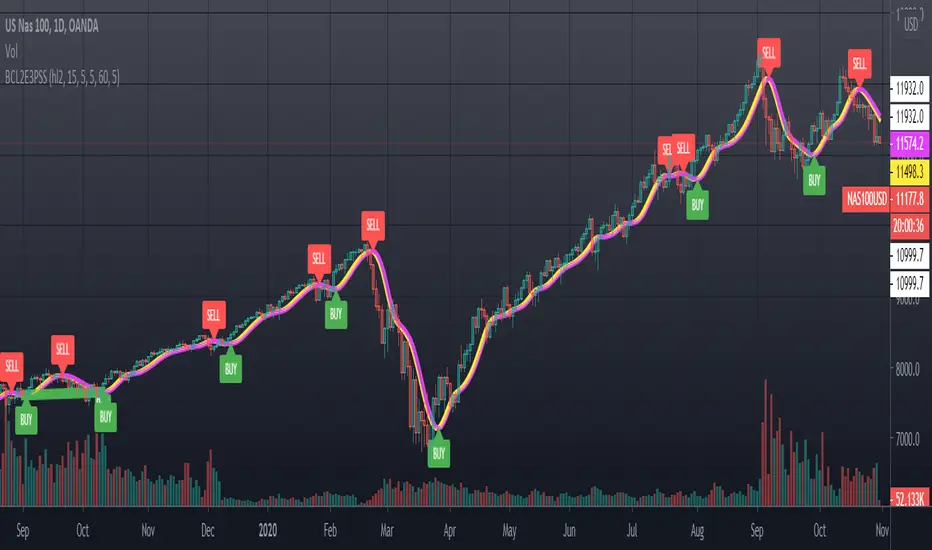
SuperSmoother MA OscillatorSuperSmoother MA Oscillator - Ehlers-Inspired Lag-Minimized Signal Framework
Overview
The SuperSmoother MA Oscillator is a crossover and momentum detection framework built on the pioneering work of John F. Ehlers, who introduced digital signal processing (DSP) concepts into technical analysis. Traditional moving averages such as SMA and EMA are prone to two persistent flaws: excessive lag, which delays recognition of trend shifts, and high-frequency noise, which produces unreliable whipsaw signals. Ehlers’ SuperSmoother filter was designed to specifically address these flaws by creating a low-pass filter with minimal lag and superior noise suppression, inspired by engineering methods used in communications and radar systems.
This oscillator extends Ehlers’ foundation by combining the SuperSmoother filter with multi-length moving average oscillation, ATR-based normalization, and dynamic color coding. The result is a tool that helps traders identify market momentum, detect reliable crossovers earlier than conventional methods, and contextualize volatility and phase shifts without being distracted by transient price noise.
Unlike conventional oscillators, which either oversimplify price structure or overload the chart with reactive signals, the SuperSmoother MA Oscillator is designed to balance responsiveness and stability. By preprocessing price data with the SuperSmoother filter, traders gain a signal framework that is clean, robust, and adaptable across assets and timeframes.
Theoretical Foundation
Traditional MA oscillators such as MACD or dual-EMA systems react to raw or lightly smoothed price inputs. While effective in some conditions, these signals are often distorted by high-frequency oscillations inherent in market data, leading to false crossovers and poor timing. The SuperSmoother approach modifies this dynamic: by attenuating unwanted frequencies, it preserves structural price movements while eliminating meaningless noise.
This is particularly useful for traders who need to distinguish between genuine market cycles and random short-term price flickers. In practical terms, the oscillator helps identify:
Early trend continuations (when fast averages break cleanly above/below slower averages).
Preemptive breakout setups (when compressed oscillator ranges expand).
Exhaustion phases (when oscillator swings flatten despite continued price movement).
Its multi-purpose design allows traders to apply it flexibly across scalping, day trading, swing setups, and longer-term trend positioning, without needing separate tools for each.
The oscillator’s visual system - fast/slow lines, dynamic coloration, and zero-line crossovers - is structured to provide trend clarity without hiding nuance. Strong green/red momentum confirms directional conviction, while neutral gray phases emphasize uncertainty or low conviction. This ensures traders can quickly gauge the market state without losing access to subtle structural signals.
How It Works
The SuperSmoother MA Oscillator builds signals through a layered process:
SuperSmoother Filtering (Ehlers’ Method)
At its core lies Ehlers’ two-pole recursive filter, mathematically engineered to suppress high-frequency components while introducing minimal lag. Compared to traditional EMA smoothing, the SuperSmoother achieves better spectral separation - it allows meaningful cyclical market structures to pass through, while eliminating erratic spikes and aliasing. This makes it a superior preprocessing stage for oscillator inputs.
Fast and Slow Line Construction
Within the oscillator framework, the filtered price series is used to build two internal moving averages: a fast line (short-term momentum) and a slow line (longer-term directional bias). These are not plotted directly on the chart - instead, their relationship is transformed into the oscillator values you see.
The interaction between these two internal averages - crossovers, separation, and compression - forms the backbone of trend detection:
Uptrend Signal : Fast MA rises above the slow MA with expanding distance, generating a positive oscillator swing.
Downtrend Signal : Fast MA falls below the slow MA with widening divergence, producing a negative oscillator swing.
Neutral/Transition : Lines compress, flattening the oscillator near zero and often preceding volatility expansion.
This design ensures traders receive the information content of dual-MA crossovers while keeping the chart visually clean and focused on the oscillator’s dynamics.
ATR-Based Normalization
Markets vary in volatility. To ensure the oscillator behaves consistently across assets, ATR (Average True Range) normalization scales outputs relative to prevailing volatility conditions. This prevents the oscillator from appearing overly sensitive in calm markets or too flat during high-volatility regimes.
Dynamic Color Coding
Color transitions reflect underlying market states:
Strong Green : Bullish alignment, momentum expanding.
Strong Red : Bearish alignment, momentum expanding.
These visual cues allow traders to quickly gauge trend direction and strength at a glance, with expanding colors indicating increasing conviction in the underlying momentum.
Interpretation
The oscillator offers a multi-dimensional view of price dynamics:
Trend Analysis : Fast/slow line alignment and zero-line interactions reveal trend direction and strength. Expansions indicate momentum building; contractions flag weakening conditions or potential reversals.
Momentum & Volatility : Rapid divergence between lines reflects increasing momentum. Compression highlights periods of reduced volatility and possible upcoming expansion.
Cycle Awareness : Because of Ehlers’ DSP foundation, the oscillator captures market cycles more cleanly than conventional MA systems, allowing traders to anticipate turning points before raw price action confirms them.
Divergence Detection : When oscillator momentum fades while price continues in the same direction, it signals exhaustion - a cue to tighten stops or anticipate reversals.
By focusing on filtered, volatility-adjusted signals, traders avoid overreacting to noise while gaining early access to structural changes in momentum.
Strategy Integration
The SuperSmoother MA Oscillator adapts across multiple trading approaches:
Trend Following
Enter when fast/slow alignment is strong and expanding:
A fast line crossing above the slow line with expanding green signals confirms bullish continuation.
Use ATR-normalized expansion to filter entries in line with prevailing volatility.
Breakout Trading
Periods of compression often precede breakouts:
A breakout occurs when fast lines diverge decisively from slow lines with renewed green/red strength.
Exhaustion and Reversals
Oscillator divergence signals weakening trends:
Flattening momentum while price continues trending may indicate overextension.
Traders can exit or hedge positions in anticipation of corrective phases.
Multi-Timeframe Confluence
Apply the oscillator on higher timeframes to confirm the directional bias.
Use lower timeframes for refined entries during compression → expansion transitions.
Technical Implementation Details
SuperSmoother Algorithm (Ehlers) : Recursive two-pole filter minimizes lag while removing high-frequency noise.
Oscillator Framework : Fast/slow MAs derived from filtered prices.
ATR Normalization : Ensures consistent amplitude across market regimes.
Dynamic Color Engine : Aligns visual cues with structural states (expansion and contraction).
Multi-Factor Analysis : Combines crossover logic, volatility context, and cycle detection for robust outputs.
This layered approach ensures the oscillator is highly responsive without overloading charts with noise.
Optimal Application Parameters
Asset-Specific Guidance:
Forex : Normalize with moderate ATR scaling; focus on slow-line confirmation.
Equities : Balance responsiveness with smoothing; useful for capturing sector rotations.
Cryptocurrency : Higher ATR multipliers recommended due to volatility.
Futures/Indices : Lower frequency settings highlight structural trends.
Timeframe Optimization:
Scalping (1-5min) : Higher sensitivity, prioritize fast-line signals.
Intraday (15m-1h) : Balance between fast/slow expansions.
Swing (4h-Daily) : Focus on slow-line momentum with fast-line timing.
Position (Daily-Weekly) : Slow lines dominate; fast lines highlight cycle shifts.
Performance Characteristics
High Effectiveness:
Trending environments with moderate-to-high volatility.
Assets with steady liquidity and clear cyclical structures.
Reduced Effectiveness:
Flat/choppy conditions with little directional bias.
Ultra-short timeframes (<1m), where noise dominates.
Integration Guidelines
Confluence : Combine with liquidity zones, order blocks, and volume-based indicators for confirmation.
Risk Management : Place stops beyond slow-line thresholds or ATR-defined zones.
Dynamic Trade Management : Use expansions/contractions to scale position sizes or tighten stops.
Multi-Timeframe Confirmation : Filter lower-timeframe entries with higher-timeframe momentum states.
Disclaimer
The SuperSmoother MA Oscillator is an advanced trend and momentum analysis tool, not a guaranteed profit system. Its effectiveness depends on proper parameter settings per asset and disciplined risk management. Traders should use it as part of a broader technical framework and not in isolation.
