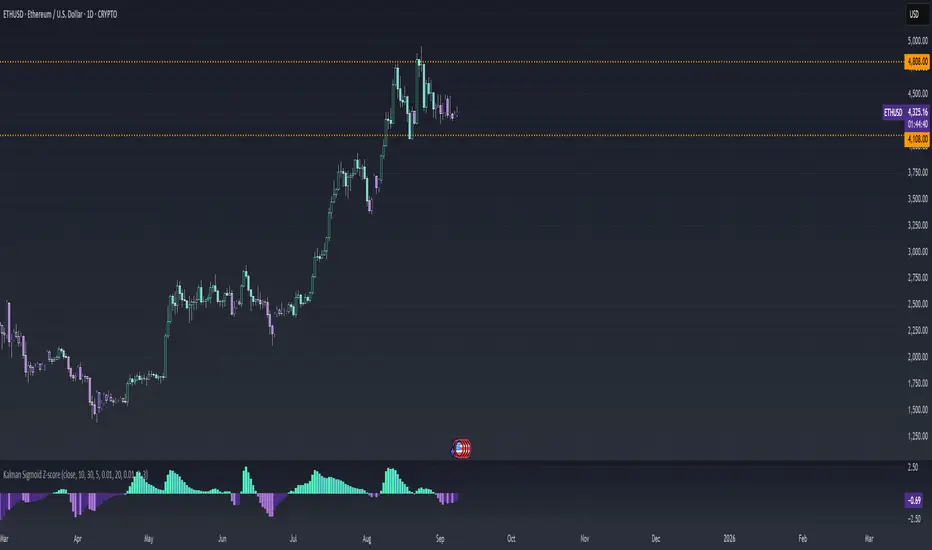
Kalman Sigmoid Z-score | SurgeQuantTitle: Kalman Sigmoid Z-score Indicator
The Kalman Sigmoid Z-score indicator is a sophisticated tool designed to identify market momentum and potential trend changes using a combination of Kalman filtering, sigmoid-weighted averaging, and Z-score calculations. By processing price data through a Kalman filter and applying adaptive sigmoid weighting, this indicator provides clear visual signals for bullish and bearish market conditions. The Z-score output and price bars are dynamically colored to highlight momentum shifts, aiding traders in identifying potential trading opportunities.
How It Works
Kalman Filter Calculation
Computes a smoothed price series using a Kalman filter based on a user-selected price source (Close, High, Low, or Open) with configurable parameters for process noise, measurement noise, and filter order (default: 3).
The Kalman filter reduces noise in the price data, providing a stable foundation for further analysis.
Sigmoid-Weighted Averaging
Applies a sigmoid function to calculate adaptive weights based on price comparisons over a user-defined lookback period (default: 10).
Weights are adjusted dynamically using a volatility ratio (standard deviation over ATR) to account for market conditions, enhancing signal reliability.
Z-score Calculation
Calculates the Z-score of the Kalman-filtered price relative to a sigmoid-weighted moving average over a user-defined period (default: 20).
Bullish Signal: Triggered when the Z-score crosses above 0, indicating potential upward momentum.
Bearish Signal: Triggered when the Z-score crosses below 0, indicating potential downward momentum.
Visual Representation
The indicator provides a clear and customizable visual interface:
Z-score Histogram: Displayed as colored columns, with distinct colors for bullish (Z-score > 0) and bearish (Z-score < 0) conditions.
Bright green (#4DFFBE) for rising Z-score above 0.
Light green (#56DFCF) for falling Z-score above 0.
Dark purple (#AE75DA) for falling Z-score below 0.
Light purple (#4D2D8C) for rising Z-score below 0.
Price Bar Coloring: Synchronizes with the Z-score colors to reflect momentum on the main chart.
Reference Line: A zero line is plotted on the Z-score panel for easy reference.
Customization & Parameters
The Kalman Sigmoid Z-score indicator offers flexible parameters to suit various trading styles:
Source: Select the input price (default: Close; options: Close, High, Low, Open).
Lookback Period: Set the period for sigmoid weight calculations (default: 10).
Volatility Period: Adjust the period for volatility ratio calculation (default: 30).
Base Steepness: Control the sigmoid function’s sensitivity (default: 5).
Base Midpoint: Set the sigmoid function’s midpoint (default: 0.01).
Z-score Period: Define the period for Z-score calculation (default: 20).
Kalman Parameters:
Process Noise (default: 0.01).
Measurement Noise (default: 3).
Filter Order (default: 3).
Color Settings: Predefined colors with distinct shades for bullish and bearish states, ensuring clear visual differentiation.
Trading Applications
This indicator is versatile and can be applied across various markets and strategies:
Momentum Trading: Highlights strong bullish or bearish momentum for potential entry or exit points based on Z-score crossings.
Trend Confirmation: Use bar coloring to confirm Z-score signals with price action on the main chart.
Reversal Detection: Identify potential reversals when the Z-score crosses the zero line.
Scalping and Swing Trading: Adjust parameters (e.g., lookback, Z-score period) to suit short-term or longer-term strategies.
Final Note
The Kalman Sigmoid Z-score indicator is a powerful tool for traders seeking to leverage advanced filtering and statistical analysis for momentum and trend-based opportunities. Its combination of Kalman-filtered price smoothing, sigmoid-weighted averaging, dynamic Z-score signals, and synchronized bar coloring offers a robust framework for informed trading decisions. As with all indicators, backtest thoroughly and integrate into a comprehensive trading strategy for optimal results. This indicator is provided for educational and informational purposes and should not be considered financial advice.
Cari dalam skrip untuk "大位科技同行业可替代股票的技术面分析数据(如5日均线、10日均线、支撑位、压力位)"
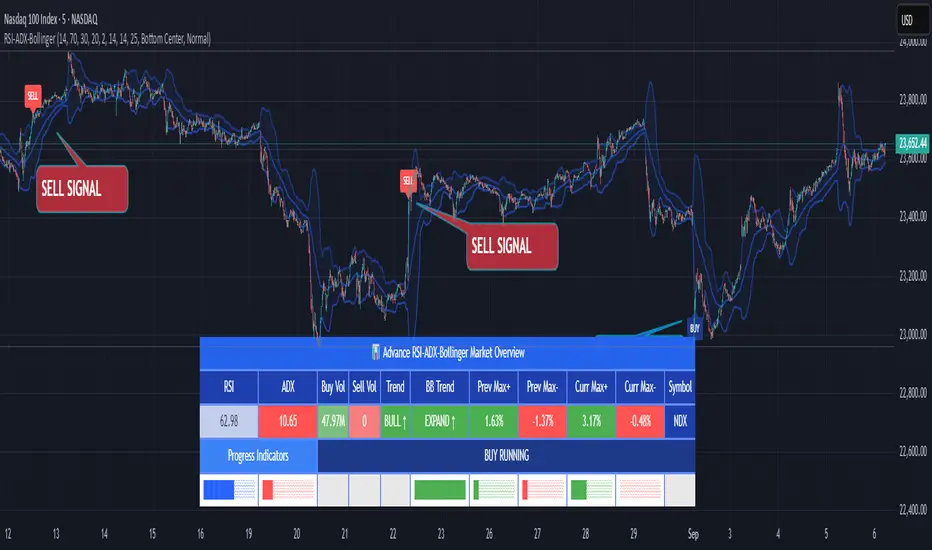
RSI ADX Bollinger Analysis High-level purpose and design philosophy
This indicator — RSI-ADX-Bollinger Analysis — is a compact, educational market-analysis toolkit that blends momentum (RSI), trend strength (ADX), volatility structure (Bollinger Bands) and simple volumetrics to provide traders a snapshot of market condition and trade idea quality. The design philosophy is explicit and layered: use each component to answer a different question about price action (momentum, conviction, volatility, participation), then combine answers to form a more robust, explainable signal. The mashup is intended for analysis and learning, not automatic execution: it surfaces the why behind signals so traders can test, learn and apply rules with risk management.
________________________________________
What each indicator contributes (component-by-component)
RSI (Relative Strength Index) — role and behavior: RSI measures short-term momentum by comparing recent gains to recent losses. A high RSI (near or above the overbought threshold) indicates strong recent buying pressure and potential exhaustion if price is extended. A low RSI (near or below the oversold threshold) indicates strong recent selling pressure and potential exhaustion or a value area for mean-reversion. In this dashboard RSI is used as the primary momentum trigger: it helps identify whether price is locally over-extended on the buy or sell side.
ADX (Average Directional Index) — role and behavior: ADX measures trend strength independently of direction. When ADX rises above a chosen threshold (e.g., 25), it signals that the market is trending with conviction; ADX below the threshold suggests range or weak trend. Because patterns and momentum signals perform differently in trending vs. ranging markets, ADX is used here as a filter: only when ADX indicates sufficient directional strength does the system treat RSI+BB breakouts as meaningful trade candidates.
Bollinger Bands — role and behavior: Bollinger Bands (20-period basis ± N standard deviations) show volatility envelope and relative price position vs. a volatility-adjusted mean. Price outside the upper band suggests pronounced extension relative to recent volatility; price outside the lower band suggests extended weakness. A band expansion (increasing width) signals volatility breakout potential; contraction signals range-bound conditions and potential squeeze. In this dashboard, Bollinger Bands provide the volatility/structural context: RSI extremes plus price beyond the band imply a stronger, volatility-backed move.
Volume split & basic MA trend — role and behavior: Buy-like and sell-like volume (simple heuristic using close>open or closeopen) or sell-like (close1.2 for validation and compare win rate and expectancy.
4. TF alignment: Accept signals only when higher timeframe (e.g., 4h) trend agrees — compare results.
5. Parameter sensitivity: Vary RSI threshold (70/30 vs 80/20), Bollinger stddev (2 vs 2.5), and ADX threshold (25 vs 30) and measure stability of results.
These exercises teach both statistical thinking and the specific failure modes of the mashup.
________________________________________
Limitations, failure modes and caveats (explicit & teachable)
• ADX and Bollinger measures lag during fast-moving news events — signals can be late or wrong during earnings, macro shocks, or illiquid sessions.
• Volume classification by open/close is a heuristic; it does not equal TAPEDATA, footprint or signed volume. Use it as supportive evidence, not definitive proof.
• RSI can remain overbought or oversold for extended stretches in persistent trends — relying solely on RSI extremes without ADX or BB context invites large drawdowns.
• Small-cap or low-liquidity instruments yield noisy band behavior and unreliable volume ratios.
Being explicit about these limitations is a strong point in a TradingView description — it demonstrates transparency and educational intent.
________________________________________
Originality & mashup justification (text you can paste)
This script intentionally combines classical momentum (RSI), volatility envelope (Bollinger Bands) and trend-strength (ADX) because each indicator answers a different and complementary question: RSI answers is price locally extreme?, Bollinger answers is price outside normal volatility?, and ADX answers is the market moving with conviction?. Volume participation then acts as a practical check for real market involvement. This combination is not a simple “indicator mashup”; it is a designed ensemble where each element reduces the others’ failure modes and together produce a teachable, testable signal framework. The script’s purpose is educational and analytical — to show traders how to interpret the interplay of momentum, volatility, and trend strength.
________________________________________
TradingView publication guidance & compliance checklist
To satisfy TradingView rules about mashups and descriptions, include the following items in your script description (without exposing source code):
1. Purpose statement: One or two lines describing the script’s objective (educational multi-indicator market overview and idea filter).
2. Component list: Name the major modules (RSI, Bollinger Bands, ADX, volume heuristic, SMA trend checks, signal tracking) and one-sentence reason for each.
3. How they interact: A succinct non-code explanation: “RSI finds momentum extremes; Bollinger confirms volatility expansion; ADX confirms trend strength; all three must align for a BUY/SELL.”
4. Inputs: List adjustable inputs (RSI length and thresholds, BB length & stddev, ADX threshold & smoothing, volume MA, table position/size).
5. Usage instructions: Short workflow (check TF alignment → confirm participation → define stop & R:R → backtest).
6. Limitations & assumptions: Explicitly state volume is approximated, ADX has lag, and avoid promising guaranteed profits.
7. Non-promotional language: No external contact info, ads, claims of exclusivity or guaranteed outcomes.
8. Trademark clause: If you used trademark symbols, remove or provide registration proof.
9. Risk disclaimer: Add the copy-ready disclaimer below.
This matches TradingView’s request for meaningful descriptions that explain originality and inter-component reasoning.
________________________________________
Copy-ready short publication description (paste into TradingView)
Advanced RSI-ADX-Bollinger Market Overview — educational multi-indicator dashboard. This script combines RSI (momentum extremes), Bollinger Bands (volatility envelope and band expansion), ADX (trend strength), simple SMA trend bias and a basic buy/sell volume heuristic to surface high-quality idea candidates. Signals require alignment of momentum, volatility expansion and rising ADX; volume participation is displayed to support signal confidence. Inputs are configurable (RSI length/levels, BB length/stddev, ADX length/threshold, volume MA, display options). This tool is intended for analysis and learning — not for automated execution. Users should back test and apply robust risk management. Limitations: volume classification here is a heuristic (close>open), ADX and BB measures lag in fast news events, and results vary by instrument liquidity.
________________________________________
Copy-ready risk & misuse disclaimer (paste into description or help file)
This script is provided for educational and analytical purposes only and does not constitute financial or investment advice. It does not guarantee profits. Indicators are heuristics and may give false or late signals; always back test and paper-trade before using real capital. The author is not responsible for trading losses resulting from the use or misuse of this indicator. Use proper position sizing and risk controls.
________________________________________
Risk Disclaimer: This tool is provided for education and analysis only. It is not financial advice and does not guarantee returns. Users assume all risk for trades made based on this script. Back test thoroughly and use proper risk management.
ATAI Volume analysis with price action V 1.00ATAI Volume Analysis with Price Action
1. Introduction
1.1 Overview
ATAI Volume Analysis with Price Action is a composite indicator designed for TradingView. It combines per‑side volume data —that is, how much buying and selling occurs during each bar—with standard price‑structure elements such as swings, trend lines and support/resistance. By blending these elements the script aims to help a trader understand which side is in control, whether a breakout is genuine, when markets are potentially exhausted and where liquidity providers might be active.
The indicator is built around TradingView’s up/down volume feed accessed via the TradingView/ta/10 library. The following excerpt from the script illustrates how this feed is configured:
import TradingView/ta/10 as tvta
// Determine lower timeframe string based on user choice and chart resolution
string lower_tf_breakout = use_custom_tf_input ? custom_tf_input :
timeframe.isseconds ? "1S" :
timeframe.isintraday ? "1" :
timeframe.isdaily ? "5" : "60"
// Request up/down volume (both positive)
= tvta.requestUpAndDownVolume(lower_tf_breakout)
Lower‑timeframe selection. If you do not specify a custom lower timeframe, the script chooses a default based on your chart resolution: 1 second for second charts, 1 minute for intraday charts, 5 minutes for daily charts and 60 minutes for anything longer. Smaller intervals provide a more precise view of buyer and seller flow but cover fewer bars. Larger intervals cover more history at the cost of granularity.
Tick vs. time bars. Many trading platforms offer a tick / intrabar calculation mode that updates an indicator on every trade rather than only on bar close. Turning on one‑tick calculation will give the most accurate split between buy and sell volume on the current bar, but it typically reduces the amount of historical data available. For the highest fidelity in live trading you can enable this mode; for studying longer histories you might prefer to disable it. When volume data is completely unavailable (some instruments and crypto pairs), all modules that rely on it will remain silent and only the price‑structure backbone will operate.
Figure caption, Each panel shows the indicator’s info table for a different volume sampling interval. In the left chart, the parentheses “(5)” beside the buy‑volume figure denote that the script is aggregating volume over five‑minute bars; the center chart uses “(1)” for one‑minute bars; and the right chart uses “(1T)” for a one‑tick interval. These notations tell you which lower timeframe is driving the volume calculations. Shorter intervals such as 1 minute or 1 tick provide finer detail on buyer and seller flow, but they cover fewer bars; longer intervals like five‑minute bars smooth the data and give more history.
Figure caption, The values in parentheses inside the info table come directly from the Breakout — Settings. The first row shows the custom lower-timeframe used for volume calculations (e.g., “(1)”, “(5)”, or “(1T)”)
2. Price‑Structure Backbone
Even without volume, the indicator draws structural features that underpin all other modules. These features are always on and serve as the reference levels for subsequent calculations.
