Machine Learning: STDEV Oscillator [YinYangAlgorithms]This Indicator aims to fill a gap within traditional Standard Deviation Analysis. Rather than its usual applications, this Indicator focuses on applying Standard Deviation within an Oscillator and likewise applying a Machine Learning approach to it. By doing so, we may hope to achieve an Adaptive Oscillator which can help display when the price is deviating from its standard movement. This Indicator may help display both when the price is Overbought or Underbought, and likewise, where the price may face Support and Resistance. The reason for this is that rather than simply plotting a Machine Learning Standard Deviation (STDEV), we instead create a High and a Low variant of STDEV, and then use its Highest and Lowest values calculated within another Deviation to create Deviation Zones. These zones may help to display these Support and Resistance locations; and likewise may help to show if the price is Overbought or Oversold based on its placement within these zones. This Oscillator may also help display Momentum when the High and/or Low STDEV crosses the midline (0). Lastly, this Oscillator may also be useful for seeing the spacing between the High and Low of the STDEV; large spacing may represent volatility within the STDEV which may be helpful for seeing when there is Momentum in the form of volatility.
Tutorial:
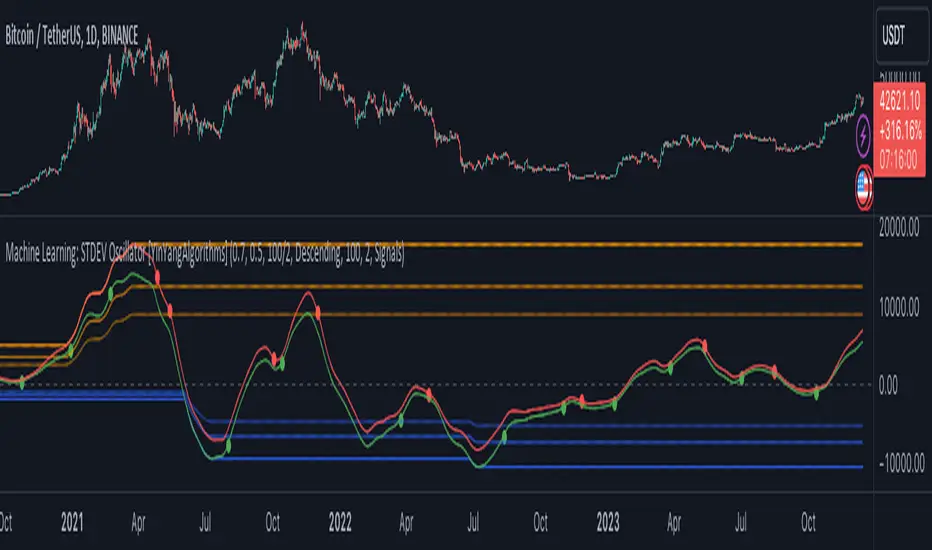
Above is an example of how this Indicator looks on BTC/USDT 1 Day. As you may see, when the price has parabolic movement, so does the STDEV. This is due to this price movement deviating from the mean of the data. Therefore when these parabolic movements occur, we create the Deviation Zones accordingly, in hopes that it may help to project future Support and Resistance locations as well as helping to display when the price is Overbought and Oversold.
If we zoom in a little bit, you may notice that the Support Zone (Blue) is smaller than the Resistance Zone (Orange). This is simply because during the last Bull Market there was more parabolic price deviation than there was during the Bear Market. You may see this if you refer to their values; the Resistance Zone goes to ~18k whereas the Support Zone is ~10.5k. This is completely normal and the way it is supposed to work. Due to the nature of how STDEV works, this Oscillator doesn’t use a 1:1 ratio and instead can develop and expand as exponential price action occurs.
The Neutral (0) line may also act as a Support and Resistance location. In the example above we can see how when the STDEV is below it, it acts as Resistance; and when it’s above it, it acts as Support.
This Neutral line may also provide us with insight as towards the momentum within the market and when it has shifted. When the STDEV is below the Neutral line, the market may be considered Bearish. When the STDEV is above the Neutral line, the market may be considered Bullish.
The Red Line represents the STDEV’s High and the Green Line represents the STDEV’s Low. When the STDEV’s High and Low get tight and close together, this may represent there is currently Low Volatility in the market. Low Volatility may cause consolidation to occur, however it also leaves room for expansion.
However, when the STDEV’s High and Low are quite spaced apart, this may represent High levels of Volatility in the market. This may mean the market is more prone to parabolic movements and expansion.