Supersmoother
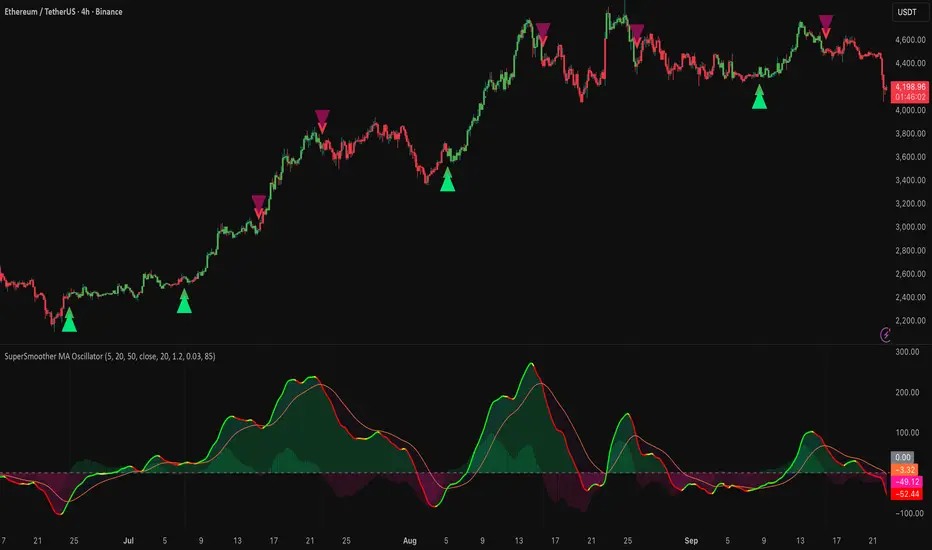
[GYTS] Ultimate Smoother (3-poles + 2 poles)Ultimate Smoother (3-pole)
🌸 Part of GoemonYae Trading System (GYTS) 🌸
🌸 --------- INTRODUCTION --------- 🌸
💮 Release of 3-Pole Ultimate Smoother
This indicator presents a new 3-pole version of John Ehlers' Ultimate Smoother (2024) . This results in an unconventional filter that exhibits effectively zero lag in practical trading applications, regardless of the set period. By using a 2-pole high-pass filter in its design, it responds to price direction changes on the same bar, while still allowing the user to control smoothness.
💮 What is the Ultimate Smoother?
The original Ultimate Smoother is a revolutionary filter designed by John Ehlers (2024) that smooths price data with virtually zero lag in the pass band. While conventional filters always introduce lag when removing market noise, the Ultimate Smoother maintains phase alignment at low frequencies while still providing excellent noise reduction.
💮 Mathematical Foundation
The Ultimate Smoother achieves its remarkable properties through a clever mathematical approach:
1. Instead of directly designing a low-pass filter (like traditional moving averages), it subtracts a high-pass filter from an all-pass filter (the original input data).
2. At very low frequencies, the high-pass filter contributes almost nothing, so the output closely matches the input in both amplitude and phase.
3. At higher frequencies, the high-pass filter's response increasingly matches the input data, resulting in cancellation through subtraction.
The 3-pole version extends this principle by using a higher-order high-pass filter, requiring additional coefficients and handling more terms in the numerator of the transfer function.
🌸 --------- USAGE GUIDE --------- 🌸
💮 Period Parameter Behaviour
The period parameter in the 3-pole Ultimate Smoother works somewhat counterintuitively:
- Longer periods: Result in less smooth, but more responsive following of the price. The filter output more closely tracks the input data.
- Shorter periods: Produce smoother output but may exhibit overshooting (extrapolating price movement) for larger movements.
This is different from most filters where longer periods typically produce smoother outputs with more lag.
💮 When to Choose 3-Pole vs. 2-Pole
- Choose the 3-pole version when you need zero-lag but want to control the smoothness
- Choose the 2-pole version when you are okay with some lag with the benefit of more smoothness.
🌸 --------- ACKNOWLEDGEMENTS --------- 🌸
This indicator builds upon the pioneering work of John Ehlers, particularly from his article April 2024 edition of TASC's Traders' Tips . The original version is published on TradingView by @PineCodersTASC .
This 3-pole extension was developed by @GoemonYae . Feedback is highly appreciated!

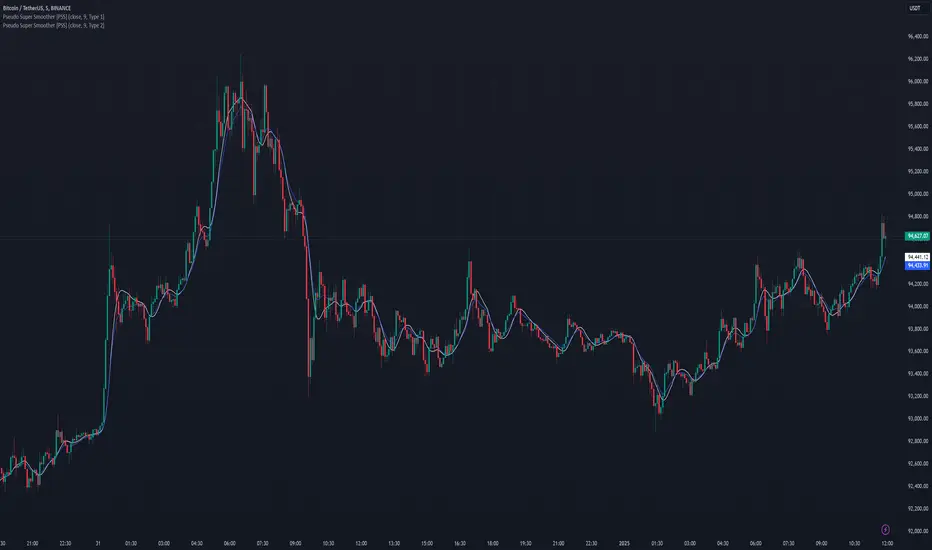
Pseudo Super Smoother [PSS]The Pseudo Super Smoother (PSS) is a a Finite Impulse Response (FIR) filter. It provides a smoothed representation of the underlying data. This indicator can be considered a variation of a moving average, offering a unique approach to filtering price or other data series.
The PSS is inspired by the Super Smoother filter, known for its ability to reduce noise while maintaining a relatively low delay. However, the Super Smoother is an Infinite Impulse Response (IIR) filter. The PSS attempts to approximate some characteristics of the Super Smoother using an FIR design, which offers inherent stability.
The indicator offers two distinct filter types, selectable via the "Filter Style" input: Type 1 and Type 2 . Type 1 provides a smoother output with a more gradual response to changes in the input data. It is characterized by a greater attenuation of high-frequency components. Type 2 exhibits increased reactivity compared to Type 1 , allowing for a faster response to shifts in the underlying data trend, albeit with a potential overshoot. The choice between these two types will depend on the specific application and the preference for responsiveness versus smoothness.
The PSS calculates the FIR filter coefficients based on a decaying exponential function, adjusted according to the selected filter type and the user-defined period. The filter then applies these coefficients to a window of past data, effectively creating a weighted average that emphasizes more recent data points to varying degrees. The PSS uses a specific initialization technique that uses the first non-null data point to pre-fill the input window, which helps it start right away.
The PSS is an approximation of the Super Smoother filter using an FIR design. While it try's to emulate some of the Super Smoother's smoothing characteristics, users should be aware that the frequency response and overall behavior will differ due to it being a rough approximation. The PSS should be considered an experimental indicator and used in conjunction with other analysis techniques. This is, effectively, just another moving average, but its novelty lies in its attempt to bridge the gap between FIR and IIR filter designs for a specific smoothing goal.
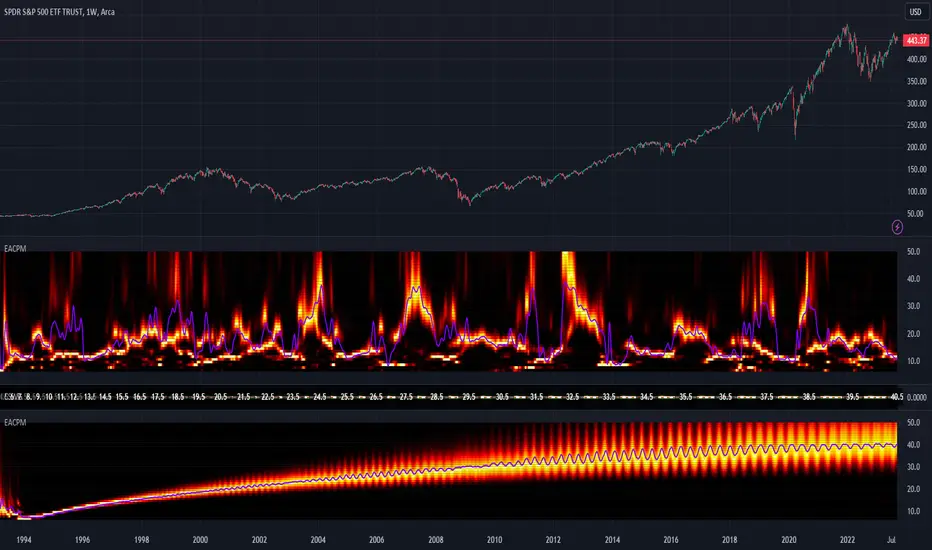
[Excalibur] Ehlers AutoCorrelation Periodogram ModifiedKeep your coins folks, I don't need them, don't want them. If you wish be generous, I do hope that charitable peoples worldwide with surplus food stocks may consider stocking local food banks before stuffing monetary bank vaults, for the crusade of remedying the needs of less than fortunate children, parents, elderly, homeless veterans, and everyone else who deserves nutritional sustenance for the soul.
DEDICATION:
This script is dedicated to the memory of Nikolai Dmitriyevich Kondratiev (Никола́й Дми́триевич Кондра́тьев) as tribute for being a pioneering economist and statistician, paving the way for modern econometrics by advocation of rigorous and empirical methodologies. One of his most substantial contributions to the study of business cycle theory include a revolutionary hypothesis recognizing the existence of dynamic cycle-like phenomenon inherent to economies that are characterized by distinct phases of expansion, stagnation, recession and recovery, what we now know as "Kondratiev Waves" (K-waves). Kondratiev was one of the first economists to recognize the vital significance of applying quantitative analysis on empirical data to evaluate economic dynamics by means of statistical methods. His understanding was that conceptual models alone were insufficient to adequately interpret real-world economic conditions, and that sophisticated analysis was necessary to better comprehend the nature of trending/cycling economic behaviors. Additionally, he recognized prosperous economic cycles were predominantly driven by a combination of technological innovations and infrastructure investments that resulted in profound implications for economic growth and development.