2.1 What it draws
• Pivots: Swing highs and lows are detected using the pivot_left_input and pivot_right_input settings. A pivot high is identified when the high recorded pivot_right_input bars ago exceeds the highs of the preceding pivot_left_input bars and is also higher than (or equal to) the highs of the subsequent pivot_right_input bars; pivot lows follow the inverse logic. The indicator retains only a fixed number of such pivot points per side, as defined by point_count_input, discarding the oldest ones when the limit is exceeded.
• Trend lines: For each side, the indicator connects the earliest stored pivot and the most recent pivot (oldest high to newest high, and oldest low to newest low). When a new pivot is added or an old one drops out of the lookback window, the line’s endpoints—and therefore its slope—are recalculated accordingly.
• Horizontal support/resistance: The highest high and lowest low within the lookback window defined by length_input are plotted as horizontal dashed lines. These serve as short‑term support and resistance levels.
• Ranked labels: If showPivotLabels is enabled the indicator prints labels such as “HH1”, “HH2”, “LL1” and “LL2” near each pivot. The ranking is determined by comparing the price of each stored pivot: HH1 is the highest high, HH2 is the second highest, and so on; LL1 is the lowest low, LL2 is the second lowest. In the case of equal prices the newer pivot gets the better rank. Labels are offset from price using ½ × ATR × label_atr_multiplier, with the ATR length defined by label_atr_len_input. A dotted connector links each label to the candle’s wick.
2.2 Key settings
• length_input: Window length for finding the highest and lowest values and for determining trend line endpoints. A larger value considers more history and will generate longer trend lines and S/R levels.
• pivot_left_input, pivot_right_input: Strictness of swing confirmation. Higher values require more bars on either side to form a pivot; lower values create more pivots but may include minor swings.
• point_count_input: How many pivots are kept in memory on each side. When new pivots exceed this number the oldest ones are discarded.
• label_atr_len_input and label_atr_multiplier: Determine how far pivot labels are offset from the bar using ATR. Increasing the multiplier moves labels further away from price.
• Styling inputs for trend lines, horizontal lines and labels (color, width and line style).
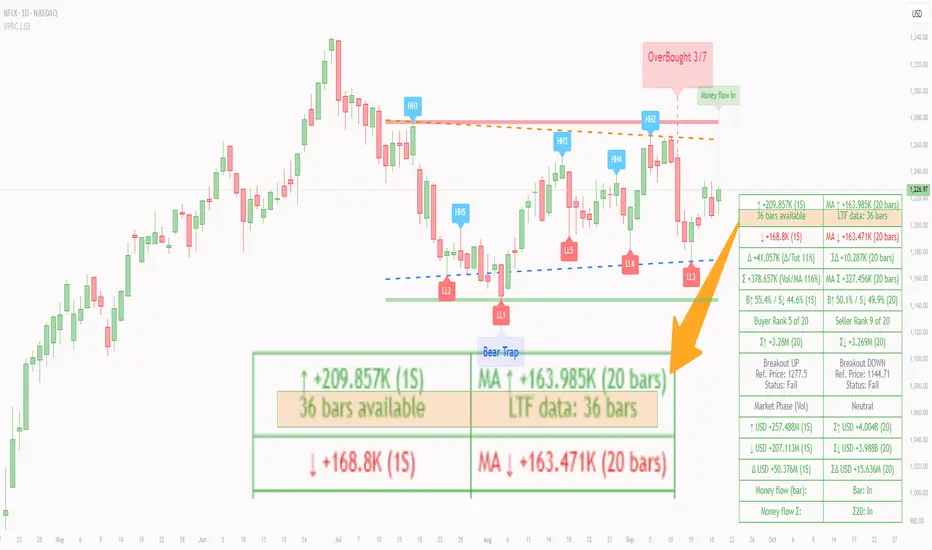
Figure caption, The chart illustrates how the indicator’s price‑structure backbone operates. In this daily example, the script scans for bars where the high (or low) pivot_right_input bars back is higher (or lower) than the preceding pivot_left_input bars and higher or lower than the subsequent pivot_right_input bars; only those bars are marked as pivots.
These pivot points are stored and ranked: the highest high is labelled “HH1”, the second‑highest “HH2”, and so on, while lows are marked “LL1”, “LL2”, etc. Each label is offset from the price by half of an ATR‑based distance to keep the chart clear, and a dotted connector links the label to the actual candle.
The red diagonal line connects the earliest and latest stored high pivots, and the green line does the same for low pivots; when a new pivot is added or an old one drops out of the lookback window, the end‑points and slopes adjust accordingly. Dashed horizontal lines mark the highest high and lowest low within the current lookback window, providing visual support and resistance levels. Together, these elements form the structural backbone that other modules reference, even when volume data is unavailable.
3. Breakout Module
3.1 Concept
This module confirms that a price break beyond a recent high or low is supported by a genuine shift in buying or selling pressure. It requires price to clear the highest high (“HH1”) or lowest low (“LL1”) and, simultaneously, that the winning side shows a significant volume spike, dominance and ranking. Only when all volume and price conditions pass is a breakout labelled.
3.2 Inputs
• lookback_break_input : This controls the number of bars used to compute moving averages and percentiles for volume. A larger value smooths the averages and percentiles but makes the indicator respond more slowly.
• vol_mult_input : The “spike” multiplier; the current buy or sell volume must be at least this multiple of its moving average over the lookback window to qualify as a breakout.
• rank_threshold_input (0–100) : Defines a volume percentile cutoff: the current buyer/seller volume must be in the top (100−threshold)%(100−threshold)% of all volumes within the lookback window. For example, if set to 80, the current volume must be in the top 20 % of the lookback distribution.
• ratio_threshold_input (0–1) : Specifies the minimum share of total volume that the buyer (for a bullish breakout) or seller (for bearish) must hold on the current bar; the code also requires that the cumulative buyer volume over the lookback window exceeds the seller volume (and vice versa for bearish cases).
• use_custom_tf_input / custom_tf_input : When enabled, these inputs override the automatic choice of lower timeframe for up/down volume; otherwise the script selects a sensible default based on the chart’s timeframe.
• Label appearance settings : Separate options control the ATR-based offset length, offset multiplier, label size and colors for bullish and bearish breakout labels, as well as the connector style and width.
3.3 Detection logic
1. Data preparation : Retrieve per‑side volume from the lower timeframe and take absolute values. Build rolling arrays of the last lookback_break_input values to compute simple moving averages (SMAs), cumulative sums and percentile ranks for buy and sell volume.
2. Volume spike: A spike is flagged when the current buy (or, in the bearish case, sell) volume is at least vol_mult_input times its SMA over the lookback window.
3. Dominance test: The buyer’s (or seller’s) share of total volume on the current bar must meet or exceed ratio_threshold_input. In addition, the cumulative sum of buyer volume over the window must exceed the cumulative sum of seller volume for a bullish breakout (and vice versa for bearish). A separate requirement checks the sign of delta: for bullish breakouts delta_breakout must be non‑negative; for bearish breakouts it must be non‑positive.
4. Percentile rank: The current volume must fall within the top (100 – rank_threshold_input) percent of the lookback distribution—ensuring that the spike is unusually large relative to recent history.
5. Price test: For a bullish signal, the closing price must close above the highest pivot (HH1); for a bearish signal, the close must be below the lowest pivot (LL1).
6. Labeling: When all conditions above are satisfied, the indicator prints “Breakout ↑” above the bar (bullish) or “Breakout ↓” below the bar (bearish). Labels are offset using half of an ATR‑based distance and linked to the candle with a dotted connector.
Figure caption, (Breakout ↑ example) , On this daily chart, price pushes above the red trendline and the highest prior pivot (HH1). The indicator recognizes this as a valid breakout because the buyer‑side volume on the lower timeframe spikes above its recent moving average and buyers dominate the volume statistics over the lookback period; when combined with a close above HH1, this satisfies the breakout conditions. The “Breakout ↑” label appears above the candle, and the info table highlights that up‑volume is elevated relative to its 11‑bar average, buyer share exceeds the dominance threshold and money‑flow metrics support the move.
Figure caption, In this daily example, price breaks below the lowest pivot (LL1) and the lower green trendline. The indicator identifies this as a bearish breakout because sell‑side volume is sharply elevated—about twice its 11‑bar average—and sellers dominate both the bar and the lookback window. With the close falling below LL1, the script triggers a Breakout ↓ label and marks the corresponding row in the info table, which shows strong down volume, negative delta and a seller share comfortably above the dominance threshold.
4. Market Phase Module (Volume Only)
4.1 Concept
Not all markets trend; many cycle between periods of accumulation (buying pressure building up), distribution (selling pressure dominating) and neutral behavior. This module classifies the current bar into one of these phases without using ATR , relying solely on buyer and seller volume statistics. It looks at net flows, ratio changes and an OBV‑like cumulative line with dual‑reference (1‑ and 2‑bar) trends. The result is displayed both as on‑chart labels and in a dedicated row of the info table.
4.2 Inputs
• phase_period_len: Number of bars over which to compute sums and ratios for phase detection.
• phase_ratio_thresh : Minimum buyer share (for accumulation) or minimum seller share (for distribution, derived as 1 − phase_ratio_thresh) of the total volume.
• strict_mode: When enabled, both the 1‑bar and 2‑bar changes in each statistic must agree on the direction (strict confirmation); when disabled, only one of the two references needs to agree (looser confirmation).
• Color customisation for info table cells and label styling for accumulation and distribution phases, including ATR length, multiplier, label size, colors and connector styles.
• show_phase_module: Toggles the entire phase detection subsystem.
• show_phase_labels: Controls whether on‑chart labels are drawn when accumulation or distribution is detected.
4.3 Detection logic
The module computes three families of statistics over the volume window defined by phase_period_len:
1. Net sum (buyers minus sellers): net_sum_phase = Σ(buy) − Σ(sell). A positive value indicates a predominance of buyers. The code also computes the differences between the current value and the values 1 and 2 bars ago (d_net_1, d_net_2) to derive up/down trends.
2. Buyer ratio: The instantaneous ratio TF_buy_breakout / TF_tot_breakout and the window ratio Σ(buy) / Σ(total). The current ratio must exceed phase_ratio_thresh for accumulation or fall below 1 − phase_ratio_thresh for distribution. The first and second differences of the window ratio (d_ratio_1, d_ratio_2) determine trend direction.
3. OBV‑like cumulative net flow: An on‑balance volume analogue obv_net_phase increments by TF_buy_breakout − TF_sell_breakout each bar. Its differences over the last 1 and 2 bars (d_obv_1, d_obv_2) provide trend clues.
The algorithm then combines these signals:
• For strict mode , accumulation requires: (a) current ratio ≥ threshold, (b) cumulative ratio ≥ threshold, (c) both ratio differences ≥ 0, (d) net sum differences ≥ 0, and (e) OBV differences ≥ 0. Distribution is the mirror case.
• For loose mode , it relaxes the directional tests: either the 1‑ or the 2‑bar difference needs to agree in each category.
If all conditions for accumulation are satisfied, the phase is labelled “Accumulation” ; if all conditions for distribution are satisfied, it’s labelled “Distribution” ; otherwise the phase is “Neutral” .
4.4 Outputs
• Info table row : Row 8 displays “Market Phase (Vol)” on the left and the detected phase (Accumulation, Distribution or Neutral) on the right. The text colour of both cells matches a user‑selectable palette (typically green for accumulation, red for distribution and grey for neutral).
• On‑chart labels : When show_phase_labels is enabled and a phase persists for at least one bar, the module prints a label above the bar ( “Accum” ) or below the bar ( “Dist” ) with a dashed or dotted connector. The label is offset using ATR based on phase_label_atr_len_input and phase_label_multiplier and is styled according to user preferences.
Figure caption, The chart displays a red “Dist” label above a particular bar, indicating that the accumulation/distribution module identified a distribution phase at that point. The detection is based on seller dominance: during that bar, the net buyer-minus-seller flow and the OBV‑style cumulative flow were trending down, and the buyer ratio had dropped below the preset threshold. These conditions satisfy the distribution criteria in strict mode. The label is placed above the bar using an ATR‑based offset and a dashed connector. By the time of the current bar in the screenshot, the phase indicator shows “Neutral” in the info table—signaling that neither accumulation nor distribution conditions are currently met—yet the historical “Dist” label remains to mark where the prior distribution phase began.
Figure caption, In this example the market phase module has signaled an Accumulation phase. Three bars before the current candle, the algorithm detected a shift toward buyers: up‑volume exceeded its moving average, down‑volume was below average, and the buyer share of total volume climbed above the threshold while the on‑balance net flow and cumulative ratios were trending upwards. The blue “Accum” label anchored below that bar marks the start of the phase; it remains on the chart because successive bars continue to satisfy the accumulation conditions. The info table confirms this: the “Market Phase (Vol)” row still reads Accumulation, and the ratio and sum rows show buyers dominating both on the current bar and across the lookback window.
5. OB/OS Spike Module
5.1 What overbought/oversold means here
In many markets, a rapid extension up or down is often followed by a period of consolidation or reversal. The indicator interprets overbought (OB) conditions as abnormally strong selling risk at or after a price rally and oversold (OS) conditions as unusually strong buying risk after a decline. Importantly, these are not direct trade signals; rather they flag areas where caution or contrarian setups may be appropriate.
5.2 Inputs
• minHits_obos (1–7): Minimum number of oscillators that must agree on an overbought or oversold condition for a label to print.
• syncWin_obos: Length of a small sliding window over which oscillator votes are smoothed by taking the maximum count observed. This helps filter out choppy signals.
• Volume spike criteria: kVolRatio_obos (ratio of current volume to its SMA) and zVolThr_obos (Z‑score threshold) across volLen_obos. Either threshold can trigger a spike.
• Oscillator toggles and periods: Each of RSI, Stochastic (K and D), Williams %R, CCI, MFI, DeMarker and Stochastic RSI can be independently enabled; their periods are adjustable.
• Label appearance: ATR‑based offset, size, colors for OB and OS labels, plus connector style and width.
5.3 Detection logic
1. Directional volume spikes: Volume spikes are computed separately for buyer and seller volumes. A sell volume spike (sellVolSpike) flags a potential OverBought bar, while a buy volume spike (buyVolSpike) flags a potential OverSold bar. A spike occurs when the respective volume exceeds kVolRatio_obos times its simple moving average over the window or when its Z‑score exceeds zVolThr_obos.
2. Oscillator votes: For each enabled oscillator, calculate its overbought and oversold state using standard thresholds (e.g., RSI ≥ 70 for OB and ≤ 30 for OS; Stochastic %K/%D ≥ 80 for OB and ≤ 20 for OS; etc.). Count how many oscillators vote for OB and how many vote for OS.
3. Minimum hits: Apply the smoothing window syncWin_obos to the vote counts using a maximum‑of‑last‑N approach. A candidate bar is only considered if the smoothed OB hit count ≥ minHits_obos (for OverBought) or the smoothed OS hit count ≥ minHits_obos (for OverSold).
4. Tie‑breaking: If both OverBought and OverSold spike conditions are present on the same bar, compare the smoothed hit counts: the side with the higher count is selected; ties default to OverBought.
5. Label printing: When conditions are met, the bar is labelled as “OverBought X/7” above the candle or “OverSold X/7” below it. “X” is the number of oscillators confirming, and the bracket lists the abbreviations of contributing oscillators. Labels are offset from price using half of an ATR‑scaled distance and can optionally include a dotted or dashed connector line.
Figure caption, In this chart the overbought/oversold module has flagged an OverSold signal. A sell‑off from the prior highs brought price down to the lower trend‑line, where the bar marked “OverSold 3/7 DeM” appears. This label indicates that on that bar the module detected a buy‑side volume spike and that at least three of the seven enabled oscillators—in this case including the DeMarker—were in oversold territory. The label is printed below the candle with a dotted connector, signaling that the market may be temporarily exhausted on the downside. After this oversold print, price begins to rebound towards the upper red trend‑line and higher pivot levels.
Figure caption, This example shows the overbought/oversold module in action. In the left‑hand panel you can see the OB/OS settings where each oscillator (RSI, Stochastic, Williams %R, CCI, MFI, DeMarker and Stochastic RSI) can be enabled or disabled, and the ATR length and label offset multiplier adjusted. On the chart itself, price has pushed up to the descending red trendline and triggered an “OverBought 3/7” label. That means the sell‑side volume spiked relative to its average and three out of the seven enabled oscillators were in overbought territory. The label is offset above the candle by half of an ATR and connected with a dashed line, signaling that upside momentum may be overextended and a pause or pullback could follow.