We will conclude our Tutorial here. Hopefully this has given you some insight into how applying Machine Learning to a High and Low STDEV then creating Deviation Zones based on it may help project when the Momentum of the Market is Bullish or Bearish; likewise when the price is Overbought or Oversold; and lastly where the price may face Support and Resistance in the form of STDEV.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!
AI
Backtest Strategy Optimizer AdapterBacktest Strategy Optimizer Adapter
With this library, you will be able to run one or multiple backtests with different variables (combinations). For example, you can run 100 backtests of Supertrend at once with an increment factor of 0.1. This way, you can easily fetch the most profitable settings and apply them to your strategy.
To get a better understanding of the code, you can check the code below.
Single backtest results
= backtest.results(date_start, date_end, long_entry, long_exit, take_profit_percentage, stop_loss_percentage, atr_length, initial_capital, order_size, commission)
Add backtest results to a table
backtest.table(initial_capital, profit_and_loss, open_balance, winrate, entries, exits, wins, losses, backtest_table_position, backtest_table_margin, backtest_table_transparency, backtest_table_cell_color, backtest_table_title_cell_color, backtest_table_text_color)
Backtest result without chart labels
= backtest.run(date_start, date_end, long_entry, long_exit, take_profit_percentage, stop_loss_percentage, atr_length, initial_capital, order_size, commission)
Backtest result profit
profit = backtest.profit(date_start, date_end, long_entry, long_exit, take_profit_percentage, stop_loss_percentage, atr_length, initial_capital, order_size, commission)
Backtest result winrate
winrate = backtest.winrate(date_start, date_end, long_entry, long_exit, take_profit_percentage, stop_loss_percentage, atr_length, initial_capital, order_size, commission)
Start Date
You can set the start date either by using a timestamp or a number that refers to the number of bars back.
Stop Loss / Take Profit Issue
Unfortunately, I did not manage to achieve 100% accuracy for the take profit and stop loss. The original TradingView backtest can stop at the correct position within a bar using the strategy.exit stop and limit variables. However, it seems unachievable with a crossunder/crossover function in PineScript unless it is calculated on every tick (which would make the backtesting results invalid). So far, I have not found a workaround, and I would be grateful if someone could solve this issue, if it is even possible. If you have any solutions or fixes, please let me know!
Multiple Backtest Results / Optimizer
You can run multiple backtests in a single strategy or indicator, but there are certain requirements for placing the correct code in the right way. To view examples of running multiple backtests, you can refer to the links provided in the updates I posted below. In the samples I have also explained how you can auto-generate code for your backtest strategy.
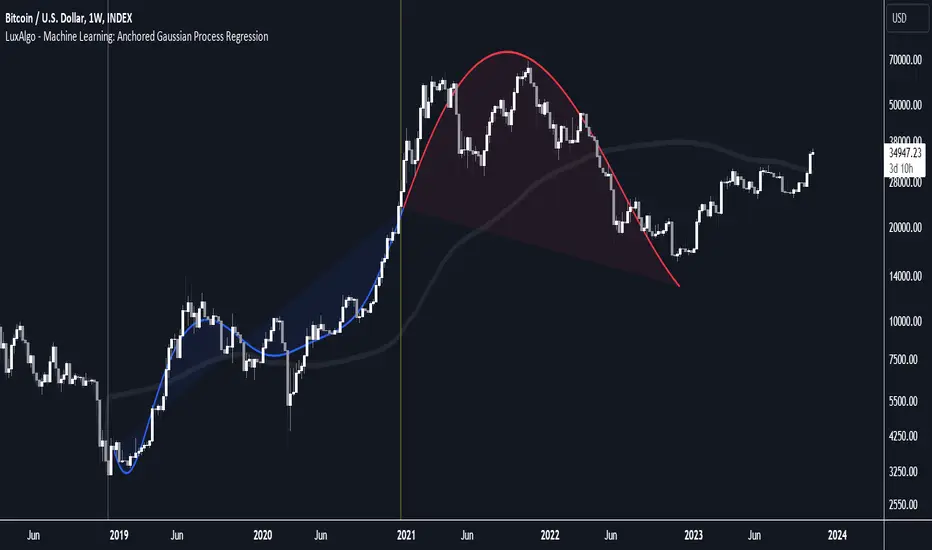
Machine Learning: Anchored Gaussian Process Regression [LuxAlgo]Machine Learning: Anchored Gaussian Process Regression is an anchored version of Machine Learning: Gaussian Process Regression .