I will mention this... nation's economies MUST be supported and defended to continuously evolve incrementally in order to flourish in perpetuity OR suffer through eras with lasting ramifications of societal stagnation and implosion.
Analogous to the realm of economics, aperiodic cycles/frequencies, both enduring and ephemeral, do exist in all facets of life, every second of every day. To name a few that any blind man can naturally see are: heartbeat (cardiac cycles), respiration rates, circadian rhythms of sleep, powerful magnetic solar cycles, seasonal cycles, lunar cycles, weather patterns, vegetative growth cycles, and ocean waves. Do not pretend for one second that these basic aforementioned examples do not affect business cycle fluctuations in minuscule and monumental ways hour to hour, day to day, season to season, year to year, and decade to decade in every nation on the planet. Kondratiev's original seminal theories in macroeconomics from nearly a century ago have proven remarkably prescient with many of his antiquated elementary observations/notions/hypotheses in macroeconomics being scholastically studied and topically researched further. Therefore, I am compelled to honor and recognize his statistical insight and foresight.
If only.. Kondratiev could hold a pocket sized computer in the cup of both hands bearing the TradingView logo and platform services, I truly believe he would be amazed in marvelous delight with a GARGANTUAN smile on his face.
INTRODUCTION:
Firstly, this is NOT technically speaking an indicator like most others. I would describe it as an advanced cycle period detector to obtain market data spectral estimates with low latency and moderate frequency resolution. Developers can take advantage of this detector by creating scripts that utilize a "Dominant Cycle Source" input to adaptively govern algorithms. Be forewarned, I would only recommend this for advanced developers, not novice code dabbling. Although, there is some Pine wizardry introduced here for novice Pine enthusiasts to witness and learn from. AI did describe the code into one super-crunched sentence as, "a rare feat of exceptionally formatted code masterfully balancing visual clarity, precision, and complexity to provide immense educational value for both programming newcomers and expert Pine coders alike."
Understand all of the above aforementioned? Buckle up and proceed for a lengthy read of verbose complexity...
This is my enhanced and heavily modified version of autocorrelation periodogram (ACP) for Pine Script v5.0. It was originally devised by the mathemagician John Ehlers for detecting dominant cycles (frequencies) in an asset's price action. I have been sitting on code similar to this for a long time, but I decided to unleash the advanced code with my fashion. Originally Ehlers released this with multiple versions, one in a 2016 TASC article and the other in his last published 2013 book "Cycle Analytics for Traders", chapter 8. He wasn't joking about "concepts of advanced technical trading" and ACP is nowhere near to his most intimidating and ingenious calculations in code. I will say the book goes into many finer details about the original periodogram, so if you wish to delve into even more elaborate info regarding Ehlers' original ACP form AND how you may adapt algorithms, you'll have to obtain one. Note to reader, comparing Ehlers' original code to my chimeric code embracing the "Power of Pine", you will notice they have little resemblance.
What you see is a new species of autocorrelation periodogram combining Ehlers' innovation with my fascinations of what ACP could be in a Pine package. One other intention of this script's code is to pay homage to Ehlers' lifelong works. Like Kondratiev, Ehlers is also a hardcore cycle enthusiast. I intend to carry on the fire Ehlers envisioned and I believe that is literally displayed here as a pleasant "fiery" example endowed with Pine. With that said, I tried to make the code as computationally efficient as possible, without going into dozens of more crazy lines of code to speed things up even more. There's also a few creative modifications I made by making alterations to the originating formulas that I felt were improvements, one of them being lag reduction. By recently questioning every single thing I thought I knew about ACP, combined with the accumulation of my current knowledge base, this is the innovative revision I came up with. I could have improved it more but decided not to mind thrash too many TV members, maybe later...
I am now confident Pine should have adequate overhead left over to attach various indicators to the dominant cycle via input.source(). TV, I apologize in advance if in the future a server cluster combusts into a raging inferno... Coders, be fully prepared to build entire algorithms from pure raw code, because not all of the built-in Pine functions fully support dynamic periods (e.g. length=ANYTHING). Many of them do, as this was requested and granted a while ago, but some functions are just inherently finicky due to implementation combinations and MUST be emulated via raw code. I would imagine some comprehensive library or numerous authored scripts have portions of raw code for Pine built-ins some where on TV if you look diligently enough.
Notice: Unfortunately, I will not provide any integration support into member's projects at all. I have my own projects that require way too much of my day already. While I was refactoring my life (forgoing many other "important" endeavors) in the early half of 2023, I primarily focused on this code over and over in my surplus time. During that same time I was working on other innovations that are far above and beyond what this code is. I hope you understand.
The best way programmatically may be to incorporate this code into your private Pine project directly, after brutal testing of course, but that may be too challenging for many in early development. Being able to see the periodogram is also beneficial, so input sourcing may be the "better" avenue to tether portions of the dominant cycle to algorithms. Unique indication being able to utilize the dominantCycle may be advantageous when tethering this script to those algorithms. The easiest way is to manually set your indicators to what ACP recognizes as the dominant cycle, but that's actually not considered dynamic real time adaption of an indicator. Different indicators may need a proportion of the dominantCycle, say half it's value, while others may need the full value of it. That's up to you to figure that out in practice. Sourcing one or more custom indicators dynamically to one detector's dominantCycle may require code like this: `int sourceDC = int(math.max(6, math.min(49, input.source(close, "Dominant Cycle Source"))))`. Keep in mind, some algos can use a float, while algos with a for loop require an integer.
I have witnessed a few attempts by talented TV members for a Pine based autocorrelation periodogram, but not in this caliber. Trust me, coding ACP is no ordinary task to accomplish in Pine and modifying it blessed with applicable improvements is even more challenging. For over 4 years, I have been slowly improving this code here and there randomly. It is beautiful just like a real flame, but... this one can still burn you! My mind was fried to charcoal black a few times wrestling with it in the distant past. My very first attempt at translating ACP was a month long endeavor because PSv3 simply didn't have arrays back then. Anyways, this is ACP with a newer engine, I hope you enjoy it. Any TV subscriber can utilize this code as they please. If you are capable of sufficiently using it properly, please use it wisely with intended good will. That is all I beg of you.
Lastly, you now see how I have rasterized my Pine with Ehlers' swami-like tech. Yep, this whole time I have been using hline() since PSv3, not plot(). Evidently, plot() still has a deficiency limited to only 32 plots when it comes to creating intense eye candy indicators, the last I checked. The use of hline() is the optimal choice for rasterizing Ehlers styled heatmaps. This does only contain two color schemes of the many I have formerly created, but that's all that is essentially needed for this gizmo. Anything else is generally for a spectacle or seeing how brutal Pine can be color treated. The real hurdle is being able to manipulate colors dynamically with Merlin like capabilities from multiple algo results. That's the true challenging part of these heatmap contraptions to obtain multi-colored "predator vision" level indication. You now have basic hline() food for thought empowerment to wield as you can imaginatively dream in Pine projects.
PERIODOGRAM UTILITY IN REAL WORLD SCENARIOS:
This code is a testament to the abilities that have yet to be fully realized with indication advancements. Periodograms, spectrograms, and heatmaps are a powerful tool with real-world applications in various fields such as financial markets, electrical engineering, astronomy, seismology, and neuro/medical applications. For instance, among these diverse fields, it may help traders and investors identify market cycles/periodicities in financial markets, support engineers in optimizing electrical or acoustic systems, aid astronomers in understanding celestial object attributes, assist seismologists with predicting earthquake risks, help medical researchers with neurological disorder identification, and detection of asymptomatic cardiovascular clotting in the vaxxed via full body thermography. In either field of study, technologies in likeness to periodograms may very well provide us with a better sliver of analysis beyond what was ever formerly invented. Periodograms can identify dominant cycles and frequency components in data, which may provide valuable insights and possibly provide better-informed decisions. By utilizing periodograms within aspects of market analytics, individuals and organizations can potentially refrain from making blinded decisions and leverage data-driven insights instead.
PERIODOGRAM INTERPRETATION:
The periodogram renders the power spectrum of a signal, with the y-axis representing the periodicity (frequencies/wavelengths) and the x-axis representing time. The y-axis is divided into periods, with each elevation representing a period. In this periodogram, the y-axis ranges from 6 at the very bottom to 49 at the top, with intermediate values in between, all indicating the power of the corresponding frequency component by color. The higher the position occurs on the y-axis, the longer the period or lower the frequency. The x-axis of the periodogram represents time and is divided into equal intervals, with each vertical column on the axis corresponding to the time interval when the signal was measured. The most recent values/colors are on the right side.
The intensity of the colors on the periodogram indicate the power level of the corresponding frequency or period. The fire color scheme is distinctly like the heat intensity from any casual flame witnessed in a small fire from a lighter, match, or camp fire. The most intense power would be indicated by the brightest of yellow, while the lowest power would be indicated by the darkest shade of red or just black. By analyzing the pattern of colors across different periods, one may gain insights into the dominant frequency components of the signal and visually identify recurring cycles/patterns of periodicity.
SETTINGS CONFIGURATIONS BRIEFLY EXPLAINED:
Source Options: These settings allow you to choose the data source for the analysis. Using the `Source` selection, you may tether to additional data streams (e.g. close, hlcc4, hl2), which also may include samples from any other indicator. For example, this could be my "Chirped Sine Wave Generator" script found in my member profile. By using the `SineWave` selection, you may analyze a theoretical sinusoidal wave with a user-defined period, something already incorporated into the code. The `SineWave` will be displayed over top of the periodogram.
Roofing Filter Options: These inputs control the range of the passband for ACP to analyze. Ehlers had two versions of his highpass filters for his releases, so I included an option for you to see the obvious difference when performing a comparison of both. You may choose between 1st and 2nd order high-pass filters.
Spectral Controls: These settings control the core functionality of the spectral analysis results. You can adjust the autocorrelation lag, adjust the level of smoothing for Fourier coefficients, and control the contrast/behavior of the heatmap displaying the power spectra. I provided two color schemes by checking or unchecking a checkbox.
Dominant Cycle Options: These settings allow you to customize the various types of dominant cycle values. You can choose between floating-point and integer values, and select the rounding method used to derive the final dominantCycle values. Also, you may control the level of smoothing applied to the dominant cycle values.