6. Buyer/Seller Trap Module
6.1 Concept
A bull trap occurs when price appears to break above resistance, attracting buyers, but fails to sustain the move and quickly reverses, leaving a long upper wick and trapping late entrants. A bear trap is the opposite: price breaks below support, lures in sellers, then snaps back, leaving a long lower wick and trapping shorts. This module detects such traps by looking for price structure sweeps, order‑flow mismatches and dominance reversals. It uses a scoring system to differentiate risk from confirmed traps.
6.2 Inputs
• trap_lookback_len: Window length used to rank extremes and detect sweeps.
• trap_wick_threshold: Minimum proportion of a bar’s range that must be wick (upper for bull traps, lower for bear traps) to qualify as a sweep.
• trap_score_risk: Minimum aggregated score required to flag a trap risk. (The code defines a trap_score_confirm input, but confirmation is actually based on price reversal rather than a separate score threshold.)
• trap_confirm_bars: Maximum number of bars allowed for price to reverse and confirm the trap. If price does not reverse in this window, the risk label will expire or remain unconfirmed.
• Label settings: ATR length and multiplier for offsetting, size, colours for risk and confirmed labels, and connector style and width. Separate settings exist for bull and bear traps.
• Toggle inputs: show_trap_module and show_trap_labels enable the module and control whether labels are drawn on the chart.
6.3 Scoring logic
The module assigns points to several conditions and sums them to determine whether a trap risk is present. For bull traps, the score is built from the following (bear traps mirror the logic with highs and lows swapped):
1. Sweep (2 points): Price trades above the high pivot (HH1) but fails to close above it and leaves a long upper wick at least trap_wick_threshold × range. For bear traps, price dips below the low pivot (LL1), fails to close below and leaves a long lower wick.
2. Close break (1 point): Price closes beyond HH1 or LL1 without leaving a long wick.
3. Candle/delta mismatch (2 points): The candle closes bullish yet the order flow delta is negative or the seller ratio exceeds 50%, indicating hidden supply. Conversely, a bearish close with positive delta or buyer dominance suggests hidden demand.
4. Dominance inversion (2 points): The current bar’s buyer volume has the highest rank in the lookback window while cumulative sums favor sellers, or vice versa.
5. Low‑volume break (1 point): Price crosses the pivot but total volume is below its moving average.
The total score for each side is compared to trap_score_risk. If the score is high enough, a “Bull Trap Risk” or “Bear Trap Risk” label is drawn, offset from the candle by half of an ATR‑scaled distance using a dashed outline. If, within trap_confirm_bars, price reverses beyond the opposite level—drops back below the high pivot for bull traps or rises above the low pivot for bear traps—the label is upgraded to a solid “Bull Trap” or “Bear Trap” . In this version of the code, there is no separate score threshold for confirmation: the variable trap_score_confirm is unused; confirmation depends solely on a successful price reversal within the specified number of bars.
Figure caption, In this example the trap module has flagged a Bear Trap Risk. Price initially breaks below the most recent low pivot (LL1), but the bar closes back above that level and leaves a long lower wick, suggesting a failed push lower. Combined with a mismatch between the candle direction and the order flow (buyers regain control) and a reversal in volume dominance, the aggregate score exceeds the risk threshold, so a dashed “Bear Trap Risk” label prints beneath the bar. The green and red trend lines mark the current low and high pivot trajectories, while the horizontal dashed lines show the highest and lowest values in the lookback window. If, within the next few bars, price closes decisively above the support, the risk label would upgrade to a solid “Bear Trap” label.
Figure caption, In this example the trap module has identified both ends of a price range. Near the highs, price briefly pushes above the descending red trendline and the recent pivot high, but fails to close there and leaves a noticeable upper wick. That combination of a sweep above resistance and order‑flow mismatch generates a Bull Trap Risk label with a dashed outline, warning that the upside break may not hold. At the opposite extreme, price later dips below the green trendline and the labelled low pivot, then quickly snaps back and closes higher. The long lower wick and subsequent price reversal upgrade the previous bear‑trap risk into a confirmed Bear Trap (solid label), indicating that sellers were caught on a false breakdown. Horizontal dashed lines mark the highest high and lowest low of the lookback window, while the red and green diagonals connect the earliest and latest pivot highs and lows to visualize the range.
7. Sharp Move Module
7.1 Concept
Markets sometimes display absorption or climax behavior—periods when one side steadily gains the upper hand before price breaks out with a sharp move. This module evaluates several order‑flow and volume conditions to anticipate such moves. Users can choose how many conditions must be met to flag a risk and how many (plus a price break) are required for confirmation.
7.2 Inputs
• sharp Lookback: Number of bars in the window used to compute moving averages, sums, percentile ranks and reference levels.
• sharpPercentile: Minimum percentile rank for the current side’s volume; the current buy (or sell) volume must be greater than or equal to this percentile of historical volumes over the lookback window.
• sharpVolMult: Multiplier used in the volume climax check. The current side’s volume must exceed this multiple of its average to count as a climax.
• sharpRatioThr: Minimum dominance ratio (current side’s volume relative to the opposite side) used in both the instant and cumulative dominance checks.
• sharpChurnThr: Maximum ratio of a bar’s range to its ATR for absorption/churn detection; lower values indicate more absorption (large volume in a small range).
• sharpScoreRisk: Minimum number of conditions that must be true to print a risk label.
• sharpScoreConfirm: Minimum number of conditions plus a price break required for confirmation.
• sharpCvdThr: Threshold for cumulative delta divergence versus price change (positive for bullish accumulation, negative for bearish distribution).
• Label settings: ATR length (sharpATRlen) and multiplier (sharpLabelMult) for positioning labels, label size, colors and connector styles for bullish and bearish sharp moves.
• Toggles: enableSharp activates the module; show_sharp_labels controls whether labels are drawn.
7.3 Conditions (six per side)
For each side, the indicator computes six boolean conditions and sums them to form a score:
1. Dominance (instant and cumulative):
– Instant dominance: current buy volume ≥ sharpRatioThr × current sell volume.
– Cumulative dominance: sum of buy volumes over the window ≥ sharpRatioThr × sum of sell volumes (and vice versa for bearish checks).
2. Accumulation/Distribution divergence: Over the lookback window, cumulative delta rises by at least sharpCvdThr while price fails to rise (bullish), or cumulative delta falls by at least sharpCvdThr while price fails to fall (bearish).
3. Volume climax: The current side’s volume is ≥ sharpVolMult × its average and the product of volume and bar range is the highest in the lookback window.
4. Absorption/Churn: The current side’s volume divided by the bar’s range equals the highest value in the window and the bar’s range divided by ATR ≤ sharpChurnThr (indicating large volume within a small range).
5. Percentile rank: The current side’s volume percentile rank is ≥ sharp Percentile.
6. Mirror logic for sellers: The above checks are repeated with buyer and seller roles swapped and the price break levels reversed.
Each condition that passes contributes one point to the corresponding side’s score (0 or 1). Risk and confirmation thresholds are then applied to these scores.
7.4 Scoring and labels
• Risk: If scoreBull ≥ sharpScoreRisk, a “Sharp ↑ Risk” label is drawn above the bar. If scoreBear ≥ sharpScoreRisk, a “Sharp ↓ Risk” label is drawn below the bar.
• Confirmation: A risk label is upgraded to “Sharp ↑” when scoreBull ≥ sharpScoreConfirm and the bar closes above the highest recent pivot (HH1); for bearish cases, confirmation requires scoreBear ≥ sharpScoreConfirm and a close below the lowest pivot (LL1).
• Label positioning: Labels are offset from the candle by ATR × sharpLabelMult (full ATR times multiplier), not half, and may include a dashed or dotted connector line if enabled.
Figure caption, In this chart both bullish and bearish sharp‑move setups have been flagged. Earlier in the range, a “Sharp ↓ Risk” label appears beneath a candle: the sell‑side score met the risk threshold, signaling that the combination of strong sell volume, dominance and absorption within a narrow range suggested a potential sharp decline. The price did not close below the lower pivot, so this label remains a “risk” and no confirmation occurred. Later, as the market recovered and volume shifted back to the buy side, a “Sharp ↑ Risk” label prints above a candle near the top of the channel. Here, buy‑side dominance, cumulative delta divergence and a volume climax aligned, but price has not yet closed above the upper pivot (HH1), so the alert is still a risk rather than a confirmed sharp‑up move.
Figure caption, In this chart a Sharp ↑ label is displayed above a candle, indicating that the sharp move module has confirmed a bullish breakout. Prior bars satisfied the risk threshold — showing buy‑side dominance, positive cumulative delta divergence, a volume climax and strong absorption in a narrow range — and this candle closes above the highest recent pivot, upgrading the earlier “Sharp ↑ Risk” alert to a full Sharp ↑ signal. The green label is offset from the candle with a dashed connector, while the red and green trend lines trace the high and low pivot trajectories and the dashed horizontals mark the highest and lowest values of the lookback window.
8. Market‑Maker / Spread‑Capture Module
8.1 Concept
Liquidity providers often “capture the spread” by buying and selling in almost equal amounts within a very narrow price range. These bars can signal temporary congestion before a move or reflect algorithmic activity. This module flags bars where both buyer and seller volumes are high, the price range is only a few ticks and the buy/sell split remains close to 50%. It helps traders spot potential liquidity pockets.
8.2 Inputs
• scalpLookback: Window length used to compute volume averages.
• scalpVolMult: Multiplier applied to each side’s average volume; both buy and sell volumes must exceed this multiple.
• scalpTickCount: Maximum allowed number of ticks in a bar’s range (calculated as (high − low) / minTick). A value of 1 or 2 captures ultra‑small bars; increasing it relaxes the range requirement.
• scalpDeltaRatio: Maximum deviation from a perfect 50/50 split. For example, 0.05 means the buyer share must be between 45% and 55%.
• Label settings: ATR length, multiplier, size, colors, connector style and width.
• Toggles : show_scalp_module and show_scalp_labels to enable the module and its labels.
8.3 Signal
When, on the current bar, both TF_buy_breakout and TF_sell_breakout exceed scalpVolMult times their respective averages and (high − low)/minTick ≤ scalpTickCount and the buyer share is within scalpDeltaRatio of 50%, the module prints a “Spread ↔” label above the bar. The label uses the same ATR offset logic as other modules and draws a connector if enabled.
Figure caption, In this chart the spread‑capture module has identified a potential liquidity pocket. Buyer and seller volumes both spiked above their recent averages, yet the candle’s range measured only a couple of ticks and the buy/sell split stayed close to 50 %. This combination met the module’s criteria, so it printed a grey “Spread ↔” label above the bar. The red and green trend lines link the earliest and latest high and low pivots, and the dashed horizontals mark the highest high and lowest low within the current lookback window.
9. Money Flow Module
9.1 Concept
To translate volume into a monetary measure, this module multiplies each side’s volume by the closing price. It tracks buying and selling system money default currency on a per-bar basis and sums them over a chosen period. The difference between buy and sell currencies (Δ$) shows net inflow or outflow.
9.2 Inputs
• mf_period_len_mf: Number of bars used for summing buy and sell dollars.
• Label appearance settings: ATR length, multiplier, size, colors for up/down labels, and connector style and width.
• Toggles: Use enableMoneyFlowLabel_mf and showMFLabels to control whether the module and its labels are displayed.
9.3 Calculations
• Per-bar money: Buy $ = TF_buy_breakout × close; Sell $ = TF_sell_breakout × close. Their difference is Δ$ = Buy $ − Sell $.
• Summations: Over mf_period_len_mf bars, compute Σ Buy $, Σ Sell $ and ΣΔ$ using math.sum().
• Info table entries: Rows 9–13 display these values as texts like “↑ USD 1234 (1M)” or “ΣΔ USD −5678 (14)”, with colors reflecting whether buyers or sellers dominate.
• Money flow status: If Δ$ is positive the bar is marked “Money flow in” ; if negative, “Money flow out” ; if zero, “Neutral”. The cumulative status is similarly derived from ΣΔ.Labels print at the bar that changes the sign of ΣΔ, offset using ATR × label multiplier and styled per user preferences.
Figure caption, The chart illustrates a steady rise toward the highest recent pivot (HH1) with price riding between a rising green trend‑line and a red trend‑line drawn through earlier pivot highs. A green Money flow in label appears above the bar near the top of the channel, signaling that net dollar flow turned positive on this bar: buy‑side dollar volume exceeded sell‑side dollar volume, pushing the cumulative sum ΣΔ$ above zero. In the info table, the “Money flow (bar)” and “Money flow Σ” rows both read In, confirming that the indicator’s money‑flow module has detected an inflow at both bar and aggregate levels, while other modules (pivots, trend lines and support/resistance) remain active to provide structural context.
In this example the Money Flow module signals a net outflow. Price has been trending downward: successive high pivots form a falling red trend‑line and the low pivots form a descending green support line. When the latest bar broke below the previous low pivot (LL1), both the bar‑level and cumulative net dollar flow turned negative—selling volume at the close exceeded buying volume and pushed the cumulative Δ$ below zero. The module reacts by printing a red “Money flow out” label beneath the candle; the info table confirms that the “Money flow (bar)” and “Money flow Σ” rows both show Out, indicating sustained dominance of sellers in this period.
10. Info Table
10.1 Purpose
When enabled, the Info Table appears in the lower right of your chart. It summarises key values computed by the indicator—such as buy and sell volume, delta, total volume, breakout status, market phase, and money flow—so you can see at a glance which side is dominant and which signals are active.
10.2 Symbols
• ↑ / ↓ — Up (↑) denotes buy volume or money; down (↓) denotes sell volume or money.
• MA — Moving average. In the table it shows the average value of a series over the lookback period.
• Σ (Sigma) — Cumulative sum over the chosen lookback period.
• Δ (Delta) — Difference between buy and sell values.
• B / S — Buyer and seller share of total volume, expressed as percentages.
• Ref. Price — Reference price for breakout calculations, based on the latest pivot.
• Status — Indicates whether a breakout condition is currently active (True) or has failed.
10.3 Row definitions
1. Up volume / MA up volume – Displays current buy volume on the lower timeframe and its moving average over the lookback period.
2. Down volume / MA down volume – Shows current sell volume and its moving average; sell values are formatted in red for clarity.
3. Δ / ΣΔ – Lists the difference between buy and sell volume for the current bar and the cumulative delta volume over the lookback period.
4. Σ / MA Σ (Vol/MA) – Total volume (buy + sell) for the bar, with the ratio of this volume to its moving average; the right cell shows the average total volume.
5. B/S ratio – Buy and sell share of the total volume: current bar percentages and the average percentages across the lookback period.
6. Buyer Rank / Seller Rank – Ranks the bar’s buy and sell volumes among the last (n) bars; lower rank numbers indicate higher relative volume.
7. Σ Buy / Σ Sell – Sum of buy and sell volumes over the lookback window, indicating which side has traded more.
8. Breakout UP / DOWN – Shows the breakout thresholds (Ref. Price) and whether the breakout condition is active (True) or has failed.
9. Market Phase (Vol) – Reports the current volume‑only phase: Accumulation, Distribution or Neutral.
10. Money Flow – The final rows display dollar amounts and status:
– ↑ USD / Σ↑ USD – Buy dollars for the current bar and the cumulative sum over the money‑flow period.
– ↓ USD / Σ↓ USD – Sell dollars and their cumulative sum.
– Δ USD / ΣΔ USD – Net dollar difference (buy minus sell) for the bar and cumulatively.
– Money flow (bar) – Indicates whether the bar’s net dollar flow is positive (In), negative (Out) or neutral.
– Money flow Σ – Shows whether the cumulative net dollar flow across the chosen period is positive, negative or neutral.
The chart above shows a sequence of different signals from the indicator. A Bull Trap Risk appears after price briefly pushes above resistance but fails to hold, then a green Accum label identifies an accumulation phase. An upward breakout follows, confirmed by a Money flow in print. Later, a Sharp ↓ Risk warns of a possible sharp downturn; after price dips below support but quickly recovers, a Bear Trap label marks a false breakdown. The highlighted info table in the center summarizes key metrics at that moment, including current and average buy/sell volumes, net delta, total volume versus its moving average, breakout status (up and down), market phase (volume), and bar‑level and cumulative money flow (In/Out).
