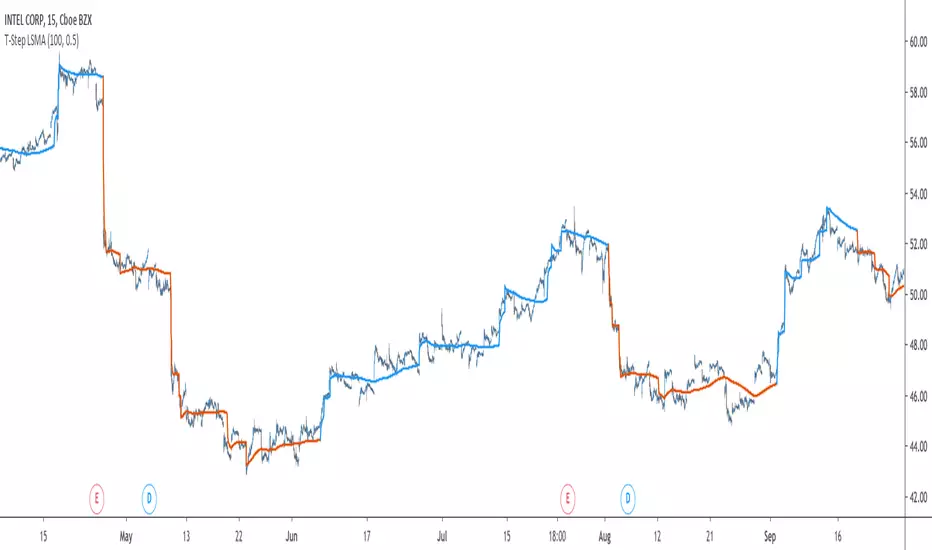
T-Step LSMAIntroduction
The trend step indicator family has produced much interest in the community, those indicators showed in certain cases robustness and reactivity. Their ease of use/interpretation is also a major advantage. Although those indicators have a relatively good fit with the input price, they can still be improved by introducing least-squares fitting on their calculations. This is why i propose a new indicator (T-Step LSMA) which aim to gather all the components of the trend-step indicator family (including the auto-line family).
The indicator will use as a threshold the mean absolute error between the input and the output (T-Channel) scaled with the efficiency ratio (Efficient Trend Step) while using least squares in order to provide a better fit with the price (Auto-Filter).
The Indicator
The interpretation of the indicator is easy, the indicator estimate an up-trending market when in blue, down-trending when in orange, the signal only depend on the trend-step part ( b in the code).
length control the period of the efficiency ratio as well as any components in the lsma calculation. The efficiency ratio allow to provide adaptivity, therefore the threshold will be lower when market is trending and higher when market is ranging.
Sc control the amount of feedback of the indicator, a value of 1 will use only the closing price as input, a value of 0.5 will use 50% of the closing price/indicator output as input, this allow to get smoother results.
It is possible to get the non-smooth version of the indicator by checking "No Smoothing".
This allow the indicator to filter more information.
Least Squares Smoothing - Benefits
One could ask why introducing least squares smoothing, there are several reasons to this choice, we have seen that trend-step indicators are boxy, they filter most of the variational information in the price, introducing least squares smoothing allow to gain back some of this variational information while providing a better fit with the price, the indicator is more noisy but also more practical in certain situations.
For example the indicator in its boxy form can't really be useful as input for other indicators, which is not the case with this version.
Relative strength index of period 14 using the proposed indicator as input.
Down-Sides
The indicator is dependent on the time frame used, larger time frames resulting in an indicator overfitting, sticking with lower time frames might be ideal. The indicator behavior might also change depending on the market in which it is applied.
Setting Up Alerts For The Indicator
Alerts conditions are already set, in order to create an alert based on the indicator follow these steps :
Go to the alert section (the alarm clock) -> create new alert -> select T-Step LSMA in condition -> Below select Up or Dn (Up for a up-trending alert and Dn for a down-trending alert)
In option select "once per bar close", change the message if you want a personalized message.