It implements Gaussian Process Regression (GPR), a popular machine-learning method capable of estimating underlying trends in prices as well as forecasting them. Users can set a Training Window by choosing 2 points. GPR will be calculated for the data between these 2 points.
Do remember that forecasting trends in the market is challenging, do not use this tool as a standalone for your trading decisions.
🔶 USAGE
When adding the indicator to the chart, users will be prompted to select a starting and ending point for the calculations, click on your chart to select those points.
Start & end point are named 'Anchor 1' & 'Anchor 2', the Training Window is located between these 2 points. Once both points are positioned, the Training Window is set, whereafter the Gaussian Process Regression (GPR) is calculated using data between both Anchors .
The blue line is the GPR fit, the red line is the GPR prediction, derived from data between the Training Window .
Two user settings controlling the trend estimate are available, Smooth and Sigma.
Smooth determines the smoothness of our estimate, with higher values returning smoother results suitable for longer-term trend estimates.
Sigma controls the amplitude of the forecast, with values closer to 0 returning results with a higher amplitude.
One of the advantages of the anchoring process is the ability for the user to evaluate the accuracy of forecasts and further understand how settings affect their accuracy.
The publication also shows the mean average (faint silver line), which indicates the average of the prices within the calculation window (between the anchors). This can be used as a reference point for the forecast, seeing how it deviates from the training window average.
🔶 DETAILS
🔹 Limited Training Window
The Training Window is limited due to matrix.new() limitations in size.
When the 2 points are too far from each other (as in the latter example), the line will end at the maximum limit, without giving a size error.
The red forecasted line is always given priority.
🔹 Positioning Anchors
Typically Anchor 1 is located further in history than Anchor 2 , however, placing Anchor 2 before Anchor 1 is perfectly possibly, and won't give issues.
🔶 SETTINGS
Anchor 1 / Anchor 2: both points will form the Training Window .
Forecasting Length: Forecasting horizon, determines how many bars in the 'future' are forecasted.
Smooth: Controls the degree of smoothness of the model fit.
Sigma: Noise variance. Controls the amplitude of the forecast, lower values will make it more sensitive to outliers.
Machine Learning: VWAP [YinYangAlgorithms]Machine Learning: VWAP aims to use Machine Learning to Identify the best location to Anchor the VWAP at. Rather than using a traditional fixed length or simply adjusting based on a Date / Time; by applying Machine Learning we may hope to identify crucial areas which make sense to reset the VWAP and start anew. VWAP’s may act similar to a Bollinger Band in the sense that they help to identify both Overbought and Oversold Price locations based on previous movements and help to identify how far the price may move within the current Trend. However, unlike Bollinger Bands, VWAPs have the ability to parabolically get quite spaced out and also reset. For this reason, the price may never actually go from the Lower to the Upper and vice versa (when very spaced out; when the Upper and Lower zones are narrow, it may bounce between the two). The reason for this is due to how the anchor location is calculated and in this specific Indicator, how it changes anchors based on price movement calculated within Machine Learning.
This Indicator changes the anchor if the Low < Lowest Low of a length of X and likewise if the High > Highest High of a length of X. This logic is applied within a Machine Learning standpoint that likewise amplifies this Lookback Length by adding a Machine Learning Length to it and increasing the lookback length even further.
Due to how the anchor for this VWAP changes, you may notice that the Basis Line (Orange) may act as a Trend Identifier. When the Price is above the basis line, it may represent a bullish trend; and likewise it may represent a bearish trend when below it. You may also notice what may happen is when the trend occurs, it may push all the way to the Upper or Lower levels of this VWAP. It may then proceed to move horizontally until the VWAP expands more and it may gain more movement; or it may correct back to the Basis Line. If it corrects back to the basis line, what may happen is it either uses the Basis Line as a Support and continues in its current direction, or it will change the VWAP anchor and start anew.
Tutorial:
If we zoom in on the most recent VWAP we can see how it expands. Expansion may be caused by time but generally it may be caused by price movement and volume. Exponential Price movement causes the VWAP to expand, even if there are corrections to it. However, please note Volume adds a large weighted factor to the calculation; hence Volume Weighted Average Price (VWAP).
If you refer to the white circle in the example above; you’ll be able to see that the VWAP expanded even while the price was correcting to the Basis line. This happens due to exponential movement which holds high volume. If you look at the volume below the white circle, you’ll notice it was very large; however even though there was exponential price movement after the white circle, since the volume was low, the VWAP didn’t expand much more than it already had.