11. Conclusion & Final Remarks
This indicator was developed as a holistic study of market structure and order flow. It brings together several well‑known concepts from technical analysis—breakouts, accumulation and distribution phases, overbought and oversold extremes, bull and bear traps, sharp directional moves, market‑maker spread bars and money flow—into a single Pine Script tool. Each module is based on widely recognized trading ideas and was implemented after consulting reference materials and example strategies, so you can see in real time how these concepts interact on your chart.
A distinctive feature of this indicator is its reliance on per‑side volume: instead of tallying only total volume, it separately measures buy and sell transactions on a lower time frame. This approach gives a clearer view of who is in control—buyers or sellers—and helps filter breakouts, detect phases of accumulation or distribution, recognize potential traps, anticipate sharp moves and gauge whether liquidity providers are active. The money‑flow module extends this analysis by converting volume into currency values and tracking net inflow or outflow across a chosen window.
Although comprehensive, this indicator is intended solely as a guide. It highlights conditions and statistics that many traders find useful, but it does not generate trading signals or guarantee results. Ultimately, you remain responsible for your positions. Use the information presented here to inform your analysis, combine it with other tools and risk‑management techniques, and always make your own decisions when trading.
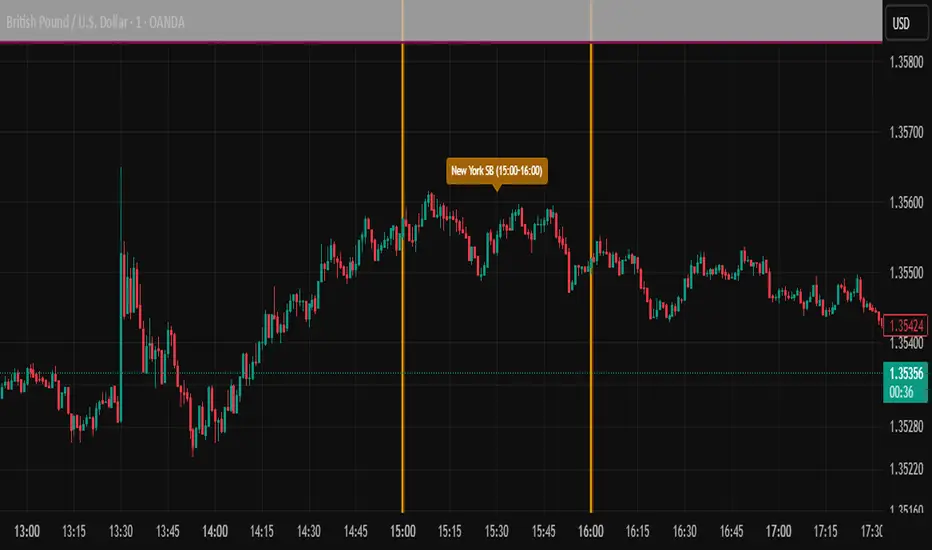
ICT SIlver Bullet Trading Windows UK times🎯 Purpose of the Indicator
It’s designed to highlight key ICT “macro” and “micro” windows of opportunity, i.e., time ranges where liquidity grabs and algorithmic setups are most likely to occur. The ICT Silver Bullet concept is built on the idea that institutions execute in recurring intraday windows, and these often produce high-probability setups.
🕰️ Windows
London Macro Window
10:00 – 11:00 UK time
This aligns with a major liquidity window after the London equities open settles and London + EU traders reposition.
You’re looking for setups like liquidity sweeps, MSS (market structure shift), and FVG entries here.
New York Macro Window
15:00 – 16:00 UK time (10:00 – 11:00 NY time)
This is right after the NY equities open, a key ICT window for volatility and liquidity grabs.
Power Hour
Usually 20:00 – 21:00 UK time (3pm–4pm NY time), the last trading hour of NY equities.
ICT often refers to this as another manipulation window where setups can form before the daily close.
🔍 What the Indicator Does
Draws session boxes or shading: so you can visually see the London/NY/Power Hour windows directly on your chart.
Macro vs. Micro time frames:
Macro windows → The ones you set (London & NY) are the major daily algo execution windows.
Micro windows → Within those boxes, ICT expects smaller intraday setups (like a Silver Bullet entry from a sweep + FVG).
Guides your trade selection: it tells you when not to hunt trades everywhere, but instead to wait for price action confirmation inside those boxes.
🧩 How This Fits ICT Silver Bullet Trading
The ICT Silver Bullet strategy says:
Wait for one of the macro windows (London or NY).
Look for liquidity sweep → market structure shift → FVG.
Enter with defined risk inside that hour.
This indicator essentially does step 1 for you: it makes those high-probability windows visually obvious, so you don’t waste time trading random hours where algos aren’t active.
Stop Loss vs Take Profit Probability and EVThis stop loss and take profit calculator uses a Monte Carlo simulation to calculate the probability of hitting your Stop Loss or Take Profit levels across different time horizons (expressed in bars).
It provides data-driven insights to optimize your risk management and position sizing by showing Expected Value for each scenario.
As a quant, I love using statistical data to help my decisions and get better EV from my trades.
🔬 How It's Calculated
Monte Carlo Simulation: Runs 1,000-10,000 price simulations using a random walk model
Volatility Analysis: Combines ATR-based and Historical Volatility for accurate price movement modeling
Expected Value: Calculates profit/loss expectation using formula: (TP_Probability × Reward) - (SL_Probability × Risk)
Time Horizons: Tests multiple timeframes (1, 5, 10, 20, 50 bars) to find optimal holding periods
Risk/Reward Ratios: Automatically calculates and displays R:R ratios for quick assessment
💡 Use Cases
Position Sizing - Determine optimal risk per trade based on Expected Value
Time Horizon Optimization - Find the best holding period for your strategy
Stop Loss Placement - Validate SL levels using probability analysis
Take Profit Optimization - Set TP levels with statistical backing
Strategy Backtesting - Compare different R:R setups before entering trades
Risk Management - Avoid trades with negative Expected Value
Swing vs Day Trading - Choose timeframes with highest success probability
🎯 How to Use
Setup Trade: Enter your entry price, stop loss, and take profit levels
You can add or remove time horizons denominated in bars. Say you are looking at 1h candles, adding a 24-bar time horizon means you are looking into 24 hours
Choose Direction: Select Long or Short position
Review Table
Analyze Expected Value: Focus on positive EV scenarios (green background)
Optimize Timing: Select time horizons with best risk/reward profile
Adjust Parameters: Modify volatility calculation method and simulation count if needed
Examples
Here's how you can read the tables.
Example 1:
In this chart, we are analyzing the TP and SL probabilities as well as the EV (expected value) for a stock. I want to check what the likelihood is that my SL and TP get triggered over the next 5 days. The stock market is open for 6.5 hours per day, which is 13 bars in this 30-minute bar chart. 26 bars is 2 days, 39 bars is 3 days and so on.
Although this trade is more likely to trigger my SL than my TP, in some of the time horizons we have a positive expected value because of the risk/reward of our trade (i.e. distance of the SL and TP from the price) and the probability of hitting SL and TP.
Example 2:
In this example, we have applied the indicator to gold. Because the TP is much closer to the price, the probability of hitting the TP is much higher.
We can also observe that the expected Value in the shorter time frames is better than in the longer ones. This can give us some clues to set up our trade. If we know that the EV is positive, we can allocate more to that specific trade.
Enjoy, and please let me know your feedback! 😊🥂

Market Opening Time### TradingView Pine Script "Market Opening Time" Explanation
This Pine Script (`@version=5`) is an indicator that visually highlights market trading sessions (Sydney, London, New York, etc.) by changing the chart's background color. It adjusts for U.S. and Australian Daylight Saving Time (DST).
---
#### **1. Overview**
- **Purpose**: Changes the chart's background color based on UTC time zones to highlight market sessions.
- **Features**:
- Automatically adjusts for U.S. DST (2nd Sunday of March to 1st Sunday of November) and Australian DST (1st Sunday of October to 1st Sunday of April).
- Assigns colors to four time zones (00:00, 06:30, 14:00, 21:00).
- **Use Case**: Helps forex/stock traders identify active market sessions.
---
#### **2. Key Logic**
- **DST Detection**:
- `f_isUSDst`: Checks U.S. DST status.
- `f_isAustraliaDst`: Checks Australian DST status.
- **Time Adjustment** (`f_getAdjustedTime`):
- U.S. DST off: Shifts `time3` (14:00) forward by 1 hour.
- Australian DST off: Shifts `time4` (21:00) forward by 1 hour.
- **Time Conversion** (`f_timeToMinutes`): Converts time (e.g., "14:00") to minutes (e.g., 840).
- **Current Time** (`f_currentTimeInMinutes`): Gets UTC time in minutes.
- **Background Color** (`f_getBackgroundColor`):
- Applies colors based on time ranges:
- 00:00–06:30: Orange (Asia)
- 06:30–14:00: Purple (London)
- 14:00–21:00: Blue (New York, DST-adjusted)
- 21:00–00:00: Red (Sydney, DST-adjusted)
- Outside ranges: Gray
---
#### **3. Settings**
- **Time Zones**:
- `time1` = 00:00 (Orange)
- `time2` = 06:30 (Purple)
- `time3` = 14:00 (Blue, DST-adjusted)
- `time4` = 21:00 (Red, DST-adjusted)
- **Colors**: Transparency set to 90 for visibility.
---
#### **4. Example**
- **September 5, 2025, 10:25 PM JST (13:25 UTC)**:
- U.S. DST active, Australian DST inactive.
- 13:25 UTC falls between `time2` (06:30) and `time3` (14:00) → Background is **Purple** (London session).
- **Effect**: Background color changes dynamically to reflect active sessions.
---
#### **5. Customization**
- Modify `time1`–`time4` or colors for different sessions.
- Add time zones for other markets (e.g., Tokyo).
---
#### **6. Notes**
- Uses UTC; ensure chart is set to UTC.
- DST rules are U.S./Australia-specific; verify for other regions.
A simple, visual tool for tracking market sessions.
----
### TradingView Pine Script「Market Opening Time」解説
このPine Script(`@version=5`)は、市場の取引時間帯(シドニー、ロンドン、ニューヨークなど)を背景色で視覚化するインジケーターです。米国とオーストラリアの夏時間(DST)を考慮し、時間帯を調整します。
---
#### **1. 概要**
- **目的**: UTC基準の時間帯に基づき、チャートの背景色を変更して市場セッションを強調。
- **機能**:
- 米国DST(3月第2日曜~11月第1日曜)とオーストラリアDST(10月第1日曜~4月第1日曜)を自動調整。
- 4つの時間帯(00:00、06:30、14:00、21:00)に色を割り当て。
- **用途**: FXや株式トレーダーが市場のアクティブ時間を把握。
---
#### **2. 主要ロジック**
- **DST判定**:
- `f_isUSDst`: 米国DSTを判定。
- `f_isAustraliaDst`: オーストラリアDSTを判定。
- **時間調整** (`f_getAdjustedTime`):
- 米国DST非適用時: `time3`(14:00)を1時間遅延。
- オーストラリアDST非適用時: `time4`(21:00)を1時間遅延。
- **時間変換** (`f_timeToMinutes`): 時間(例: "14:00")を分単位(840)に変換。
- **現在時刻** (`f_currentTimeInMinutes`): UTCの現在時刻を分単位で取得。
- **背景色** (`f_getBackgroundColor`):
- 時間帯に応じた色を適用:
- 00:00~06:30: オレンジ(アジア)
- 06:30~14:00: 紫(ロンドン)
- 14:00~21:00: 青(ニューヨーク、DST調整)
- 21:00~00:00: 赤(シドニー、DST調整)
- 時間外: グレー
---
#### **3. 設定**
- **時間帯**:
- `time1` = 00:00(オレンジ)
- `time2` = 06:30(紫)
- `time3` = 14:00(青、DST調整)
- `time4` = 21:00(赤、DST調整)
- **色**: 透明度90で視認性確保。
---
#### **4. 使用例**
- **2025年9月5日22:25 JST(13:25 UTC)**:
- 米国DST適用、豪DST非適用。
- 13:25は`time2`(06:30)~`time3`(14:00)の間 → 背景色は**紫**(ロンドン)。
- **効果**: 時間帯に応じて背景色が変化し、市場セッションを直感的に把握。
---
#### **5. カスタマイズ**
- 時間帯(`time1`~`time4`)や色を変更可能。
- 他の市場(例: 東京)に対応する時間帯を追加可能。
---
#### **6. 注意点**
- UTC基準のため、チャート設定をUTCに。
- DSTルールは米国・オーストラリア準拠。他地域では要確認。
シンプルで視覚的な市場時間インジケーターです。

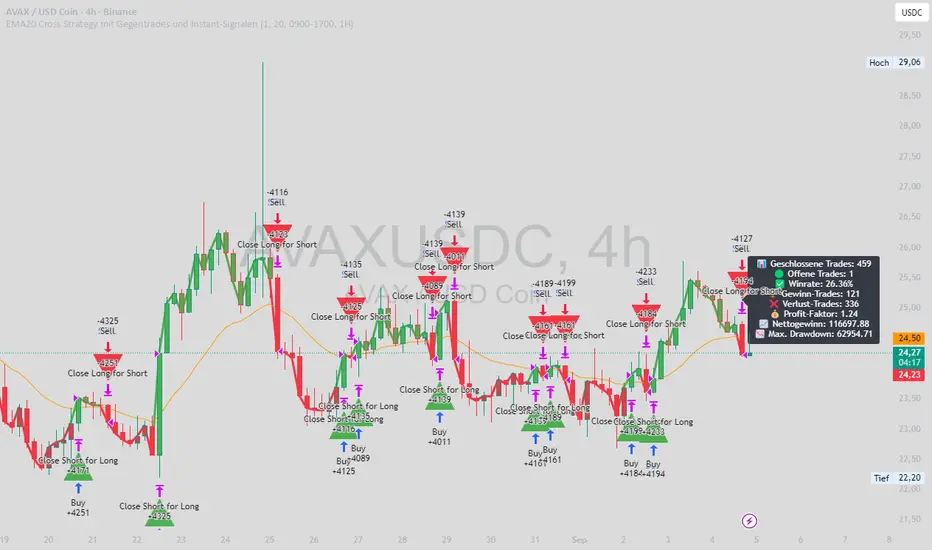
EMA20 Cross Strategy with countertrades and signalsEMA20 Cross Strategy Documentation
Overview
The EMA20 Cross Strategy with Counter-Trades and Instant Signals is a Pine Script (version 6) trading strategy designed for the TradingView platform. It implements an Exponential Moving Average (EMA) crossover system to generate buy and sell signals, with optional trend filtering, session-based trading, instant signal processing, and visual/statistical feedback. The strategy supports counter-trades (closing opposing positions before entering new ones) and operates with a fixed trade size in EUR.
Features
EMA Crossover Mechanism:
Uses a short-term EMA (configurable length, default: 1) and a long-term EMA (default: 20) to detect crossovers.
A buy signal is generated when the short EMA crosses above the long EMA.
A sell signal is generated when the short EMA crosses below the long EMA.
Instant Signals:
If enabled (useInstantSignals), signals are based on the current price crossing the short EMA, rather than waiting for the candle close.
This allows faster trade execution but may increase sensitivity to price fluctuations.
Trend Filter:
Optionally filters trades based on the trend direction (useTrendFilter).
Long trades are allowed only when the short EMA (or price, for instant signals) is above the long EMA.
Short trades are allowed only when the short EMA (or price) is below the long EMA.
Session Filter:
Restricts trading to specific market hours (sessionStart, default: 09:00–17:00) if enabled (useSessionFilter).
Ensures trades occur only during active market sessions, reducing exposure to low-liquidity periods.
Customizable Timeframe:
The EMA calculations can use a higher timeframe (e.g., 5m, 15m, 1H, 4H, 1D, default: 1H) via request.security.
This allows the strategy to base signals on longer-term trends while operating on a shorter-term chart.
Trade Management:
Fixed trade size of €100,000 per trade (tradeAmount), with a maximum quantity cap (maxQty = 10,000) to prevent oversized trades.
Counter-trades: Closes short positions before entering a long position and vice versa.