Conclusion
I don't think i'll post other indicators related to the trend-step framework for the time to comes, nonetheless the ones posted proven to have interesting results as well as many upsides. Although i don't think they would generate positive long-terms returns they could still be of use when using smarter volatility metrics as threshold. The proposed indicator conserve more information than its relatives and might find some use as input for other indicators.
Recommended Use Of The Code
Although i don't put restrictions on the code usage, i still recommend creative and pertinent changes to be made, graphical changes or any minor changes are not necessary, remember that such practice is disrespectful toward the author, you don't want to load up the tradingview servers for nothing right ?
Support Me
Making indicators sure is hard, it takes time and it can be quite lonely to, so i would love talking with you guys while making them :) There isn't better support than the one provided by your friends so drop me a message.
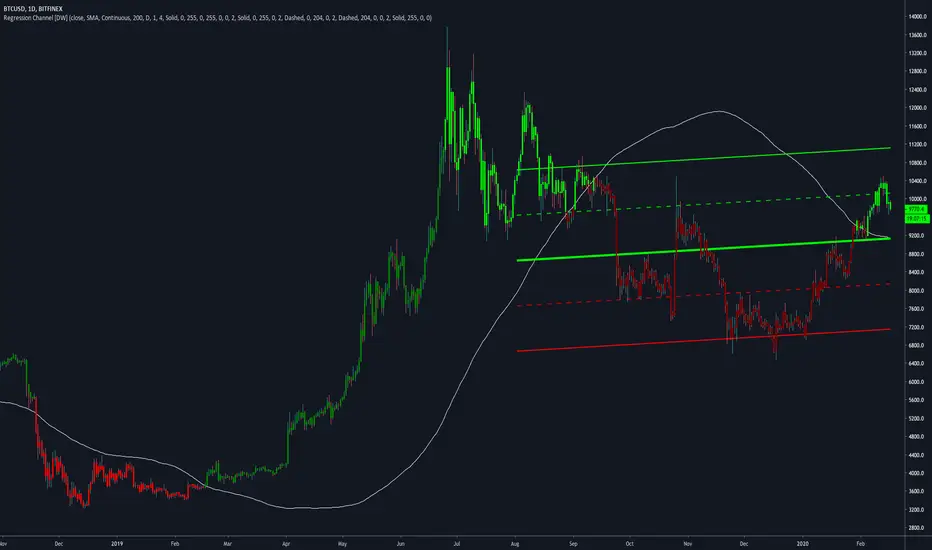
Regression Channel [DW]This is an experimental study which calculates a linear regression channel over a specified period or interval using custom moving average types for its calculations.
Linear regression is a linear approach to modeling the relationship between a dependent variable and one or more independent variables.
In linear regression, the relationships are modeled using linear predictor functions whose unknown model parameters are estimated from the data.
The regression channel in this study is modeled using the least squares approach with four base average types to choose from:
-> Arnaud Legoux Moving Average (ALMA)
-> Exponential Moving Average (EMA)
-> Simple Moving Average (SMA)
-> Volume Weighted Moving Average (VWMA)
When using VWMA, if no volume is present, the calculation will automatically switch to tick volume, making it compatible with any cryptocurrency, stock, currency pair, or index you want to analyze.
There are two window types for calculation in this script as well:
-> Continuous, which generates a regression model over a fixed number of bars continuously.
-> Interval, which generates a regression model that only moves its starting point when a new interval starts. The number of bars for calculation cumulatively increases until the end of the interval.
The channel is generated by calculating standard deviation multiplied by the channel width coefficient, adding it to and subtracting it from the regression line, then dividing it into quartiles.
To observe the path of the regression, I've included a tracer line, which follows the current point of the regression line. This is also referred to as a Least Squares Moving Average (LSMA).