DOMINANT CYCLE VALUE SELECTIONS:
External to the acs() function, the code takes a dominant cycle value returned from acs() and changes its numeric form based on a specified type and form chosen within the indicator settings. The dominant cycle value can be represented as an integer or a decimal number, depending on the attached algorithm's requirements. For example, FIR filters will require an integer while many IIR filters can use a float. The float forms can be either rounded, smoothed, or floored. If the resulting value is desired to be an integer, it can be rounded up/down or just be in an integer form, depending on how your algorithm may utilize it.
AUTOCORRELATION SPECTRUM FUNCTION BASICALLY EXPLAINED:
In the beginning of the acs() code, the population of caches for precalculated angular frequency factors and smoothing coefficients occur. By precalculating these factors/coefs only once and then storing them in an array, the indicator can save time and computational resources when performing subsequent calculations that require them later.
In the following code block, the "Calculate AutoCorrelations" is calculated for each period within the passband width. The calculation involves numerous summations of values extracted from the roofing filter. Finally, a correlation values array is populated with the resulting values, which are normalized correlation coefficients.
Moving on to the next block of code, labeled "Decompose Fourier Components", Fourier decomposition is performed on the autocorrelation coefficients. It iterates this time through the applicable period range of 6 to 49, calculating the real and imaginary parts of the Fourier components. Frequencies 6 to 49 are the primary focus of interest for this periodogram. Using the precalculated angular frequency factors, the resulting real and imaginary parts are then utilized to calculate the spectral Fourier components, which are stored in an array for later use.
The next section of code smooths the noise ridden Fourier components between the periods of 6 and 49 with a selected filter. This species also employs numerous SuperSmoothers to condition noisy Fourier components. One of the big differences is Ehlers' versions used basic EMAs in this section of code. I decided to add SuperSmoothers.
The final sections of the acs() code determines the peak power component for normalization and then computes the dominant cycle period from the smoothed Fourier components. It first identifies a single spectral component with the highest power value and then assigns it as the peak power. Next, it normalizes the spectral components using the peak power value as a denominator. It then calculates the average dominant cycle period from the normalized spectral components using Ehlers' "Center of Gravity" calculation. Finally, the function returns the dominant cycle period along with the normalized spectral components for later external use to plot the periodogram.
POST SCRIPT:
Concluding, I have to acknowledge a newly found analyst for assistance that I couldn't receive from anywhere else. For one, Claude doesn't know much about Pine, is unfortunately color blind, and can't even see the Pine reference, but it was able to intuitively shred my code with laser precise realizations. Not only that, formulating and reformulating my description needed crucial finesse applied to it, and I couldn't have provided what you have read here without that artificial insight. Finding the right order of words to convey the complexity of ACP and the elaborate accompanying content was a daunting task. No code in my life has ever absorbed so much time and hard fricking work, than what you witness here, an ACP gem cut pristinely. I'm unveiling my version of ACP for an empowering cause, in the hopes a future global army of code wielders will tether it to highly functional computational contraptions they might possess. Here is ACP fully blessed poetically with the "Power of Pine" in sublime code. ENJOY!
Stochastic of Two-Pole SuperSmoother [Loxx]Stochastic of Two-Pole SuperSmoother is a Stochastic Indicator that takes as input Two-Pole SuperSmoother of price. Includes gradient coloring and Discontinued Signal Lines signals with alerts.
What is Ehlers ; Two-Pole Super Smoother?
From "Cycle Analytics for Traders Advanced Technical Trading Concepts" by John F. Ehlers
A SuperSmoother filter is used anytime a moving average of any type would otherwise be used, with the result that the SuperSmoother filter output would have substantially less lag for an equivalent amount of smoothing produced by the moving average. For example, a five-bar SMA has a cutoff period of approximately 10 bars and has two bars of lag. A SuperSmoother filter with a cutoff period of 10 bars has a lag a half bar larger than the two-pole modified Butterworth filter.Therefore, such a SuperSmoother filter has a maximum lag of approximately 1.5 bars and even less lag into the attenuation band of the filter. The differential in lag between moving average and SuperSmoother filter outputs becomes even larger when the cutoff periods are larger.
Market data contain noise, and removal of noise is the reason for using smoothing filters. In fact, market data contain several kinds of noise. I’ll group one kind of noise as systemic, caused by the random events of trades being exercised. A second kind of noise is aliasing noise, caused by the use of sampled data. Aliasing noise is the dominant term in the data for shorter cycle periods.
It is easy to think of market data as being a continuous waveform, but it is not. Using the closing price as representative for that bar constitutes one sample point. It doesn’t matter if you are using an average of the high and low instead of the close, you are still getting one sample per bar. Since sampled data is being used, there are some dSP aspects that must be considered. For example, the shortest analysis period that is possible (without aliasing)2 is a two-bar cycle.This is called the Nyquist frequency, 0.5 cycles per sample.A perfect two-bar sine wave cycle sampled at the peaks becomes a square wave due to sampling. However, sampling at the cycle peaks can- not be guaranteed, and the interference between the sampling frequency and the data frequency creates the aliasing noise.The noise is reduced as the data period is longer. For example, a four-bar cycle means there are four samples per cycle. Because there are more samples, the sampled data are a better replica of the sine wave component. The replica is better yet for an eight-bar data component.The improved fidelity of the sampled data means the aliasing noise is reduced at longer and longer cycle periods.The rate of reduction is 6 dB per octave. My experience is that the systemic noise rarely is more than 10 dB below the level of cyclic information, so that we create two conditions for effective smoothing of aliasing noise:
1. It is difficult to use cycle periods shorter that two octaves below the Nyquist frequency.That is, an eight-bar cycle component has a quantization noise level 12 dB below the noise level at the Nyquist frequency. longer cycle components therefore have a systemic noise level that exceeds the aliasing noise level.
2. A smoothing filter should have sufficient selectivity to reduce aliasing noise below the systemic noise level. Since aliasing noise increases at the rate of 6 dB per octave above a selected filter cutoff frequency and since the SuperSmoother attenuation rate is 12 dB per octave, the Super- Smoother filter is an effective tool to virtually eliminate aliasing noise in the output signal.
What are DSL Discontinued Signal Line?
A lot of indicators are using signal lines in order to determine the trend (or some desired state of the indicator) easier. The idea of the signal line is easy : comparing the value to it's smoothed (slightly lagging) state, the idea of current momentum/state is made.
Discontinued signal line is inheriting that simple signal line idea and it is extending it : instead of having one signal line, more lines depending on the current value of the indicator.
"Signal" line is calculated the following way :
When a certain level is crossed into the desired direction, the EMA of that value is calculated for the desired signal line
When that level is crossed into the opposite direction, the previous "signal" line value is simply "inherited" and it becomes a kind of a level
This way it becomes a combination of signal lines and levels that are trying to combine both the good from both methods.
In simple terms, DSL uses the concept of a signal line and betters it by inheriting the previous signal line's value & makes it a level.
Included:
Bar coloring
Alerts
Signals
Loxx's Expanded Source Types
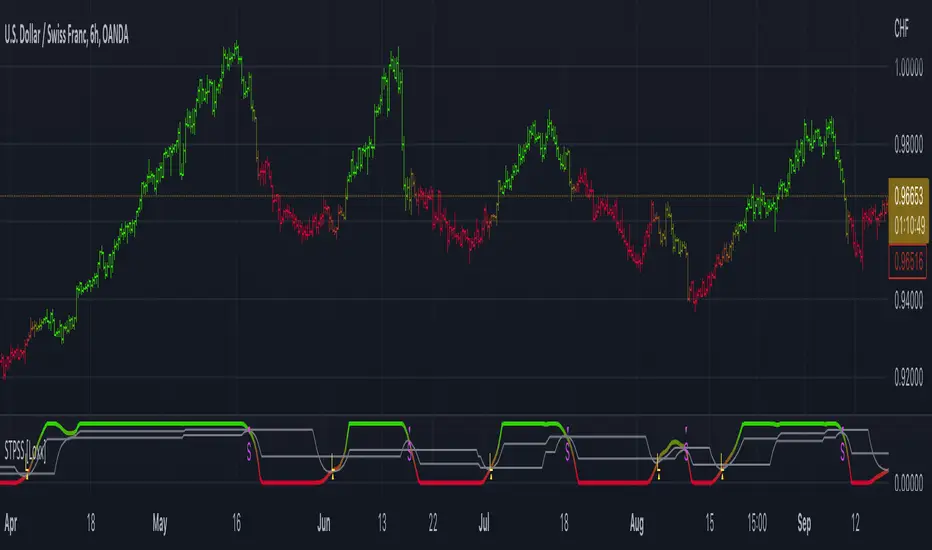
Adaptive Two-Pole Super Smoother Entropy MACD [Loxx]Adaptive Two-Pole Super Smoother Entropy (Math) MACD is an Ehlers Two-Pole Super Smoother that is transformed into an MACD oscillator using entropy mathematics. Signals are generated using Discontinued Signal Lines.
What is Ehlers; Two-Pole Super Smoother?
From "Cycle Analytics for Traders Advanced Technical Trading Concepts" by John F. Ehlers
A SuperSmoother filter is used anytime a moving average of any type would otherwise be used, with the result that the SuperSmoother filter output would have substantially less lag for an equivalent amount of smoothing produced by the moving average. For example, a five-bar SMA has a cutoff period of approximately 10 bars and has two bars of lag. A SuperSmoother filter with a cutoff period of 10 bars has a lag a half bar larger than the two-pole modified Butterworth filter.Therefore, such a SuperSmoother filter has a maximum lag of approximately 1.5 bars and even less lag into the attenuation band of the filter. The differential in lag between moving average and SuperSmoother filter outputs becomes even larger when the cutoff periods are larger.
Market data contain noise, and removal of noise is the reason for using smoothing filters. In fact, market data contain several kinds of noise. I’ll group one kind of noise as systemic, caused by the random events of trades being exercised. A second kind of noise is aliasing noise, caused by the use of sampled data. Aliasing noise is the dominant term in the data for shorter cycle periods.