Trades are executed with a minimum quantity of 1 to ensure valid orders.
Visualization:
EMA Lines: The short EMA is colored based on the last signal (green for buy, red for sell, gray for neutral), and the long EMA is orange.
Signal Markers: Displays buy/sell signals as arrows (triangles) above/below candles if enabled (showSignalShapes).
Background/Candle Coloring: Optionally colors the chart background or candles green (bullish) or red (bearish) based on the trend (useColoredBars).
Statistics Display:
If enabled (useStats), a label on the chart shows:
Total closed trades
Open trades
Win rate (%)
Number of winning/losing trades
Profit factor (gross profit / gross loss)
Net profit
Maximum drawdown
Configuration Inputs
EMA Short Length (emaLength): Length of the short-term EMA (default: 1).
Trend EMA Length (trendLength): Length of the long-term EMA (default: 20).
Enable Trend Filter (useTrendFilter): Toggles trend-based filtering (default: true).
Color Candles (useColoredBars): Colors candles instead of the background (default: true).
Enable Session Filter (useSessionFilter): Restricts trading to specified hours (default: false).
Trading Session (sessionStart): Defines trading hours (default: 09:00–17:00).
Show Statistics (useStats): Displays performance stats on the chart (default: true).
Show Signal Arrows (showSignalShapes): Displays buy/sell signals as arrows (default: true).
Use Instant Signals (useInstantSignals): Generates signals based on live price action (default: false).
EMA Timeframe (emaTimeframe): Timeframe for EMA calculations (options: 5m, 15m, 1H, 4H, 1D; default: 1H).
Strategy Logic
Signal Generation:
Standard Mode: Signals are based on EMA crossovers (short EMA crossing long EMA) at candle close.
Instant Mode: Signals are based on the current price crossing the short EMA, enabling faster reactions.
Trade Execution:
On a buy signal, closes any short position and opens a long position.
On a sell signal, closes any long position and opens a short position.
Position size is calculated as the minimum of €100,000 or available equity, divided by the current price, capped at 10,000 units.
Filters:
Trend Filter: Ensures trades align with the trend direction (if enabled).
Session Filter: Restricts trades to user-defined market hours (if enabled).
Visual Feedback
EMA Lines: Provide a clear view of the short and long EMAs, with the short EMA’s color reflecting the latest signal.
Signal Arrows: Large green triangles (buy) below candles or red triangles (sell) above candles for easy signal identification.
Chart Coloring: Highlights bullish (green) or bearish (red) trends via background or candle colors.
Statistics Label: Displays key performance metrics in a label above the chart for quick reference.
Usage Notes
Initial Capital: €100,000 (configurable via initial_capital).
Currency: EUR (set via currency).
Order Processing: Orders are processed at candle close (process_orders_on_close=true) unless instant signals are enabled.
Dynamic Requests: Allows dynamic timeframe adjustments for EMA calculations (dynamic_requests=true).
Platform: Designed for TradingView, compatible with any market supported by the platform (e.g., stocks, forex, crypto).
Example Use Case
Scenario: Trading on a 5-minute chart with a 1-hour EMA timeframe, trend filter enabled, and session filter set to 09:00–17:00.
Behavior: The strategy will:
Calculate EMAs on the 1-hour timeframe.
Generate buy signals when the short EMA crosses above the long EMA (and price is above the long EMA).
Generate sell signals when the short EMA crosses below the long EMA (and price is below the long EMA).
Execute trades only during 09:00–17:00.
Display green/red candles and performance stats on the chart.
Limitations
Instant Signals: May lead to more frequent signals, increasing the risk of false positives in volatile markets.
Fixed Trade Size: Does not adjust dynamically based on market conditions beyond equity and max quantity limits.
Session Filter: Simplified and may not account for complex session rules or holidays.
Statistics: Displayed on-chart, which may clutter the view in smaller charts.
Customization
Adjust emaLength and trendLength to suit different market conditions (e.g., shorter for scalping, longer for swing trading).
Toggle useInstantSignals for faster or more stable signal generation.
Modify sessionStart to align with specific market hours.
Disable useStats or showSignalShapes for a cleaner chart.
This strategy is versatile for both manual and automated trading, offering flexibility for various markets and trading styles while providing clear visual and statistical feedback.
Sunset Zones by PDVDescription
Sunset Zones by PDV is an intraday reference indicator that plots key horizontal levels based on selected “root candles” throughout the trading day. At each programmed time, the indicator identifies the high and low of the corresponding candle and projects those levels forward with extended lines, providing traders with a clean visual framework of potential intraday reaction zones.
These zones serve as reference levels for support, resistance, liquidity grabs, and session context, allowing traders to analyze how price reacts around time-specific structures. Unlike lagging indicators, Sunset Zones gives traders real-time, rule-based levels tied directly to the price action of specific moments in the session.
Key Features
Predefined Time Codes
The script comes with a curated list of intraday timestamps (in HHMM format). Each represents a “root candle” from which levels are generated. Examples include 03:12, 06:47, 07:41, 08:51, etc. These time codes can reflect historically important market moments such as session opens, liquidity sweeps, or volatility inflection points.
Automatic Zone Plotting
At each root time, the script captures the candle’s high and low and instantly extends those levels forward across the chart. This provides consistent, objective reference points for intraday trading.
Extended Lines
Levels are projected far into the future (default: 500 bars) so traders can easily track how price interacts with those zones throughout the day.
Color-Coded Levels
Each root time is assigned a distinct color for fast identification. For example:
03:12 → Fuchsia
06:47 → Purple
07:41 → Teal
08:51 → White
09:53 → White
10:20 → Orange
11:10 → Green
11:49 → Red
12:05 → White
13:05 → Teal
14:09 → Aqua
This helps traders quickly recognize which time-of-day level price is interacting with.
Lightweight & Visual
The indicator focuses purely on price and time, avoiding complexity or lagging signals. It can be layered with other analysis tools, order flow charts, or session-based studies.
Practical Use Cases
Intraday Bias:
Observe whether price respects, rejects, or consolidates around these reference levels to form a bias.
Liquidity Zones:
High/low sweeps of the root candle can act as liquidity pools where institutions might trigger stops or reversals.
Support & Resistance:
Extended lines create intraday S/R zones without the need to manually draw levels.
Confluence Finder:
Combine Sunset Zones with VWAP, session ranges, Fibonacci levels, or higher-timeframe structure for layered confluence.
Important Notes
This is a visual reference tool only. It does not generate buy or sell signals.
Default times are provided, but the concept is flexible — traders can adapt it by modifying or expanding the list of time codes.
Works best on intraday timeframes where session structure is most relevant (e.g., 1-minute to 15-minute charts).
✅ In short: Sunset Zones by PDV gives intraday traders a systematic way to anchor their charts to important time-based highs and lows, creating a consistent framework for analyzing price reactions across the day.

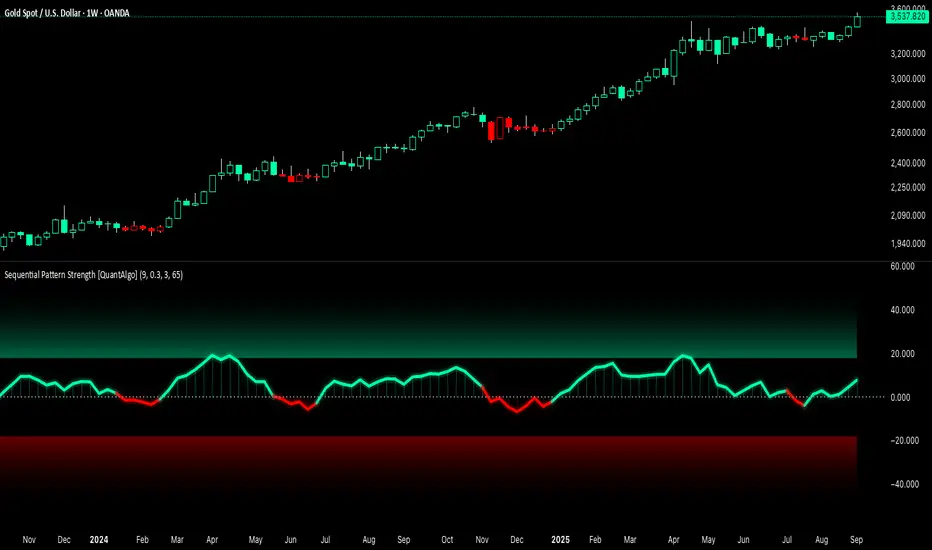
Sequential Pattern Strength [QuantAlgo]🟢 Overview
The Sequential Pattern Strength indicator measures the power and sustainability of consecutive price movements by tracking unbroken sequences of up or down closes. It incorporates sequence quality assessment, price extension analysis, and automatic exhaustion detection to help traders identify when strong trends are losing momentum and approaching potential reversal or continuation points.
🟢 How It Works
The indicator's key insight lies in its sequential pattern tracking system, where pattern strength is measured by analyzing consecutive price movements and their sustainability:
if close > close
upSequence := upSequence + 1
downSequence := 0
else if close < close
downSequence := downSequence + 1
upSequence := 0
The system calculates sequence quality by measuring how "perfect" the consecutive moves are:
perfectMoves = math.max(upSequence, downSequence)
totalMoves = math.abs(bar_index - ta.valuewhen(upSequence == 1 or downSequence == 1, bar_index, 0))
sequenceQuality = totalMoves > 0 ? perfectMoves / totalMoves : 1.0
First, it tracks price extension from the sequence starting point:
priceExtension = (close - sequenceStartPrice) / sequenceStartPrice * 100
Then, pattern exhaustion is identified when sequences become overextended:
isExhausted = math.abs(currentSequence) >= maxSequence or
math.abs(priceExtension) > resetThreshold * math.abs(currentSequence)
Finally, the pattern strength combines sequence length, quality, and price movement with momentum enhancement:
patternStrength = currentSequence * sequenceQuality * (1 + math.abs(priceExtension) / 10)
enhancedSignal = patternStrength + momentum * 10
signal = ta.ema(enhancedSignal, smooth)
This creates a sequence-based momentum indicator that combines consecutive movement analysis with pattern sustainability assessment, providing traders with both directional signals and exhaustion insights for entry/exit timing.
🟢 Signal Interpretation
Positive Values (Above Zero): Sequential pattern strength indicating bullish momentum with consecutive upward price movements and sustained buying pressure = Long/Buy opportunities
Negative Values (Below Zero): Sequential pattern strength indicating bearish momentum with consecutive downward price movements and sustained selling pressure = Short/Sell opportunities
Zero Line Crosses: Pattern transitions between bullish and bearish regimes, indicating potential trend changes or momentum shifts when sequences break
Upper Threshold Zone: Area above maximum sequence threshold (2x maxSequence) indicating extremely strong bullish patterns approaching exhaustion levels
Lower Threshold Zone: Area below negative threshold (-2x maxSequence) indicating extremely strong bearish patterns approaching exhaustion levels
POC Migration Velocity (POC-MV) [PhenLabs]📊POC Migration Velocity (POC-MV)
Version: PineScript™v6
📌Description
The POC Migration Velocity indicator revolutionizes market structure analysis by tracking the movement, speed, and acceleration of Point of Control (POC) levels in real-time. This tool combines sophisticated volume distribution estimation with velocity calculations to reveal hidden market dynamics that conventional indicators miss.
POC-MV provides traders with unprecedented insight into volume-based price movement patterns, enabling the early identification of continuation and exhaustion signals before they become apparent to the broader market. By measuring how quickly and consistently the POC migrates across price levels, traders gain early warning signals for significant market shifts and can position themselves advantageously.
The indicator employs advanced algorithms to estimate intra-bar volume distribution without requiring lower timeframe data, making it accessible across all chart timeframes while maintaining sophisticated analytical capabilities.
🚀Points of Innovation
Micro-POC calculation using advanced OHLC-based volume distribution estimation
Real-time velocity and acceleration tracking normalized by ATR for cross-market consistency
Persistence scoring system that quantifies directional consistency over multiple periods
Multi-signal detection combining continuation patterns, exhaustion signals, and gap alerts
Dynamic color-coded visualization system with intensity-based feedback
Comprehensive customization options for resolution, periods, and thresholds
🔧Core Components
POC Calculation Engine: Estimates volume distribution within each bar using configurable price bands and sophisticated weighting algorithms
Velocity Measurement System: Tracks the rate of POC movement over customizable lookback periods with ATR normalization
Acceleration Calculator: Measures the rate of change of velocity to identify momentum shifts in POC migration
Persistence Analyzer: Quantifies how consistently POC moves in the same direction using exponential weighting
Signal Detection Framework: Combines trend analysis, velocity thresholds, and persistence requirements for signal generation
Visual Rendering System: Provides dynamic color-coded lines and heat ribbons based on velocity and price-POC relationships
🔥Key Features
Real-time POC calculation with 10-100 configurable price bands for optimal precision
Velocity tracking with customizable lookback periods from 5 to 50 bars
Acceleration measurement for detecting momentum changes in POC movement
Persistence scoring to validate signal strength and filter false signals
Dynamic visual feedback with blue/orange color scheme indicating bullish/bearish conditions
Comprehensive alert system for continuation patterns, exhaustion signals, and POC gaps
Adjustable information table displaying real-time metrics and current signals
Heat ribbon visualization showing price-POC relationship intensity
Multiple threshold settings for customizing signal sensitivity
Export capability for use with separate panel indicators
🎨Visualization
POC Connecting Lines: Color-coded lines showing POC levels with intensity based on velocity magnitude
Heat Ribbon: Dynamic colored ribbon around price showing POC-price basis intensity
Signal Markers: Clear exhaustion top/bottom signals with labeled shapes
Information Table: Real-time display of POC value, velocity, acceleration, basis, persistence, and current signal status
Color Gradients: Blue gradients for bullish conditions, orange gradients for bearish conditions
📖Usage Guidelines
POC Calculation Settings
POC Resolution (Price Bands): Default 20, Range 10-100. Controls the number of price bands used to estimate volume distribution within each bar
Volume Weight Factor: Default 0.7, Range 0.1-1.0. Adjusts the influence of volume in POC calculation
POC Smoothing: Default 3, Range 1-10. EMA smoothing period applied to the calculated POC to reduce noise
Velocity Settings
Velocity Lookback Period: Default 14, Range 5-50. Number of bars used to calculate POC velocity
Acceleration Period: Default 7, Range 3-20. Period for calculating POC acceleration
Velocity Significance Threshold: Default 0.5, Range 0.1-2.0. Minimum normalized velocity for continuation signals
Persistence Settings
Persistence Lookback: Default 5, Range 3-20. Number of bars examined for persistence score calculation
Persistence Threshold: Default 0.7, Range 0.5-1.0. Minimum persistence score required for continuation signals
Visual Settings
Show POC Connecting Lines: Toggle display of colored lines connecting POC levels
Show Heat Ribbon: Toggle display of colored ribbon showing POC-price relationship
Ribbon Transparency: Default 70, Range 0-100. Controls transparency level of heat ribbon
Alert Settings
Enable Continuation Alerts: Toggle alerts for continuation pattern detection
Enable Exhaustion Alerts: Toggle alerts for exhaustion pattern detection
Enable POC Gap Alerts: Toggle alerts for significant POC gaps
Gap Threshold: Default 2.0 ATR, Range 0.5-5.0. Minimum gap size to trigger alerts
✅Best Use Cases
Identifying trend continuation opportunities when POC velocity aligns with price direction
Spotting potential reversal points through exhaustion pattern detection
Confirming breakout validity by monitoring POC gap behavior
Adding volume-based context to traditional technical analysis
Managing position sizing based on POC-price basis strength
⚠️Limitations
POC calculations are estimations based on OHLC data, not true tick-by-tick volume distribution
Effectiveness may vary in low-volume or highly volatile market conditions
Requires complementary analysis tools for complete trading decisions
Signal frequency may be lower in ranging markets compared to trending conditions
Performance optimization needed for very short timeframes below 1-minute
💡What Makes This Unique
Advanced Estimation Algorithm: Sophisticated method for calculating POC without requiring lower timeframe data
Velocity-Based Analysis: Focus on POC movement dynamics rather than static levels
Comprehensive Signal Framework: Integration of continuation, exhaustion, and gap detection in one indicator
Dynamic Visual Feedback: Intensity-based color coding that adapts to market conditions
Persistence Validation: Unique scoring system to filter signals based on directional consistency
🔬How It Works
Volume Distribution Estimation:
Divides each bar into configurable price bands for volume analysis
Applies sophisticated weighting based on OHLC relationships and proximity to close
Identifies the price level with maximum estimated volume as the POC
Velocity and Acceleration Calculation:
Measures POC rate of change over specified lookback periods
Normalizes values using ATR for consistent cross-market performance
Calculates acceleration as the rate of change of velocity
Signal Generation Process:
Combines trend direction analysis using EMA crossovers
Applies velocity and persistence thresholds to filter signals
Generates continuation, exhaustion, and gap alerts based on specific criteria
💡Note:
This indicator provides estimated POC calculations based on available OHLC data and should be used in conjunction with other analysis methods. The velocity-based approach offers unique insights into market structure dynamics but requires proper risk management and complementary analysis for optimal trading decisions.