For added predictive capability, there is an option to extend the channel lines into the future.
A custom bar color scheme based on channel direction and price proximity to the current regression value is included.
I don't necessarily recommend using this tool as a standalone, but rather as a supplement to your analysis systems.
Regression analysis is far from an exact science. However, with the right combination of tools and strategies in place, it can greatly enhance your analysis and trading.
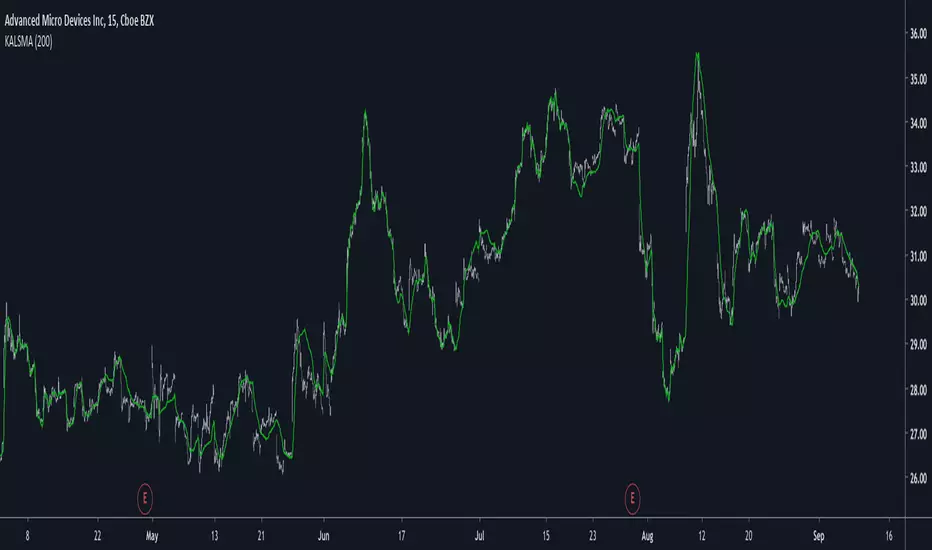
Kaufman Adaptive Least Squares Moving AverageIntroduction
It is possible to use a wide variety of filters for the estimation of a least squares moving average, one of the them being the Kaufman adaptive moving average (KAMA) which adapt to the market trend strength, by using KAMA in an lsma we therefore allow for an adaptive low lag filter which might provide a smarter way to remove noise while preserving reactivity.
The Indicator
The lsma aim to minimize the sum of the squared residuals, paired with KAMA we obtain a great adaptive solution for smoothing while conserving reactivity. Length control the period of the efficiency ratio used in KAMA, higher values of length allow for overall smoother results. The pre-filtering option allow for even smoother results by using KAMA as input instead of the raw price.
The proposed indicator without pre-filtering in green, a simple moving average in orange, and a lsma with all of them length = 200. The proposed filter allow for fast and precise crosses with the moving average while eliminating major whipsaws.
Same setup with the pre-filtering option, the result are overall smoother.