It is easy to think of market data as being a continuous waveform, but it is not. Using the closing price as representative for that bar constitutes one sample point. It doesn’t matter if you are using an average of the high and low instead of the close, you are still getting one sample per bar. Since sampled data is being used, there are some dSP aspects that must be considered. For example, the shortest analysis period that is possible (without aliasing)2 is a two-bar cycle.This is called the Nyquist frequency, 0.5 cycles per sample.A perfect two-bar sine wave cycle sampled at the peaks becomes a square wave due to sampling. However, sampling at the cycle peaks can- not be guaranteed, and the interference between the sampling frequency and the data frequency creates the aliasing noise.The noise is reduced as the data period is longer. For example, a four-bar cycle means there are four samples per cycle. Because there are more samples, the sampled data are a better replica of the sine wave component. The replica is better yet for an eight-bar data component.The improved fidelity of the sampled data means the aliasing noise is reduced at longer and longer cycle periods.The rate of reduction is 6 dB per octave. My experience is that the systemic noise rarely is more than 10 dB below the level of cyclic information, so that we create two conditions for effective smoothing of aliasing noise:
1. It is difficult to use cycle periods shorter that two octaves below the Nyquist frequency.That is, an eight-bar cycle component has a quantization noise level 12 dB below the noise level at the Nyquist frequency. longer cycle components therefore have a systemic noise level that exceeds the aliasing noise level.
2. A smoothing filter should have sufficient selectivity to reduce aliasing noise below the systemic noise level. Since aliasing noise increases at the rate of 6 dB per octave above a selected filter cutoff frequency and since the SuperSmoother attenuation rate is 12 dB per octave, the Super- Smoother filter is an effective tool to virtually eliminate aliasing noise in the output signal.
What are DSL Discontinued Signal Line?
A lot of indicators are using signal lines in order to determine the trend (or some desired state of the indicator) easier. The idea of the signal line is easy : comparing the value to it's smoothed (slightly lagging) state, the idea of current momentum/state is made.
Discontinued signal line is inheriting that simple signal line idea and it is extending it : instead of having one signal line, more lines depending on the current value of the indicator.
"Signal" line is calculated the following way :
When a certain level is crossed into the desired direction, the EMA of that value is calculated for the desired signal line
When that level is crossed into the opposite direction, the previous "signal" line value is simply "inherited" and it becomes a kind of a level
This way it becomes a combination of signal lines and levels that are trying to combine both the good from both methods.
In simple terms, DSL uses the concept of a signal line and betters it by inheriting the previous signal line's value & makes it a level.
Included:
Bar coloring
Alerts
Signals
Loxx's Expanded Source Types

smoothed_rsi
Description:
A well-known and vastly used momentum indicator, a Relative Strength Index (RSI) by J. Welles Wilder Jr., aims to evaluate the current price to its oversold/overbought area while giving an overview of bearish/bullish momentum. In this indicator, simply adding the super-smoother function (John F. Ehlers) was applied to the RSI line to create a more smoothed line and reduce its noise.
RSI:
RSI = 100 - 100/(1+RS)
RS = AvgUp/AvgDown
super_smoother(rsi)
Notes:
RSI > 70 indicates overbought
RSI < 30 indicates oversold
direction of the RSI line
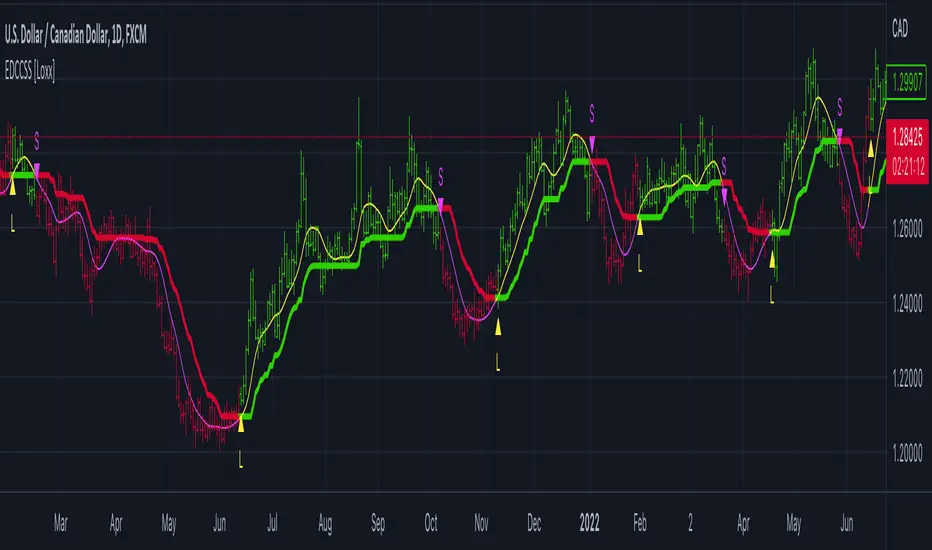
EMA-Deviation-Corrected Super Smoother [Loxx]This indicator is using the modified "correcting" method. Instead of using standard deviation for calculation, it is using EMA deviation and is applied to Ehlers' Super Smoother.
What is EMA-Deviation?
By definition, the Standard Deviation (SD, also represented by the Greek letter sigma σ or the Latin letter s) is a measure that is used to quantify the amount of variation or dispersion of a set of data values. In technical analysis we usually use it to measure the level of current volatility.
Standard Deviation is based on Simple Moving Average calculation for mean value. This version is not doing that. It is, instead, using the properties of EMA to calculate what can be called a new type of deviation, and since it is based on EMA. It is similar to Standard Deviation, but on a first glance you shall notice that it is "faster" than the Standard Deviation and that makes it useful when the speed of reaction to volatility is expected from any code or trading system.
What is Ehlers Super Smoother?
The Super Smoother filter uses John Ehlers’s “Super Smoother” which consists of a a Two-pole Butterworth filter combined with a 2-bar SMA (Simple Moving Average) that suppresses the 22050 Hz Nyquist frequency: A characteristic of a sampler, which converts a continuous function or signal into a discrete sequence.
Things to know
The yellow and fuchsia thin line is the original Super Smoother
The green and red line is the Corrected Super Smoother
When the original Super Smoother crosses above the Corrected Super Smoother line, its a long, when it crosses below, its a short
Included
Alerts
Signals
Bar coloring
One-Sided Gaussian Support & Resistance Rate [Loxx]One-Sided Gaussian Support & Resistance Rate is a mean reversion oscillator much like Fisher Transform. This indicator is built using a one-sided Gaussian filter. If you pair this with Fisher Transform and line up the settings, you'll notice similar outcomes. You'll notice that as the oscillator levels out at around zero or one that this signifies a zone of resistance or support. See here for more details on calculating the OS Gaussian Filter:
Included:
Bar coloring
Signals
Alerts
Ehlers 2-Pole Super Smoothing for smoothing source inputs

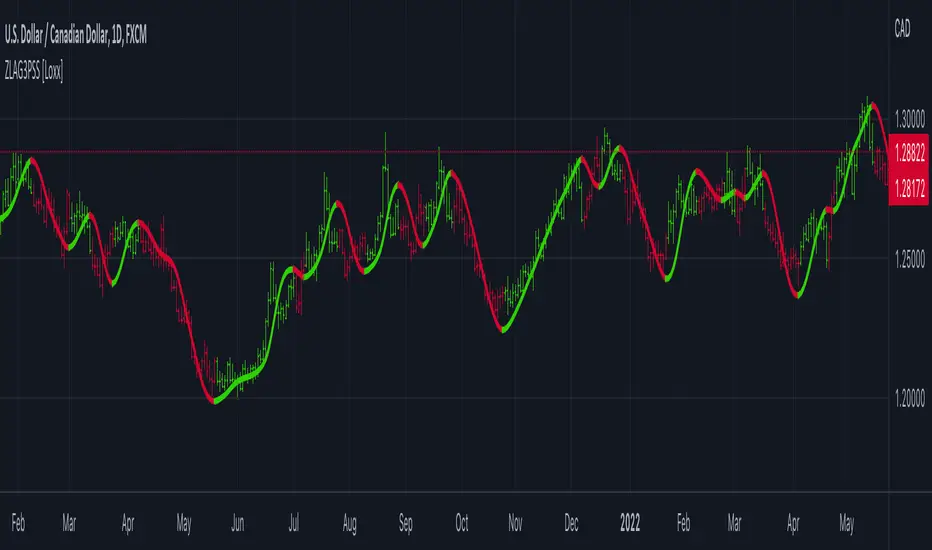
Zero-lag, 3-Pole Super Smoother [Loxx]Zero-lag, 3-Pole Super Smoother is an Ehlers 3-pole smoother with lag reduction
What is 3-pole Super Smoother?
A SuperSmoother filter is used anytime a moving average of any type would otherwise be used, with the result that the SuperSmoother filter output would have substantially less lag for an equivalent amount of smoothing produced by the moving average. For example, a five-bar SMA has a cutoff period of approximately 10 bars and has two bars of lag. A SuperSmoother filter with a cutoff period of 10 bars has a lag a half bar larger than the two-pole modified Butterworth filter. Therefore, such a SuperSmoother filter has a maximum lag of approximately 1.5 bars and even less lag into the attenuation band of the filter. The differential in lag between moving average and SuperSmoother filter outputs becomes even larger when the cutoff periods are larger.
Included:
-Color bars
-Loxx's Expanded Source Types
3-Pole Super Smoother w/ EMA-Deviation-Corrected Stepping [Loxx]3-Pole Super Smoother w/ EMA-Deviation-Corrected Stepping is an Ehlers 3-pole smoother with EMA deviations corrective stepping. This allows for greater response to volatility.
What is 3-pole Super Smoother?
A SuperSmoother filter is used anytime a moving average of any type would otherwise be used, with the result that the SuperSmoother filter output would have substantially less lag for an equivalent amount of smoothing produced by the moving average. For example, a five-bar SMA has a cutoff period of approximately 10 bars and has two bars of lag. A SuperSmoother filter with a cutoff period of 10 bars has a lag a half bar larger than the two-pole modified Butterworth filter. Therefore, such a SuperSmoother filter has a maximum lag of approximately 1.5 bars and even less lag into the attenuation band of the filter. The differential in lag between moving average and SuperSmoother filter outputs becomes even larger when the cutoff periods are larger.