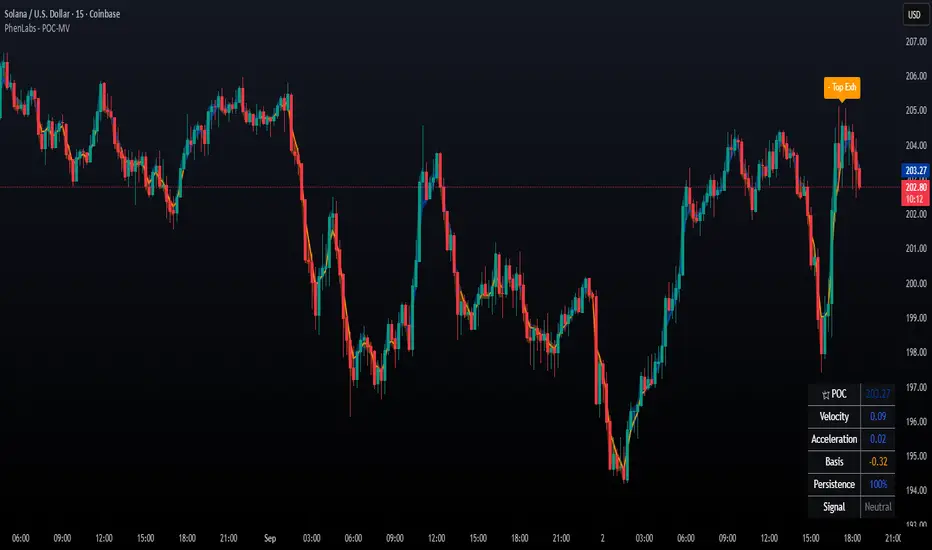
EMA/VWAP SuiteEMA/VWAP Suite
Overview
The EMA/VWAP Suite is a versatile and customizable Pine Script indicator designed for traders who want to combine Exponential Moving Averages (EMAs) and Volume Weighted Average Prices (VWAPs) in a single, powerful tool. It overlays up to eight EMAs and six VWAPs (three anchored, three rolling) on the chart, each with percentage difference labels to show how far the current price is from these key levels. This indicator is perfect for technical analysis, supporting strategies like trend following, mean reversion, and VWAP-based trading.
By default, the indicator displays eight EMAs and a session-anchored VWAP (AVWAP 1, in fuchsia) with their respective percentage difference labels, keeping the chart clean yet informative. Other VWAPs and their bands are disabled by default but can be enabled and customized as needed. The suite is designed to minimize clutter while providing maximum flexibility for traders.
Features
- Eight Customizable EMAs: Plot up to eight EMAs with user-defined lengths (default: 3, 9, 19, 38, 50, 65, 100, 200), each with a unique color for easy identification.
- EMA Percentage Difference Labels: Show the percentage difference between the current price and each EMA, displayed only for visible EMAs when enabled.
- Three Anchored VWAPs: Plot VWAPs anchored to the start of a session, week, or month, with customizable source, offset, and band multipliers. AVWAP 1 (session-anchored, fuchsia) is enabled by default.
- Three Rolling VWAPs: Plot VWAPs calculated over fixed periods (default: 20, 50, 100), with customizable source, offset, and band multipliers.
- VWAP Bands: Optional upper and lower bands for each VWAP, based on standard deviation with user-defined multipliers.
- VWAP Percentage Difference Labels: Display the percentage difference between the current price and each VWAP, shown only for visible VWAPs. Enabled by default to show the AVWAP 1 label.
- Customizable Colors: Each VWAP has a user-defined color via input settings, with labels matching the VWAP line colors (e.g., AVWAP 1 defaults to fuchsia).
Flexible Display Options: Toggle individual EMAs, VWAPs, bands, and labels on or off to reduce chart clutter.
Settings
The indicator is organized into intuitive setting groups:
EMA Settings
Show EMA 1–8 : Toggle each EMA on or off (default: all enabled).
EMA 1–8 Length : Set the period for each EMA (default: 3, 9, 19, 38, 50, 65, 100, 200).
Show EMA % Difference Labels : Enable/disable percentage difference labels for all EMAs (default: enabled).
EMA Label Font Size (8–20) : Adjust the font size for EMA labels (default: 10, mapped to “tiny”).
Anchored VWAP 1–3 Settings
Show AVWAP 1–3 : Toggle each anchored VWAP on or off (default: AVWAP 1 enabled, others disabled).
AVWAP 1–3 Color : Set the color for each VWAP line and its label (default: fuchsia for AVWAP 1, purple for AVWAP 2, teal for AVWAP 3).
AVWAP 1–3 Anchor : Choose the anchor period (“Session,” “Week,” “Month”; default: Session for AVWAP 1, Week for AVWAP 2, Month for AVWAP 3).
AVWAP 1–3 Source : Select the price source (default: hlc3).
AVWAP 1–3 Offset : Set the horizontal offset for the VWAP line (default: 0).
Show AVWAP 1–3 Bands : Toggle upper/lower bands (default: disabled).
AVWAP 1–3 Band Multiplier : Adjust the standard deviation multiplier for bands (default: 1.0).
Rolling VWAP 1–3 Settings
Show RVWAP 1–3 : Toggle each rolling VWAP on or off (default: disabled).
RVWAP 1–3 Color : Set the color for each VWAP line and its label (default: navy for RVWAP 1, maroon for RVWAP 2, fuchsia for RVWAP 3).
RVWAP 1–3 Period Length : Set the period for the rolling VWAP (default: 20, 50, 100).
RVWAP 1–3 Source : Select the price source (default: hlc3).
RVWAP 1–3 Offset : Set the horizontal offset (default: 0).
Show RVWAP 1–3 Bands : Toggle upper/lower bands (default: disabled).
RVWAP 1–3 Band Multiplier : Adjust the standard deviation multiplier for bands (default: 1.0).
VWAP Label Settings
Show VWAP % Difference Labels : Enable/disable percentage difference labels for all VWAPs (default: enabled, showing AVWAP 1 label).
VWAP Label Font Size (8–20) : Adjust the font size for VWAP labels (default: 10, mapped to “tiny”).
How It Works
EMAs : Calculated using ta.ema(close, length) for each user-defined period. Percentage differences are computed as ((close - ema) / close) * 100 and displayed as labels for visible EMAs when show_ema_labels is enabled.
Anchored VWAPs : Calculated using ta.vwap(source, anchor, 1), where the anchor is determined by the selected timeframe (Session, Week, or Month). Bands are computed using the standard deviation from ta.vwap.
Rolling VWAPs : Calculated using ta.vwap(source, length), with bands based on ta.stdev(source, length).
Labels : Updated on each new bar (ta.barssince(ta.change(time) != 0) == 0) to show percentage differences. Labels are only displayed for visible EMAs/VWAPs to avoid clutter.
Color Matching: VWAP labels use the same color as their corresponding VWAP lines, set via input settings (e.g., avwap1_color for AVWAP 1).
Example Use Cases
- Trend Following: Use longer EMAs (e.g., 100, 200) to identify trends and shorter EMAs (e.g., 3, 9) for entry/exit signals.
- Mean Reversion: Monitor percentage difference labels to spot overbought/oversold conditions relative to EMAs or VWAPs.
- VWAP Trading: Use the default session-anchored AVWAP 1 for intraday trading, adding weekly/monthly VWAPs or rolling VWAPs for broader context.
- Intraday Analysis: Leverage the session-anchored AVWAP 1 (enabled by default) for day trading, with bands as support/resistance zones.
Wick Pressure Zones [BigBeluga]
The Wick Pressure Zones indicator highlights areas where extreme wick activity occurred, signaling strong buy or sell pressure. By measuring unusually long upper or lower wicks and mapping them into gradient volume zones , the tool helps traders identify levels where liquidity was absorbed, leaving behind footprints of supply and demand imbalances. These zones often act as support, resistance, or liquidity sweep magnets .
🔵 CONCEPTS
Extreme Wicks : Large upper or lower shadows indicate aggressive rejection — upper wicks suggest selling pressure, lower wicks suggest buying pressure.
Volumatic Gradient Zones : From each detected wick, the indicator projects a layered gradient zone, proportional to the wick’s size, showing where most pressure occurred.
Liquidity Footprints : These zones mark levels where significant buy/sell volume was executed, often becoming reaction points on future retests.
Automatic Expiration : Zones persist until price decisively trades through them, after which they are cleared to keep the chart clean.
🔵 FEATURES
Automatic Wick Detection : Identifies extreme upper and lower wick events using percentile filtering and Realative Strength Index.
Gradient Zone Visualization : Builds a 10-layer zone from the wick top/bottom, shading intensity according to pressure strength.
Volume Labels : Each zone is annotated with the bar’s volume at the origin point for added context.
Dynamic Zone Extension : Zones extend to the right as long as they remain relevant; once price closes through them, they are removed.
Support & Resistance Mapping : Upper wick zones (red) behave like supply/resistance, lower wick zones (green) like demand/support.
Clutter Control : Limits the number of active zones (default 10) to keep charts responsive.
Background Highlighting : Optional background shading when new wick zones appear (red for sell, green for buy).
🔵 HOW TO USE
Look for Upper Wick Zones (red) : Indicate strong selling pressure; watch for resistance, reversals, or liquidity sweeps above.
Look for Lower Wick Zones (green) : Indicate strong buying pressure; watch for support or liquidity sweeps below.
Trade Retests : When price returns to a zone, expect a reaction (bounce or rejection) due to leftover liquidity.
Combine with Context : Align wick pressure zones with HTF support/resistance, order blocks, or volume profile for stronger signals.
Use Volume Labels : High-volume wicks indicate more significant liquidity events, making the zone more likely to act as a strong reaction point.
🔵 CONCLUSION
The Wick Pressure Zones is a powerful way to visualize hidden liquidity and aggressive rejections. By mapping extreme wick events into dynamic, volume-annotated zones, it shows traders where the market absorbed heavy buy/sell pressure. These levels frequently act as magnets or turning points, making them valuable for timing entries, stop placement, or fade strategies.

ZLEMA Trend Index 2.0ZTI — ZLEMA Trend Index 2.0 (0–1000)
Overview
Price Mapped ZTI v2.0 - Enhanced Zero-Lag Trend Index.
This indicator is a significant upgrade to the original ZTI v1.0, featuring enhanced resolution from 0-100 to 0-1000 levels for dramatically improved price action accuracy. The Price Mapped ZTI uses direct price-to-level mapping to eliminate statistical noise and provide true proportional representation of market movements.
Key Innovation: Instead of statistical normalization, this version maps current price position within a user-defined lookback period directly to the ZTI scale, ensuring perfect correlation with actual price movements. I believe this is the best way to capture trends instead of directly on the charts using a plethora of indicators which introduces bad signals resulting in drawdowns. The RSI-like ZTI overbought and oversold lines filter valid trends by slicing through the current trading zone. Unlike RSI that can introduce false signals, the ZTI levels 1 to 1000 is faithfully mapped to the lowest to highest price in the current trading zone (lookback period in days) which can be changed in the settings. The ZTI line will never go off the beyond the ZTI levels in case of extreme trend continuation as the trading zone is constantly updated to reflect only the most recent bars based on lookback days.
Core Features
✅ 10x Higher Resolution - 0-1000 scale provides granular movement detection
✅ Adjustable Trading Zone - Customizable lookback period from 1-50 days
✅ Price-Proportional Mapping - Direct correlation between price position and ZTI level
✅ Zero Statistical Lag - No rolling averages or standard deviation calculations
✅ Multi-Strategy Adaptability - Single parameter adjustment for different trading styles
Trading Zone Optimization
📊 Lookback Period Strategies
Short-term (1-3 days):
Ultra-responsive to recent price action
Perfect for scalping and day trading
Tight range produces more sensitive signals
Medium-term (7-14 days):
Balanced view of recent trading range
Ideal for swing trading
Captures meaningful support/resistance levels
Long-term (21-30 days):
Broader market context
Excellent for position trading
Smooths out short-term market noise
⚡ Market Condition Adaptation
Volatile Markets: Use shorter lookback (3-5 days) for tighter ranges
Trending Markets: Use longer lookback (14-21 days) for broader context
Ranging Markets: Use medium lookback (7-10 days) for clear boundaries
🎯 Timeframe Optimization
1-minute charts: 1-2 day lookback
5-minute charts: 2-5 day lookback
Hourly charts: 7-14 day lookback
Daily charts: 21-50 day lookback
Trading Applications
Scalping Setup (2-day lookback):
Super tight range for quick reversals
ZTI 800+ = immediate short opportunity
ZTI 200- = immediate long opportunity
Swing Trading Setup (10-day lookback):
Meaningful swing levels captured
ZTI extremes = high-probability reversal zones
More stable signals, reduced whipsaws
Advanced Usage
🔧 Real-Time Adaptability
Trending days: Increase to 14+ days for broader perspective
Range-bound days: Decrease to 3 days for tighter signals
High volatility: Shorter lookback for responsiveness
Low volatility: Longer lookback to avoid false signals
💡 Multi-Timeframe Approach
Entry signals: Use 7-day ZTI on main timeframe
Trend confirmation: Use 21-day ZTI on higher timeframe
Exit timing: Use 3-day ZTI for precise exits
🌐 Session Optimization
Asian session: Shorter lookback (3-5 days) for range-bound conditions
London/NY session: Longer lookback (7-14 days) for trending conditions
How It Works
The indicator maps the current price position within the specified lookback period directly to a 0-1000 scale and plots it using ZLEMA (Zero Lag Exponential Moving Average) which has the least lag of the available popular moving averages:
Price at recent high = ZTI at 1000
Price at recent low = ZTI at 1
Price at mid-range = ZTI at 500
This creates perfect proportional representation where every price movement translates directly to corresponding ZTI movement, eliminating the false signals common in traditional oscillators.
This single, versatile indicator adapts to any market condition, timeframe, or trading style through one simple parameter adjustment, making it an essential tool for traders at every level.
Credits
ZLEMA techniques widely attributed to John Ehlers.
Disclaimer
This tool is for educational purposes only and is not financial advice. Backtest and forward‑test before live use, and always manage risk.
Please note that I set this as closed source to prevent source code cloning by others, repackaging and republishing which results in multiple confusing choices of the same indicator.
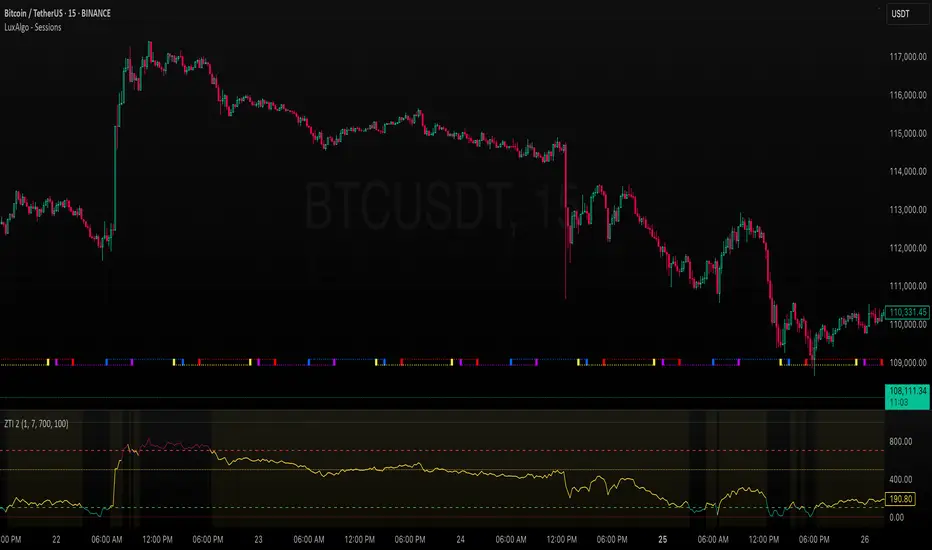
Volume Heat ZoneVolume Zones Indicator
This Pine Script creates a volume-based zone analysis tool for TradingView.