Conclusion
The provided code allow for the implementation of any filter instead of KAMA, try using your own filters. Thanks for reading :)
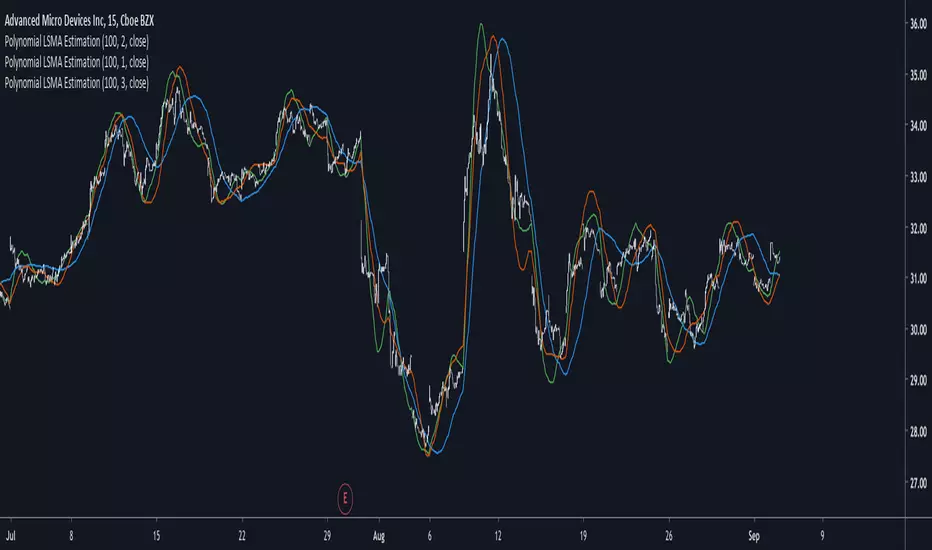
Polynomial LSMA Estimation - Estimating An LSMA Of Any DegreeIntroduction
It was one of my most requested post, so here you have it, today i present a way to estimate an LSMA of any degree by using a kernel based on a sine wave series, note that this is originally a paper that i posted that you can find here figshare.com , in the paper you will be able to find the frequency response of the filter as well as both python and pinescript code.
The least squares moving average or LSMA is a filter that best fit a polynomial function through the price by using the method of least squares, by default the LSMA best fit a line through the input by using the following formula : ax + b where x is often a linear series 1,2,3...etc and a/b are parameters, the LSMA is made by finding a and b such that their values minimize the sum of squares between the lsma and the input.
Now a LSMA of 2nd degree (quadratic) is in the form of ax^2 + bx + c , although the first order LSMA is not hard to make the 2nd order one is way more heavy in term of codes since we must find optimal values for a , b and c , therefore we may want to find alternatives if the goal is simply data smoothing.
Estimation By Convolution
The LSMA is a FIR filter which posses various characteristics, the impulse response of an LSMA of degree n is a polynomial of the same degree, and its step response is a polynomial of degree n+1, estimating those step response is done by the described sine wave series :
f(x) =>
sum = 0.
b = 0.
pi = atan(1)*4
a = x*x
for i = 1 to d
b := 1/i * sin(x*i*pi)
sum := sum + b
pol = a + iff(d == 0,0,sum)
which is simple the sum of multiple sine waves of different frequency and amplitude + the square of a linear function. We then differentiate this result and apply convolution.
The Indicator
length control the filter period while degree control the degree of the filter, higher degree's create better fit with the input as seen below :
Now lets compare our estimate with actual LSMA's, below a lsma in blue and our estimate in orange of both degree 1 and period 100 :
Below a LSMA of degree 2 (quadratic) and our estimate with degree 2 with both period 100 :
It can be seen that the estimate is doing a pretty decent job.
Now we can't make comparisons with higher degrees of lsma's but thats not a real necessity.
Conclusion
This indicator wasn't intended as a direct estimate of the lsma but it was originally based on the estimation of polynomials using sine wave series, which led to the proposed filter showcased in the article. So i think we can agree that this is not a bad estimate although i could have showcased more statistics but thats to many work, but its not that interesting to use higher degree's anyways so sticking with degree 1, 2 and 3 might be for the best.
Hope you like and thanks for reading !
Options - Kaufman / LEAST SQUARES Moving AverageThis is a combo of multiple indicators :
1- three kama moving averages
2- one lsma moving average
3- a kama upper and lower band that you can set to use any of the three kama moving averages in the indicator as source
4- upper, lower and center bollinger bands price for last candle
The horizontal dot line is the bollinger and the horizontal arrowed lines are the bands for kama indicator.
The parameters are available for KAMA, LSMA and BB settings, the default settings are prefabricated for options trading.