What is EMA Deviation Corrected?
Dr. Alexander Uhl invented a method that he used to filter the moving average and to check for signals.
By definition, the Standard Deviation (SD, also represented by the Greek letter sigma σ or the Latin letter s) is a measure that is used to quantify the amount of variation or dispersion of a set of data values. In technical analysis we usually use it to measure the level of current volatility.
Standard Deviation is based on Simple Moving Average calculation for mean value. The built-in MetaTrader 5 Standard Deviation can change that and can use one of the 4 basic types of averages for calculations. This version is not doing that. It is, instead, using the properties of EMA to calculate what can be called a new type of deviation, and since it is based on EMA, we shall call it EMA deviation.
It is similar to Standard Deviation, but on a first glance you shall notice that it is "faster" than the Standard Deviation and that makes it useful when the speed of reaction to volatility is expected from any code or trading system.
Included:
-Color bars
-Loxx's Expanded Source Types

Relative Strength Super Smoother by lastguruA better version of Apirine's RS EMA by using a superior MA: Ehlers Super Smoother.
In January 2022 edition of TASC Vitaly Apirine introduced his Relative Strength Exponential Moving Average. A concept not entirely new, as Tushar Chande used a similar calculation for his VIDYA moving average. Both are based on the idea to change EMA length depending on the absolute RSI value, so the moving average would speed up then RSI is going up or down from the center value (when there is a significant directional price movement), and slow down when RSI returns to the center value (when there is a neutral or sideways movement). That way EMA responsiveness would increase where it matters most, but decrease where there is a high probability of whipsaw.
There are only two main differences between VIDYA and RS EMA:
RSI internal smoothing - VIDYA uses SMA, as Chande's CMO is an RSI with SMA; RS EMA uses EMA
Change direction - VIDYA sets the fastest length; RS EMA sets the slowest length
Both algorithms use EMA as the base of their calculation. As John F. Ehlers has shown in his article "Predictive and Successful Indicators" (January 2014 issue of TASC), EMA is not a very efficient filter, as it introduces a significant lag if sufficient smoothing is required. He describes a new smoothing filter called SuperSmoother, "that sharply attenuates aliasing noise while minimizing filtering lag." In other words, it provides better smoothing with lower lag than EMA.
In this script, I try to get the best of all these approaches and present to you Relative Strength Super Smoother. It uses RS EMA algorithm to calculate the SuperSmoother length. Unlike the original RS EMA algorithm, that has an abstract "multiplier" setting to scale the period variance (without this parameter, RSI would only allow it to speed up twice; Vitaly Apirine sets the multiplier to 10 by default), my implementation has explicit lower bound setting, so you can specify the exact range of calculated length.
Settings:
Lower Bound - fastest SuperSmoother length (when RSI is +100 or -100)
Upper Bound - slowest SuperSmoother length (when RSI is 0)
RSI Length - underlying RSI length. Unlike the original RSI that uses RMA as an internal smoothing algorithm, Vitaly Apirine uses EMA, which is approximately twice as fast (that is needed because he uses a generally long RSI length and RMA would be too slow for this). It is the same as the Upper Bound by default (0), as in the original implementation
The original RS EMA is also shown on the chart for comparison. The default multiplier of 10 for RS EMA means that the fastest EMA period is around 4. I use the fastest period of 8 by default. It does not introduce too much of a lag in comparison, but the curve is much smoother.
This script is just an interface for my public libraries. Check them out for more information.

[blackcat] L2 Ehlers Super Smoother (3 poles)Level:2
Background
The third-order super smoother low-pass butterworth filter (3 pole) is a classic J.F Ehlers indicator.
Function
I have found many places where the algorithms are not uniform and some are even wrong. So, I did some research and wrote a low pass filter that I think is correctly defined. This indicator is often used as one of the basic elements of other trading systems.
When you are using it, you need to enter the Period setting period.
Remarks
Free but Open Source
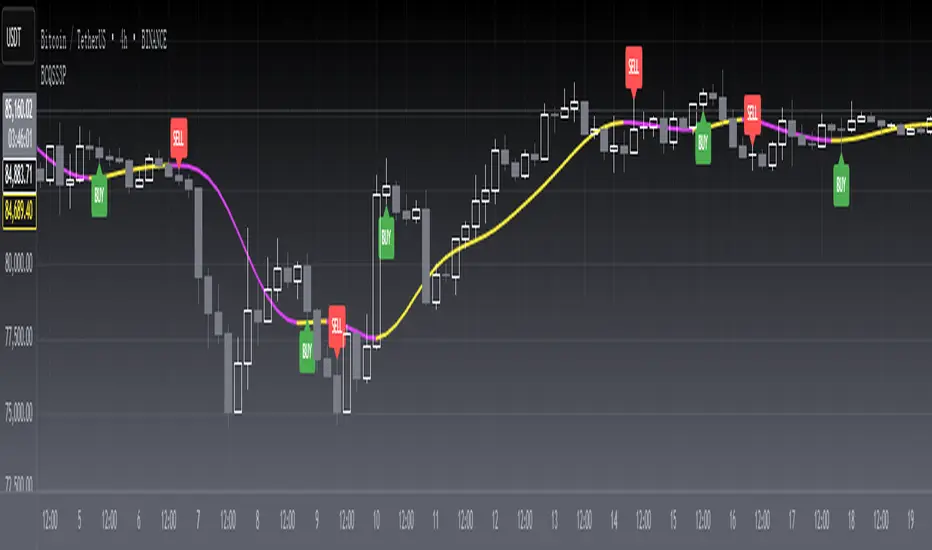
Adaptive MA Difference constructor [lastguru]A complimentary indicator to my Adaptive MA constructor. It calculates the difference between the two MA lines (inspired by the Moving Average Difference (MAD) indicator by John F. Ehlers). You can then further smooth the resulting curve. The parameters and options are explained here:
The difference is normalized by dividing the difference by twice its Root mean square (RMS) over Slow MA length. Inverse Fisher Transform is then used to force the -1..1 range.
Same Postfilter options are provided as in my Adaptive Oscillator constructor:
Stochastic - Stochastic
Super Smooth Stochastic - Super Smooth Stochastic (part of MESA Stochastic ) by John F. Ehlers
Inverse Fisher Transform - Inverse Fisher Transform
Noise Elimination Technology - a simplified Kendall correlation algorithm "Noise Elimination Technology" by John F. Ehlers
Momentum - momentum (derivative)
Except for Inverse Fisher Transform, all Postfilter algorithms can have Length parameter. If it is not specified (set to 0), then the calculated Slow MA Length is used.
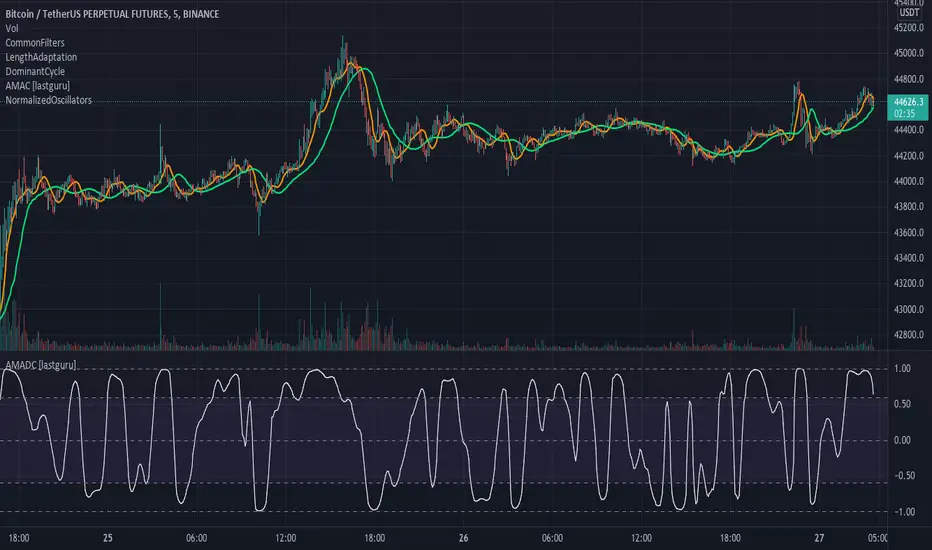
Adaptive MA constructor [lastguru]Adaptive Moving Averages are nothing new, however most of them use EMA as their MA of choice once the preferred smoothing length is determined. I have decided to make an experiment and separate length generation from smoothing, offering multiple alternatives to be combined. Some of the combinations are widely known, some are not. This indicator is based on my previously published public libraries and also serve as a usage demonstration for them. I will try to expand the collection (suggestions are welcome), however it is not meant as an encyclopaedic resource, so you are encouraged to experiment yourself: by looking on the source code of this indicator, I am sure you will see how trivial it is to use the provided libraries and expand them with your own ideas and combinations. I give no recommendation on what settings to use, but if you find some useful setting, combination or application ideas (or bugs in my code), I would be happy to read about them in the comments section.
The indicator works in three stages: Prefiltering, Length Adaptation and Moving Averages.
Prefiltering is a fast smoothing to get rid of high-frequency (2, 3 or 4 bar) noise.
Adaptation algorithms are roughly subdivided in two categories: classic Length Adaptations and Cycle Estimators (they are also implemented in separate libraries), all are selected in Adaptation dropdown. Length Adaptation used in the Adaptive Moving Averages and the Adaptive Oscillators try to follow price movements and accelerate/decelerate accordingly (usually quite rapidly with a huge range). Cycle Estimators, on the other hand, try to measure the cycle period of the current market, which does not reflect price movement or the rate of change (the rate of change may also differ depending on the cycle phase, but the cycle period itself usually changes slowly).