Function:
Divides the price range (high to low) into 20 levels over a 100-candle lookback period
Measures volume activity at each price level
Draws boxes at levels with above-average volume (1.5x threshold)
Key Settings:
Lookback Period (100): Number of candles analyzed
Price Levels (20): Price range subdivisions
Volume Threshold (1.5): Minimum volume multiplier for zones
Candle Offset (1): Excludes current candle from analysis
Projection Bars (10): Extends boxes 10 bars into the future
How it works:
The indicator identifies price levels where significant trading volume occurred historically, highlighting potential support/resistance zones. Boxes are redrawn on each confirmed candle, showing dynamic volume concentration areas that traders can use for entry/exit decisions.

Staggered Exponential PullbacksIndicator Description: Staggered Exponential Pullbacks (Final)
Core Concept
This indicator is designed to dynamically track and visualize price pullbacks from a recent high. It serves as an intelligent alert system and a tool for visualizing potential support levels that follow a predefined, non-linear logic.
Instead of a fixed percentage interval, the indicator calculates the levels based on a fixed, exponentially increasing sequence of percentages. The distance between the levels increases as the price falls further. This models a strategy where larger price movements are tolerated as a pullback deepens before the next signal level is reached. The basis for this calculation is always the highest close of the last x candles.
Key Features
This indicator goes far beyond a simple calculation, offering a range of intelligent features for professional use:
Cascading, Fixed Levels: The levels are based on a fixed sequence of percentage distances (3.0%, 3.6%, 4.3%, etc.), where each new level is calculated from the previous level.
Persistent Support Levels ("Floors"): Once an alert level is breached, it transforms into a fixed support line ("floor"). This line will never move down, even if the market high subsequently drops.
Automatic Upward Adjustment: Established floors are automatically pulled upwards when the market shows new strength and makes higher highs. A once-reached -3% floor will therefore rise with the market.
Intelligent, Self-Cleaning Reset Logic: The indicator recognizes when a pullback sequence has ended and a new one has begun. "Ghost lines" from old, irrelevant price movements are automatically removed from the chart to ensure maximum clarity.
Cascade-Proof Alerts: Even during extremely fast sell-offs that break through multiple levels in a single candle, the indicator correctly captures every single level breach.
Customizable Visualization: All key parameters, such as the lookback period and the colors of the lines, can be easily adjusted in the settings.
Visual Elements on the Chart
The Orange Line (Highest Close): This is the reference line. It always shows the highest closing price within the defined lookback period and has a step-line shape.
The 'Floor' Lines (Default: Yellow): These are solid lines that indicate which percentage levels have already been breached in the current sequence. They function as established support levels.
The 'Next Due' Line (Default: Purple): This is a step-line that displays the next expected alert level. It moves dynamically with the calculation. As soon as the price crosses this line, an alert is triggered, and it transforms into a yellow "Floor" line.
Settings (Inputs)
Number of Candles (Lookback): Defines how many past candles are used to determine the highest closing price.
Displayed Alert Levels (Max 10): Determines the maximum number of levels the indicator will calculate and display.
Color of Floors: Allows you to freely choose the color for the solid, established support lines.
Color of Next Due Line: Allows you to freely choose the color for the next, untriggered alert line.
Setting Up Alerts (Important!)
Since the indicator uses dynamic alert messages, the alert must be set up as follows:
Add the indicator to the chart.
Click the clock icon ("Alert") in the top toolbar.
In the "Condition" field, select the name of this indicator: Staggered Exponential Pullbacks.
In the second dropdown menu, you must select the option "Any alert() function call".
Message: The message box can be left empty. The indicator automatically generates a detailed message (e.g., "Price Alert: Level 2 (3.6%) reached!").
Click "Create".
You only need one single alert to cover all 10 levels.
Important Disclaimer: Not Financial Advice
This indicator is purely a technical analysis tool for visualizing price movements. The displayed lines and triggered alerts do not constitute buy or sell recommendations and are not a form of financial or investment advice. They serve for informational and analytical purposes only.
Trading decisions based on the information from this indicator are made solely at your own risk and responsibility. The author and developer of this script assume no liability for any trading losses. Always conduct your own comprehensive analysis and, if necessary, consult a qualified financial advisor before making any trading decisions.
Apex Edge - London Open Session# Apex Edge - London Open Session Trading System
## Overview
The London Open Session indicator captures institutional price action during the first hour of the London forex session (8:00-9:00 AM GMT) and identifies high-probability breakout and retest opportunities. This system tracks the session's high/low range and generates precise entry signals when price breaks or retests these key institutional levels.
## Core Strategy
**Session Tracking**: Automatically identifies and marks the London Open session boundaries, creating a trading zone from the first hour's price range.
**Dual Entry Logic**:
- **Breakout Entries**: Triggers when price closes beyond the session high/low and continues in that direction
- **Retest Entries**: Activates when price returns to test the broken level as new support/resistance
**Performance Analytics**: Built-in win rate tracking displays real-time performance statistics over user-defined lookback periods, enabling data-driven optimization for each currency pair.
## Key Features
### Automated Zone Detection
- Precise London session timing with timezone offset controls
- Visual session boundaries with customizable colours
- Automatic high/low range calculation and display
### Smart Entry System
- Breakout confirmation requiring candle close beyond zone
- Retest detection with configurable pip distance tolerance
- Separate risk/reward ratios for breakout vs retest entries
- Visual entry arrows with clear trade direction labels
### Performance HUD
- Real-time win rate calculation over customizable periods (7-365 days)
- Total trades tracking with win/loss breakdown
- Average risk-reward ratio display
- Color-coded performance metrics (green >70%, yellow >50%, red <50%)
### PineConnector Integration
- Direct MT4/MT5 execution via PineConnector alerts
- Proper forex pip calculations for all currency pairs
- Customizable risk percentage per trade
- Symbol override capability for broker compatibility
- Automatic SL/TP level calculation in pips
## Critical Usage Requirements
### Pair-Specific Optimization
Each currency pair requires individual optimization due to varying volatility characteristics, institutional participation levels, and typical price ranges during London hours. The performance HUD is essential for identifying optimal settings before live trading.
**Recommended Testing Process**:
1. Apply indicator to desired currency pair and timeframe
2. Experiment with session timing - while 8:00-9:00 AM GMT is standard, some pairs may show improved performance with alternative hourly windows (e.g., 7:00-8:00 AM or 9:00-10:00 AM)
3. Adjust Stop Loss distances, Risk/Reward ratios, and Retest distances
4. Monitor win rate over 30+ day periods using the performance HUD
5. Only proceed with live alerts once consistent 60%+ win rates are achieved
6. Create separate optimized chart setups for each profitable pair/timeframe combination
### Timeframe Specifications
This indicator is specifically designed and tested for:
- **1-minute charts**: Optimal for capturing immediate institutional reactions
- **5-minute charts**: Balanced approach between noise reduction and opportunity frequency
Higher timeframes generally produce inferior results due to increased noise and reduced institutional edge during the London session window.
## Settings Configuration
### Session Timing
- **London Open/Close Hours**: Adjust for your chart's timezone
- **Rectangle End Time**: Set to 4:30 PM to stop signals before NY session close
- **Timezone Offset**: Ensure accurate London session capture
### Entry Parameters
- **Retest Distance**: 3-8 pips depending on pair volatility
- **Stop Loss Pips**: Separate settings for breakouts (10-15 pips) and retests (8-12 pips)
- **Risk/Reward Ratios**: Independent ratios for different entry types
### PineConnector Setup
- **License ID**: Your PineConnector license key
- **Symbol Override**: MT4/MT5 symbol names if different from TradingView
- **Risk Percentage**: Position size as percentage of account balance
- **Prefix/Comment**: Organize trades in terminal
## Manual Trading Limitations
Without PineConnector automation, traders face significant practical challenges:
**Settings Management**: Each currency pair requires different optimized parameters. Switching between charts means manually adjusting multiple settings each time, creating potential for errors and missed opportunities.
**Timing Sensitivity**: London Open signals can occur rapidly during high-volatility periods. Manual execution may result in slippage or missed entries.
**Multi-Pair Monitoring**: Tracking 4-11 currency pairs simultaneously while manually adjusting settings for each switch becomes impractical for most traders.
**Parameter Consistency**: Risk of using suboptimal settings when quickly switching between pairs, potentially compromising the careful optimization work.
## Recommended Workflow
1. **Historical Testing**: Use win rate HUD to identify profitable pairs and optimal parameters
2. **Demo Automation**: Test PineConnector alerts on demo accounts with optimized settings
3. **Live Implementation**: Deploy alerts only on proven profitable pair/timeframe combinations
4. **Ongoing Monitoring**: Regular review of performance metrics to maintain edge
## Risk Disclaimer
This indicator provides analysis tools and automation capabilities but does not guarantee profitable trading outcomes. Past performance does not predict future results. Users should thoroughly backtest and demo trade before risking live capital. The London session strategy works best during specific market conditions and may underperform during low volatility or unusual market environments.
## Support Requirements
Successful implementation requires:
- Basic understanding of London session market dynamics
- PineConnector subscription for automation features
- Patience for proper optimization process
- Realistic expectations about win rates and drawdown periods
This system is designed for serious traders willing to invest time in proper optimization and risk management rather than plug-and-play solutions.
Weekly pecentage tracker by PRIVATE
Settings Picture below this link: 👇
i.ibb.co
What it is
A lightweight “Weekly % Tracker” overlay that lets you manually enter weekly performance (in percent) for XAUUSD + up to 10 FX pairs, then shows:
a small table panel with each enabled symbol and its % result
one TOTAL row (Sum / Average / Compounded across all enabled symbols)
an optional mini badge showing the % for a single selected symbol
Nothing is auto-calculated from price—you type the % yourself.
Key settings
Panel: show/hide, position, number of decimals, colors (background, text, green/red).
Total mode:
Sum – adds percentages
Average – mean of enabled rows
Compounded –
(
∏
(
1
+
𝑝
/
100
)
−
1
)
×
100
(∏(1+p/100)−1)×100
Symbols:
XAUUSD (toggle + label + % input)
10 FX pairs (each has On/Off, label text, % input). You can rename labels to any symbol text you want.
Mini badge: show/hide, position, and symbol to display.
How it works
Overlay indicator: overlay=true; just draws UI on the chart (no plots).
Arrays (syms, vals, ons) collect the row data in order: XAU first, then FX1…FX10.
Helpers:
posFrom() converts a position string (e.g., “Top Right”) into a position.* constant.
wp_col() picks green/red/neutral based on the sign of the %.
wp_round() rounds values to the selected decimals.
calc_total() computes the TOTAL with the chosen mode over enabled rows only.
Table creation logic:
Counts how many rows are enabled.
If none enabled or panel is off: the panel table is deleted, so no box/background is visible.
If enabled and on: the panel is (re)created at the chosen position.
On each last bar (barstate.islast), it clears the table to transparent (bgcolor=na) and then fills one row per enabled symbol, followed by a single TOTAL row.
Mini badge:
Always (re)created on position change.
Shows selected symbol’s % (or “-” if that symbol isn’t enabled or has no value).
Colors text green/red by sign.
Notes & limits
It’s manual input—the script doesn’t read trades or P/L from price.
You can rename each row’s label to match any symbol name you want.
When no rows are enabled, the panel disappears entirely (no empty background).
Designed to be light: only draws tables; no heavy plotting.
If you want the TOTAL row to be optional, or different color thresholds, or CSV-style export/import of the values, say the word and I’ll add it.

AltCoin & MemeCoin Index Correlation [Eddie_Bitcoin]🧠 Philosophy of the Strategy
The AltCoin & MemeCoin Index Correlation Strategy by Eddie_Bitcoin is a carefully engineered trend-following system built specifically for the highly volatile and sentiment-driven world of altcoins and memecoins.
This strategy recognizes that crypto markets—especially niche sectors like memecoins—are not only influenced by individual price action but also by the relative strength or weakness of their broader sector. Hence, it attempts to improve the reliability of trading signals by requiring alignment between a specific coin’s trend and its sector-wide index trend.
Rather than treating each crypto asset in isolation, this strategy dynamically incorporates real-time dominance metrics from custom indices (OTHERS.D and MEME.D) and combines them with local price action through dual exponential moving average (EMA) crossovers. Only when both the asset and its sector are moving in the same direction does it allow for trade entries—making it a confluence-based system rather than a single-signal strategy.
It supports risk-aware capital allocation, partial exits, configurable stop loss and take profit levels, and a scalable equity-compounding model.
✅ Why did I choose OTHERS.D and MEME.D as reference indices?
I selected OTHERS.D and MEME.D because they offer a sector-focused view of crypto market dynamics, especially relevant when trading altcoins and memecoins.
🔹 OTHERS.D tracks the market dominance of all cryptocurrencies outside the top 10 by market cap.
This excludes not only BTC and ETH, but also major stablecoins like USDT and USDC, making it a cleaner indicator of risk appetite across true altcoins.
🔹 This is particularly useful for detecting "Altcoin Season"—periods where capital rotates away from Bitcoin and flows into smaller-cap coins.
A rising OTHERS.D often signals the start of broader altcoin rallies.
🔹 MEME.D, on the other hand, captures the speculative behavior of memecoin segments, which are often driven by retail hype and social media activity.
It's perfect for timing momentum shifts in high-risk, high-reward tokens.
By using these indices, the strategy aligns entries with broader sector trends, filtering out noise and increasing the probability of catching true directional moves, especially in phases of capital rotation and altcoin risk-on behavior.
📐 How It Works — Core Logic and Execution Model
At its heart, this strategy employs dual EMA crossover detection—one pair for the asset being traded and one pair for the selected market index.
A trade is only executed when both EMA crossovers agree on the direction. For example:
Long Entry: Coin's fast EMA > slow EMA and Index's fast EMA > slow EMA
Short Entry: Coin's fast EMA < slow EMA and Index's fast EMA < slow EMA
You can disable the index filter and trade solely based on the asset’s trend just to make a comparison and see if improves a classic EMA crossover strategy.
Additionally, the strategy includes:
- Adaptive position sizing, based on fixed capital or current equity (compound mode)
- Take Profit and Stop Loss in percentage terms
- Smart partial exits when trend momentum fades
- Date filtering for precise backtesting over specific timeframes
- Real-time performance stats, equity tracking, and visual cues on chart
⚙️ Parameters & Customization
🔁 EMA Settings
Each EMA pair is customizable:
Coin Fast EMA: Default = 47
Coin Slow EMA: Default = 50
Index Fast EMA: Default = 47
Index Slow EMA: Default = 50
These control the sensitivity of the trend detection. A wider spread gives smoother, slower entries; a narrower spread makes it more responsive.
🧭 Index Reference
The correlation mechanism uses CryptoCap sector dominance indexes:
OTHERS.D: Dominance of all coins EXCLUDING Top 10 ones
MEME.D: Dominance of all Meme coins
These are dynamically calculated using:
OTHERS_D = OTHERS_cap / TOTAL_cap * 100
MEME_D = MEME_cap / TOTAL_cap * 100
You can select:
Reference Index: OTHERS.D or MEME.D
Or disable the index reference completely (Don't Use Index Reference)
💰 Position Sizing & Risk Management
Two capital allocation models are supported:
- Fixed % of initial capital (default)
- Compound profits, which scales positions as equity grows
Settings:
- Compound profits?: true/false
- % of equity: Between 1% and 200% (default = 10%)
This is critical for users who want to balance growth with risk.
🎯 Take Profit / Stop Loss
Customizable thresholds determine automatic exits:
- TakeProfit: Default = 99999 (disabled)
- StopLoss: Default = 5 (%)
These exits are percentage-based and operate off the entry price vs. current close.
📉 Trend Weakening Exit (Scale Out)
If the position is in profit but the trend weakens (e.g., EMA color signals trend loss), the strategy can partially close a configurable portion of the position:
- Scale Position on Weak Trend?: true/false
- Scaled Percentage: % to close (default = 65%)
This feature is useful for preserving profits without exiting completely.
📆 Date Filter
Useful for segmenting performance over specific timeframes (e.g., bull vs bear markets):
- Filter Date Range of Backtest: ON/OFF
- Start Date and End Date: Custom time range
OTHER PARAMETERS EXPLANATION (Strategy "Properties" Tab):
- Initial Capital is set to 100 USD
- Commission is set to 0.055% (The ones I have on Bybit)
- Slippage is set to 3 ticks
- Margin (short and long) are set to 0.001% to avoid "overspending" your initial capital allocation
📊 Visual Feedback and Debug Tools
📈 EMA Trend Visualization
The slow EMA line is dynamically color-coded to visually display the alignment between the asset trend and the index trend:
Lime: Coin and index both bullish
Teal: Only coin bullish
Maroon: Only index bullish
Red: Both bearish
This allows for immediate visual confirmation of current trend strength.
💬 Real-Time PnL Labels
When a trade closes, a label shows:
Previous trade return in % (first value is the effective PL)
Green background for profit, Red for losses.
📑 Summary Table Overlay
This table appears in a corner of the chart (user-defined) and shows live performance data including:
Trade direction (yellow long, purple short)
Emojis: 💚 for current profit, 😡 for current loss
Total number of trades
Win rate
Max drawdown
Duration in days
Current trade profit/loss (absolute and %)
Cumulative PnL (absolute and %)
APR (Annualized Percentage Return)
Each metric is color-coded:
Green for strong results
Yellow/orange for average
Red/maroon for poor performance
You can select where this appears:
Top Left
Top Right
Bottom Left
Bottom Right (default)
📚 Interpretation of Key Metrics
Equity Multiplier: How many times initial capital has grown (e.g., “1.75x”)
Net Profit: Total gains including open positions
Max Drawdown: Largest peak-to-valley drop in strategy equity
APR: Annualized return calculated based on equity growth and days elapsed
Win Rate: % of profitable trades
PnL %: Percentage profit on the most recent trade
🧠 Advanced Logic & Safety Features
🛑 “Don’t Re-Enter” Filter
If a trade is closed due to StopLoss without a confirmed reversal, the strategy avoids re-entering in that same direction until conditions improve. This prevents false reversals and repetitive losses in sideways markets.
🧷 Equity Protection
No new trades are initiated if equity falls below initial_capital / 30. This avoids overleveraging or continuing to trade when capital preservation is critical.
Keep in mind that past results in no way guarantee future performance.
Eddie Bitcoin

BPS Multi-MA 5 — 22/30, SMA/WMA/EMA# Multi-MA 5 — 22/30 base, SMA/WMA/EMA
**What it is**
A lightweight 5-line moving-average ribbon for fast visual bias and trend/mean-reversion reads. You can switch the MA type (SMA/WMA/EMA) and choose between two ways of setting lengths: by monthly “session-based” base (22 or 30) with multipliers, or by entering exact lengths manually. An optional info table shows the effective settings in real time.
---
## How it works
* Calculates five moving averages from the selected price source.
* Lengths are either:
* **Multipliers mode:** `Base × Multiplier` (e.g., base 22 → 22/44/66/88/110), or
* **Manual mode:** any five exact lengths (e.g., 10/22/50/100/200).
* Plots five lines with fixed legend titles (MA1…MA5); the **info table** displays the actual type and lengths.
---
## Inputs
**Length Mode**
* **Multipliers** — choose a **Base** of **22** (≈ trading sessions per month) or **30** (calendar-style, smoother) and set **×1…×5** multipliers.
* **Manual** — enter **Len1…Len5** directly.
**MA Settings**
* **MA Type:** SMA / WMA / EMA
* **Source:** any series (e.g., `close`, `hlc3`, etc.)
* **Use true close (ignore Heikin Ashi):** when enabled, the MA is computed from the underlying instrument’s real `close`, not HA candles.
* **Show info table:** toggles the on-chart table with the current mode, type, base, and lengths.
---
## Quick start
1. Add the indicator to your chart.
2. Pick **MA Type** (e.g., **WMA** for faster response, **SMA** for smoother).
3. Choose **Length Mode**:
* **Multipliers:** set **Base = 22** for session-based monthly lengths (stocks/FX), or **30** for heavier smoothing.
* **Manual:** enter your exact lengths (e.g., 10/22/50/100/200).
4. (Optional) On **Heikin Ashi** charts, enable **Use true close** if you want the lines based on the instrument’s real close.
---
## Tips & notes
* **1 month ≈ 21–22 sessions.** Using 30 as “monthly” yields a smoother, more delayed curve.
* **WMA** reacts faster than **SMA** at the same length; expect earlier signals but more whipsaws in chop.
* **Len = 1** makes the MA track the chosen source (e.g., `close`) almost exactly.
* If changing lengths doesn’t move the lines, ensure you’re editing fields for the **active Length Mode** (Multipliers vs Manual).
* For clean comparisons, use the **same timeframe**. If you later wrap this in MTF logic, keep `lookahead_off` and handle gaps appropriately.
---
## Use cases
* Trend ribbon and dynamic bias zones
* Pullback entries to the mid/slow lines
* Crossovers (fast vs slow) for confirmation
* Volatility filtering by spreading lengths (e.g., 22/44/88/132/176)
---
**Credits:** Built for clarity and speed; designed around session-based “monthly” lengths (22) or smoother calendar-style (30).

ICT Macro Time Window NYThis script highlights the typical ICT “macro” algorithm activity windows on your chart. It marks 10 minutes before to 10 minutes after each full hour, based on New York time (NY). The display is restricted to the 00:00 – 16:00 NY time range.
Overlay on chart with semi-transparent background
Automatically adjusts to the chart timeframe
Customizable: window start/end minutes, hours, and background color
Ideal for traders following ICT concepts to visually identify high-probability algorithm activity periods.

Advanced Trend Momentum [Alpha Extract]The Advanced Trend Momentum indicator provides traders with deep insights into market dynamics by combining exponential moving average analysis with RSI momentum assessment and dynamic support/resistance detection. This sophisticated multi-dimensional tool helps identify trend changes, momentum divergences, and key structural levels, offering actionable buy and sell signals based on trend strength and momentum convergence.
🔶 CALCULATION
The indicator processes market data through multiple analytical methods:
Dual EMA Analysis: Calculates fast and slow exponential moving averages with dynamic trend direction assessment and ATR-normalized strength measurement.
RSI Momentum Engine: Implements RSI-based momentum analysis with enhanced overbought/oversold detection and momentum velocity calculations.
Pivot-Based Structure: Identifies and tracks dynamic support and resistance levels using pivot point analysis with configurable level management.
Signal Integration: Combines trend direction, momentum characteristics, and structural proximity to generate high-probability trading signals.
Formula:
Fast EMA = EMA(Close, Fast Length)
Slow EMA = EMA(Close, Slow Length)
Trend Direction = Fast EMA > Slow EMA ? 1 : -1
Trend Strength = |Fast EMA - Slow EMA| / ATR(Period) × 100
RSI Momentum = RSI(Close, RSI Length)
Momentum Value = Change(Close, 5) / ATR(10) × 100
Pivot Support/Resistance = Dynamic pivot arrays with configurable lookback periods
Bullish Signal = Trend Change + Momentum Confirmation + Strength > 1%
Bearish Signal = Trend Change + Momentum Confirmation + Strength > 1%
🔶 DETAILS
Visual Features:
Trend EMAs: Fast and slow exponential moving averages with dynamic color coding (bullish/bearish)
Enhanced RSI: RSI oscillator with color-coded zones, gradient fills, and reference bands at overbought/oversold levels
Trend Fill: Dynamic gradient between EMAs indicating trend strength and direction
Support/Resistance Lines: Horizontal levels extending from pivot-based calculations with configurable maximum levels
Momentum Candles: Color-coded candlestick overlay reflecting combined trend and momentum conditions
Divergence Markers: Diamond-shaped signals highlighting bullish and bearish momentum divergences
Analysis Table: Real-time summary of trend direction, strength percentage, RSI value, and momentum reading
Interpretation:
Trend Direction: Bullish when Fast EMA crosses above Slow EMA with strength confirmation
Trend Strength > 1%: Strong trending conditions with institutional participation
RSI > 70: Overbought conditions, potential selling opportunity
RSI < 30: Oversold conditions, potential buying opportunity
Momentum Divergence: Price and momentum moving opposite directions signal potential reversals
Support/Resistance Proximity: Dynamic levels provide optimal entry/exit zones
Combined Signals: Trend changes with momentum confirmation generate high-probability opportunities
🔶 EXAMPLES
Trend Confirmation: Fast EMA crossing above Slow EMA with trend strength exceeding 1% and positive momentum confirms strong bullish conditions.
Example: During institutional accumulation phases, EMA crossovers with momentum confirmation have historically preceded significant upward moves, providing optimal long entry points.
15min
4H
Momentum Divergence Detection: RSI reaching overbought levels while momentum decreases despite rising prices signals potential trend exhaustion.
Example: Bearish divergence signals appearing at resistance levels have marked major market tops, allowing traders to secure profits before corrections.
Support/Resistance Integration: Dynamic pivot-based levels combined with trend and momentum signals create high-probability trading zones.
Example: Bullish trend changes occurring near established support levels offer optimal risk-reward entries with clearly defined stop-loss levels.
Multi-Dimensional Confirmation: The indicator's combination of trend, momentum, and structural analysis provides comprehensive market validation.
Example: When trend direction aligns with momentum characteristics near key structural levels, the confluence creates institutional-grade trading opportunities with enhanced probability of success.
🔶 SETTINGS
Customization Options:
Trend Analysis: Fast EMA Length (default: 12), Slow EMA Length (default: 26), Trend Strength Period (default: 14)
Support & Resistance: Pivot Length for level detection (default: 10), Maximum S/R Levels displayed (default: 3), Toggle S/R visibility
Momentum Settings: RSI Length (default: 14), Oversold Level (default: 30), Overbought Level (default: 70)
Visual Configuration: Color schemes for bullish/bearish/neutral conditions, transparency settings for fills, momentum candle overlay toggle
Display Options: Analysis table visibility, divergence marker size, alert system configuration
The Advanced Trend Momentum indicator provides traders with comprehensive insights into market dynamics through its sophisticated integration of trend analysis, momentum assessment, and structural level detection. By combining multiple analytical dimensions into a unified framework, this tool helps identify high-probability opportunities while filtering out market noise through its multi-confirmation approach, enabling traders to make informed decisions across various market cycles and timeframes.

Advanced Price Ranges ICTThis indicator automatically divides price into fixed ranges (configurable in points or pips) and plots important reference levels such as the high, low, 50% midpoint, and 25%/75% quarters. It is designed to help traders visualize structured price movement, spot confluence zones, and frame their trading bias around clean range-based levels.
🔹 Key Features
Custom Range Size: Define ranges in points (e.g., 100, 50, 25, 10) or in Forex pips.
Forex Mode: Automatically adapts pip size (0.0001 or 0.01 for JPY pairs).
Dynamic Anchoring: Price ranges automatically align to the current price, snapping into blocks.
Multiple Ranges: Option to extend visualization above and below the current active block for a complete grid.
Level Types:
High / Low of the range
50% midpoint
25% and 75% quarters
Custom Styling: Adjustable line colors and widths for each level type.
Labels: Optional right-edge labels showing level type and exact price.
Alerts: Built-in alerts for when price crosses the range high, low, or 50% midpoint.
🔹 Use Cases
Quickly map out 100/50/25/10 point structures like Zeussy’s advanced price range method.
Identify key reaction levels where liquidity is often built or swept.
Support ICT-style concepts like range-based bias, fair value gaps, and liquidity pools.
Works for indices, futures, crypto, and forex.
🔹 Customization
Range increments can be set to any size (default 100).
Toggle which levels are shown (High/Low, Midpoint, Quarters).
Adjustable line widths, colors, and label visibility.
Extend ranges above and below for broader market context.
On-Balance Volume with Multiple MA TypesOn-Balance Volume with Multiple MA Types
English Description
Overview
This is the first version of the "On-Balance Volume with Multiple MA Types" indicator designed to overlay directly on the price chart, a significant evolution from its previous iterations, which functioned solely as an oscillator in a separate window. The indicator calculates On-Balance Volume (OBV) and applies various smoothing methods to provide a clear view of volume dynamics in relation to price movements. It is pinned to the price scale for seamless integration with the chart.
Interpretation Recommendations
Price Pushing the OBV Line from Below: When the price chart pushes the OBV line upward and remains below it, this indicates rising volume, suggesting strong buying pressure.
Price Above the OBV Line: When the price chart is above the OBV line, it signals falling volume, indicating weakening momentum or selling pressure.
OBV Line Crossings: When the price crosses the OBV line, it represents a balance point in volume dynamics. The price level at the current crossing can be compared to the previous crossing to assess changes in market sentiment or momentum.
Moving Average Types
The indicator offers eight smoothing options for the OBV line, each with unique characteristics:
EMA (Exponential Moving Average): A weighted average that prioritizes recent data, providing a smooth yet responsive line.
DEMA (Double Exponential Moving Average): Uses two EMAs to reduce lag, offering faster response to volume changes.
HMA (Hull Moving Average): Combines weighted moving averages to minimize lag while maintaining smoothness.
WMA (Weighted Moving Average): Assigns more weight to recent data, balancing responsiveness and noise reduction.
TMA (Triangular Moving Average): A double-smoothed simple moving average, emphasizing central data points for smoother output.
VIDYA (Variable Index Dynamic Average): Adapts smoothing based on market volatility, using a CMO (Chande Momentum Oscillator) for dynamic weighting. Controlled by the VIDYA Alpha parameter (default: 0.2, range: 0–1), which adjusts sensitivity to volatility.
FRAMA (Fractal Adaptive Moving Average): Adjusts smoothing based on fractal dimensions of the OBV data, adapting to market conditions.
JMA (Jurik Moving Average): A proprietary adaptive average designed for minimal lag and high smoothness. Controlled by two parameters:
JMA Phase (default: 50, range: -100 to 100): Adjusts the balance between responsiveness and smoothness.
JMA Power (default: 1, range: 0.1+): Controls the strength of smoothing.
Input Parameters
OBV MA Length (default: 10): The lookback period for smoothing the OBV. Higher values produce smoother results but increase lag.
OBV MA Type (default: JMA): Selects the moving average type from the eight options listed above.
Line Width (default: 2): Thickness of the OBV line on the chart.
Bullish Color (default: Blue): Color of the OBV line when rising (indicating increasing volume).
Bearish Color (default: Red): Color of the OBV line when falling (indicating decreasing volume).
JMA Phase (default: 50): Adjusts the JMA’s responsiveness (used only when JMA is selected).
JMA Power (default: 1): Adjusts the JMA’s smoothing strength (used only when JMA is selected).
VIDYA Alpha (default: 0.2): Controls the sensitivity of VIDYA to market volatility (used only when VIDYA is selected).
How to Use
Add the indicator to your TradingView chart. It will overlay directly on the price chart, aligned with the price scale.
Adjust the OBV MA Type to select your preferred smoothing method based on your trading style (e.g., JMA for low lag, TMA for smoothness).
Modify the OBV MA Length to balance responsiveness and noise reduction. Shorter periods (e.g., 5–10) are better for short-term trading, while longer periods (e.g., 20–50) suit longer-term analysis.
Use the Bullish Color and Bearish Color to visually distinguish rising and falling volume trends.
For JMA or VIDYA, fine-tune the JMA Phase, JMA Power, or VIDYA Alpha to optimize the indicator for specific market conditions.
Interpret the OBV line in relation to price:
Watch for price pushing the OBV line upward (rising volume) or moving above it (falling volume).
Note crossings of the OBV line to identify balance points and compare with prior crossings to gauge momentum shifts.
Combine with other technical tools (e.g., support/resistance levels, trendlines) for a comprehensive trading strategy.
Notes
This indicator is designed to work on any timeframe and market, but its effectiveness depends on the chosen moving average type and parameters.
Experiment with different MA types and lengths to find the best fit for your trading approach.
The indicator is licensed under the Mozilla Public License 2.0 and copyrighted by TradingStrategyCourses © 2025.