Chande (Price) - based on Chande's Dynamic Momentum Index (CDMI or DYMOI), which is dynamic RSI with this length
Chande (Volume) - a variant of Chande's algorithm, where volume is used instead of price
VIDYA - based on VIDYA algorithm. The period oscillates from the Lower Bound up (slow)
VIDYA-RS - based on Vitali Apirine's modification of VIDYA algorithm (he calls it Relative Strength Moving Average). The period oscillates from the Upper Bound down (fast)
Kaufman Efficiency Scaling - based on Efficiency Ratio calculation originally used in KAMA
Deviation Scaling - based on DSSS by John F. Ehlers
Median Average - based on Median Average Adaptive Filter by John F. Ehlers
Fractal Adaptation - based on FRAMA by John F. Ehlers
MESA MAMA Alpha - based on MESA Adaptive Moving Average by John F. Ehlers
MESA MAMA Cycle - based on MESA Adaptive Moving Average by John F. Ehlers, but unlike Alpha calculation, this adaptation estimates cycle period
Pearson Autocorrelation* - based on Pearson Autocorrelation Periodogram by John F. Ehlers
DFT Cycle* - based on Discrete Fourier Transform Spectrum estimator by John F. Ehlers
Phase Accumulation* - based on Dominant Cycle from Phase Accumulation by John F. Ehlers
Length Adaptation usually take two parameters: Bound From (lower bound) and To (upper bound). These are the limits for Adaptation values. Note that the Cycle Estimators marked with asterisks(*) are very computationally intensive, so the bounds should not be set much higher than 50, otherwise you may receive a timeout error (also, it does not seem to be a useful thing to do, but you may correct me if I'm wrong).
The Cycle Estimators marked with asterisks(*) also have 3 checkboxes: HP (Highpass Filter), SS (Super Smoother) and HW (Hann Window). These enable or disable their internal prefilters, which are recommended by their author - John F. Ehlers. I do not know, which combination works best, so you can experiment.
Chande's Adaptations also have 3 additional parameters: SD Length (lookback length of Standard deviation), Smooth (smoothing length of Standard deviation) and Power (exponent of the length adaptation - lower is smaller variation). These are internal tweaks for the calculation.
Length Adaptaton section offer you a choice of Moving Average algorithms. Most of the Adaptations are originally used with EMA, so this is a good starting point for exploration.
SMA - Simple Moving Average
RMA - Running Moving Average
EMA - Exponential Moving Average
HMA - Hull Moving Average
VWMA - Volume Weighted Moving Average
2-pole Super Smoother - 2-pole Super Smoother by John F. Ehlers
3-pole Super Smoother - 3-pole Super Smoother by John F. Ehlers
Filt11 -a variant of 2-pole Super Smoother with error averaging for zero-lag response by John F. Ehlers
Triangle Window - Triangle Window Filter by John F. Ehlers
Hamming Window - Hamming Window Filter by John F. Ehlers
Hann Window - Hann Window Filter by John F. Ehlers
Lowpass - removes cyclic components shorter than length (Price - Highpass)
DSSS - Derivation Scaled Super Smoother by John F. Ehlers
There are two Moving Averages that are drown on the chart, so length for both needs to be selected. If no Adaptation is selected ( None option), you can set Fast Length and Slow Length directly. If an Adaptation is selected, then Cycle multiplier can be selected for Fast and Slow MA.
More information on the algorithms is given in the code for the libraries used. I am also very grateful to other TradingView community members (they are also mentioned in the library code) without whom this script would not have been possible.

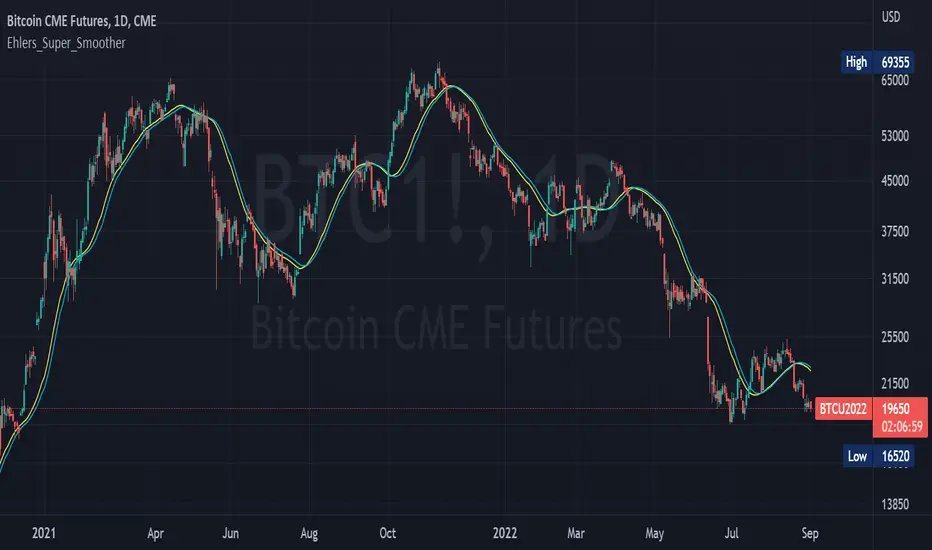
Ehlers_Super_SmootherThe 2 Pole and 3 Pole Super Smoother Filters were developed by John Ehlers and described in "Chapter 13: Super Smother" of his book Cybernetic Analysis for Stocks and Futures .
The 2 Pole Smoother is described as being a better approximation of price, whereas the 3 Pole Smoother has superior smoothing.
Library "Ehlers_Super_Smoother"
Provides the functions to calculate Double and Triple Exponentional Moving Averages (DEMA & TEMA)
twoPole(_source, _length) Calculates 2 Pole Ehlers Super Smoother Filter
Parameters:
_source : -> Open, Close, High, Low, etc ('close' is used if no argument is supplied)
_length : -> Ehlers Super Smoother length
Returns: 2 Pole Ehlers Super Smoothing to an input source at the specified input length
threePole(_source, _length) Calculates 3 Pole Ehlers Super Smoother Filter
Parameters:
_source : -> Open, Close, High, Low, etc ('close' is used if no argument is supplied)
_length : -> Ehlers Super Smoother length
Returns: 3 Pole Ehlers Super Smoothing to an input source at the specified input length
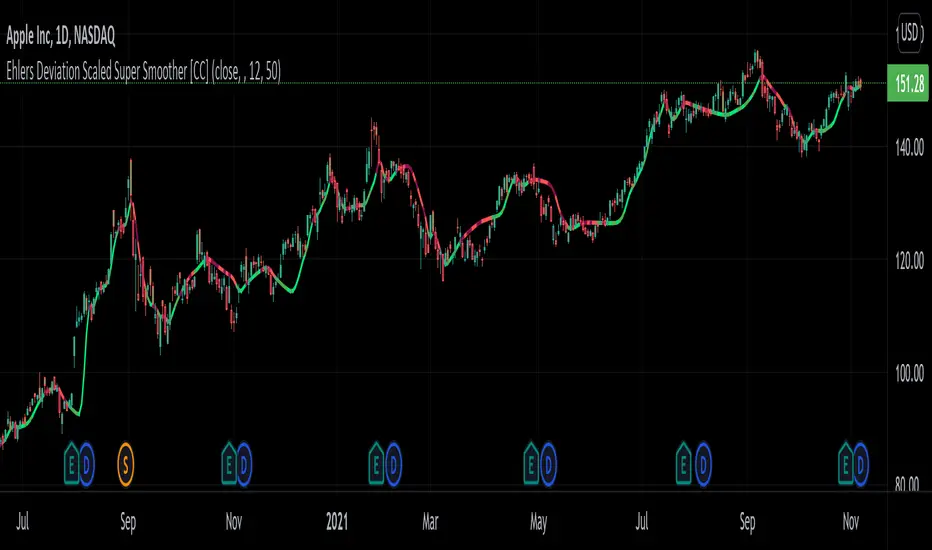
Ehlers Deviation Scaled Super Smoother [CC]The Deviation Scaled Super Smoother was created by John Ehlers and this is an excellent moving average that changes direction very quickly and can keep up with the current underlying trend. This indicator works by applying a Hann Windowed Moving Average to the stock's momentum and scaling that by the Root Mean Square and then using that value in the input for a Super Smoother . I have included strong buy and sell signals in addition to normal ones so lighter colors are normal signals and darker colors are strong ones. Buy when the line turns green and sell when it turns red.
Let me know if there are any other scripts you would like to see me publish!
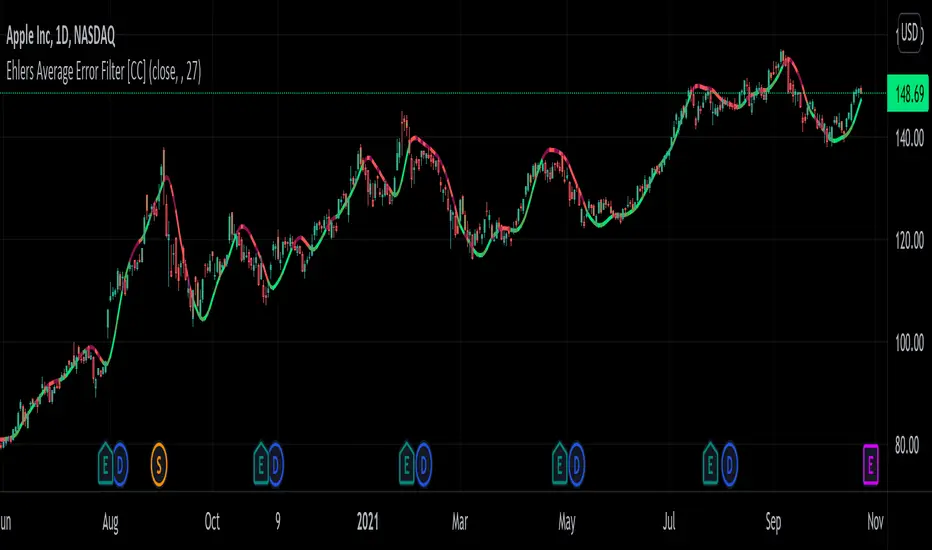
Ehlers Average Error Filter [CC]The Average Error Filter was created by John Ehlers and this is a variation of a Zero Lag Exponential Moving Average that uses a Super Smoother to filter out the noise and then uses a second Super Smoother of the difference between the current price and the filtered data. This works well as a trendline and does give out a few false signals like all indicators inevitably do but most signals do a good job of keeping up with the trend and providing clear entries and exits when the trend changes. I have included strong buy and sell signals in addition to normal ones so like always darker colors are strong signals and lighter colors are normal ones. Buy when the line turns green and sell when it turns red.
Let me know if there are any other scripts you would like to see me publish!
MESA Stochastic Multi LengthJohn Ehler's MESA Stochastic uses super smoothing to give solid signals. This indicator uses the same rules as every other Stochastic indicator so it would be worth looking into if you are not already familiar with reading a Stochastic. There are 4 different lengths displayed to give traders an edge on reading the market. This is a great tool to analyze waves and find tops and bottoms. It gives great pump and dump signals and even helps filter out bad trades when used with other indicators such as Boom Hunter.
Below are some examples of signals to look out for:
oo

[blackcat] L2 Ehlers Super Smoother FilterLevel: 2
Background
John F. Ehlers introuced Super Smoother Filter in Jan, 2014.
Function
In “Predictive And Successful Indicators” in Jan, 2014, John Ehlers describes a new method for smoothing market data while reducing the lag that most other smoothing techniques have. And this is a very popular filter to eliminate noise of market signal.
Key Signal
Filt --> Ehlers Super Smoother Filter fast line
Trigger --> Ehlers Super Smoother Filter slow line
Pros and Cons
100% John F. Ehlers definition translation, even variable names are the same. This help readers who would like to use pine to read his book.
Remarks
The 100th script for Blackcat1402 John F. Ehlers Week publication.
Readme
In real life, I am a prolific inventor. I have successfully applied for more than 60 international and regional patents in the past 12 years. But in the past two years or so, I have tried to transfer my creativity to the development of trading strategies. Tradingview is the ideal platform for me. I am selecting and contributing some of the hundreds of scripts to publish in Tradingview community. Welcome everyone to interact with me to discuss these interesting pine scripts.
The scripts posted are categorized into 5 levels according to my efforts or manhours put into these works.
Level 1 : interesting script snippets or distinctive improvement from classic indicators or strategy. Level 1 scripts can usually appear in more complex indicators as a function module or element.
Level 2 : composite indicator/strategy. By selecting or combining several independent or dependent functions or sub indicators in proper way, the composite script exhibits a resonance phenomenon which can filter out noise or fake trading signal to enhance trading confidence level.
Level 3 : comprehensive indicator/strategy. They are simple trading systems based on my strategies. They are commonly containing several or all of entry signal, close signal, stop loss, take profit, re-entry, risk management, and position sizing techniques. Even some interesting fundamental and mass psychological aspects are incorporated.
Level 4 : script snippets or functions that do not disclose source code. Interesting element that can reveal market laws and work as raw material for indicators and strategies. If you find Level 1~2 scripts are helpful, Level 4 is a private version that took me far more efforts to develop.
Level 5 : indicator/strategy that do not disclose source code. private version of Level 3 script with my accumulated script processing skills or a large number of custom functions. I had a private function library built in past two years. Level 5 scripts use many of them to achieve private trading strategy.

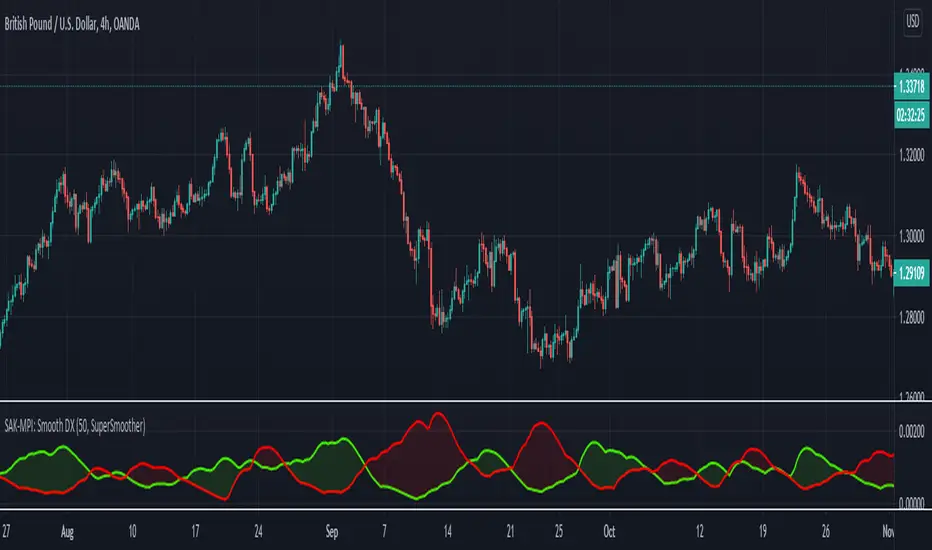
SAK-MPI: Smooth DXDescription : This SwissArmyKnife - MultiPurposeIndicator allows user to modify the Directional index based on one of filtering tools proposed by John F.Ehlers .
Details of each filtering type can be read in Ehlers Technical Papers: "Swiss Army Knife Indicator" and/or his book "Cybernetics Analysis for Stock and Futures"
Disclaimer:
These study scripts was built only to test/visualize an idea to see its viability and if it can be used to optimize existing strategy.
This is experimental indicator. Any ideas to further improve this indicator are welcome :)
[blackcat] L2 Ehlers Super Smooth Stoch StrategyLevel: 2
Background
John F. Ehlers introuced Super Smooth Stochastic Indicator in Jan, 2014.
Function
In “Predictive And Successful Indicators” of in, 2014, John Ehlers presented another innovative way to eliminate noise from classic indicators and introduces some new smoothing indicators: the SuperSmoother filter, which is superior to moving averages for removing aliasing noise, and the MESA Stochastic oscillator, a stochastic successor that removes the effect of spectral dilation through the use of a roofing filter.
John Ehlers described a new method for smoothing market data while reducing the lag that most other smoothing techniques have. Ehlers had provided an approach for creating a strategy. For convenience, I made the same code available at tradingview pine v4 as well as an example strategy based on Ehlers’ description. Ehlers introduced a simple countertrend system that goes long when MESA Stochastic crosses below the oversold value and reverses the trade by taking a short position when the oscillator exceeds the overbought threshold.
Key Signal
MyStochastic --> Super Smooth Stochastic line
long ---> long entry signal
short ---> short entry signal
Pros and Cons
100% John F. Ehlers definition translation, even variable names are the same. This help readers who would like to use pine to read his book.
Remarks
The 81th script for Blackcat1402 John F. Ehlers Week publication.
Readme
In real life, I am a prolific inventor. I have successfully applied for more than 60 international and regional patents in the past 12 years. But in the past two years or so, I have tried to transfer my creativity to the development of trading strategies. Tradingview is the ideal platform for me. I am selecting and contributing some of the hundreds of scripts to publish in Tradingview community. Welcome everyone to interact with me to discuss these interesting pine scripts.
The scripts posted are categorized into 5 levels according to my efforts or manhours put into these works.
Level 1 : interesting script snippets or distinctive improvement from classic indicators or strategy. Level 1 scripts can usually appear in more complex indicators as a function module or element.
Level 2 : composite indicator/strategy. By selecting or combining several independent or dependent functions or sub indicators in proper way, the composite script exhibits a resonance phenomenon which can filter out noise or fake trading signal to enhance trading confidence level.
Level 3 : comprehensive indicator/strategy. They are simple trading systems based on my strategies. They are commonly containing several or all of entry signal, close signal, stop loss, take profit, re-entry, risk management, and position sizing techniques. Even some interesting fundamental and mass psychological aspects are incorporated.
Level 4 : script snippets or functions that do not disclose source code. Interesting element that can reveal market laws and work as raw material for indicators and strategies. If you find Level 1~2 scripts are helpful, Level 4 is a private version that took me far more efforts to develop.
Level 5 : indicator/strategy that do not disclose source code. private version of Level 3 script with my accumulated script processing skills or a large number of custom functions. I had a private function library built in past two years. Level 5 scripts use many of them to achieve private trading strategy.

[blackcat] L2 Ehlers Three Pole Super SmootherLevel: 2
Background
John F. Ehlers introuced Three Pole Super Smoother in his "Cybernetic Analysis for Stocks and Futures" chapter 13 on 2004.
Function
The Super Smoother filter is formed by retaining the IIR part of a Butterworth digital filter. The order of Super Smoother filters can be increased indefinitely to increase the sharpness of the filter rejection, just as with Butterworth filters. A three-pole Super Smoother filter has far more attenuation in the reject band than the two-pole filters
Key Signal
Filt3 ---> Three Pole Super Smoother fast line
Trigger ---> Three Pole Super Smoother slow line
Pros and Cons
100% John F. Ehlers definition translation of original work, even variable names are the same. This help readers who would like to use pine to read his book. If you had read his works, then you will be quite familiar with my code style.
Remarks
The 32th script for Blackcat1402 John F. Ehlers Week publication.
Readme
In real life, I am a prolific inventor. I have successfully applied for more than 60 international and regional patents in the past 12 years. But in the past two years or so, I have tried to transfer my creativity to the development of trading strategies. Tradingview is the ideal platform for me. I am selecting and contributing some of the hundreds of scripts to publish in Tradingview community. Welcome everyone to interact with me to discuss these interesting pine scripts.
The scripts posted are categorized into 5 levels according to my efforts or manhours put into these works.
Level 1 : interesting script snippets or distinctive improvement from classic indicators or strategy. Level 1 scripts can usually appear in more complex indicators as a function module or element.
Level 2 : composite indicator/strategy. By selecting or combining several independent or dependent functions or sub indicators in proper way, the composite script exhibits a resonance phenomenon which can filter out noise or fake trading signal to enhance trading confidence level.
Level 3 : comprehensive indicator/strategy. They are simple trading systems based on my strategies. They are commonly containing several or all of entry signal, close signal, stop loss, take profit, re-entry, risk management, and position sizing techniques. Even some interesting fundamental and mass psychological aspects are incorporated.
Level 4 : script snippets or functions that do not disclose source code. Interesting element that can reveal market laws and work as raw material for indicators and strategies. If you find Level 1~2 scripts are helpful, Level 4 is a private version that took me far more efforts to develop.
Level 5 : indicator/strategy that do not disclose source code. private version of Level 3 script with my accumulated script processing skills or a large number of custom functions. I had a private function library built in past two years. Level 5 scripts use many of them to achieve private trading strategy.