There may be times where both Volume and Price movement isn’t significant enough to cause much of an expansion. During this time it may be considered to be in a state of consolidation. While looking at this example, you may also notice the color switch from red to green to red. The color of the VWAP is related to the movement of the Basis line (Orange middle line). When the current basis is > the basis of the previous bar the color of the VWAP is green, and when the current basis is < the basis of the previous bar, the color of the VWAP is red. The color may help you gauge the current directional movement the price is facing within the VWAP.
You may have noticed there are signals within this Indicator. These signals are composed of Green and Red Triangles which represent potential Bullish and Bearish momentum changes. The Momentum changes happen when the Signal Type:
The High/Low or Close (You pick in settings)
Crosses one of the locations within the VWAP.
Bullish Momentum change signals occur when :
Signal Type crosses OVER the Basis
Signal Type crosses OVER the lower level
Bearish Momentum change signals occur when:
Signal Type crosses UNDER the Basis
Signal Type Crosses UNDER the upper level
These signals may represent locations where momentum may occur in the direction of these signals. For these reasons there are also alerts available to be set up for them.
If you refer to the two circles within the example above, you may see that when the close goes above the basis line, how it mat represents bullish momentum. Likewise if it corrects back to the basis and the basis acts as a support, it may continue its bullish momentum back to the upper levels again. However, if you refer to the red circle, you’ll see if the basis fails to act as a support, it may then start to correct all the way to the lower levels, or depending on how expanded the VWAP is, it may just reset its anchor due to such drastic movement.
You also have the ability to disable Machine Learning by setting ‘Machine Learning Type’ to ‘None’. If this is done, it will go off whether you have it set to:
Bullish
Bearish
Neutral
For the type of VWAP you want to see. In this example above we have it set to ‘Bullish’. Non Machine Learning VWAP are still calculated using the same logic of if low < lowest low over length of X and if high > highest high over length of X.
Non Machine Learning VWAP’s change much quicker but may also allow the price to correct from one side to the other without changing VWAP Anchor. They may be useful for breaking up a trend into smaller pieces after momentum may have changed.
Above is an example of how the Non Machine Learning VWAP looks like when in Bearish. As you can see based on if it is Bullish or Bearish is how it favors the trend to be and may likewise dictate when it changes the Anchor.
When set to neutral however, the Anchor may change quite quickly. This results in a still useful VWAP to help dictate possible zones that the price may move within, but they’re also much tighter zones that may not expand the same way.
We will conclude this Tutorial here, hopefully this gives you some insight as to why and how Machine Learning VWAPs may be useful; as well as how to use them.
Settings:
VWAP:
VWAP Type: Type of VWAP. You can favor specific direction changes or let it be Neutral where there is even weight to both. Please note, these do not apply to the Machine Learning VWAP.
Source: VWAP Source. By default VWAP usually uses HLC3; however OHLC4 may help by providing more data.
Lookback Length: The Length of this VWAP when it comes to seeing if the current High > Highest of this length; or if the current Low is < Lowest of this length.
Standard VWAP Multiplier: This multiplier is applied only to the Standard VWMA. This is when 'Machine Learning Type' is set to 'None'.
Machine Learning:
Use Rational Quadratics: Rationalizing our source may be beneficial for usage within ML calculations.
Signal Type: Bullish and Bearish Signals are when the price crosses over/under the basis, as well as the Upper and Lower levels. These may act as indicators to where price movement may occur.
Machine Learning Type: Are we using a Simple ML Average, KNN Mean Average, KNN Exponential Average or None?
KNN Distance Type: We need to check if distance is within the KNN Min/Max distance, which distance checks are we using.
Machine Learning Length: How far back is our Machine Learning going to keep data for.
k-Nearest Neighbour (KNN) Length: How many k-Nearest Neighbours will we account for?
Fast ML Data Length: What is our Fast ML Length? This is used with our Slow Length to create our KNN Distance.
Slow ML Data Length: What is our Slow ML Length? This is used with our Fast Length to create our KNN Distance.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!

Machine Learning: Optimal RSI [YinYangAlgorithms]This Indicator, will rate multiple different lengths of RSIs to determine which RSI to RSI MA cross produced the highest profit within the lookback span. This ‘Optimal RSI’ is then passed back, and if toggled will then be thrown into a Machine Learning calculation. You have the option to Filter RSI and RSI MA’s within the Machine Learning calculation. What this does is, only other Optimal RSI’s which are in the same bullish or bearish direction (is the RSI above or below the RSI MA) will be added to the calculation.
You can either (by default) use a Simple Average; which is essentially just a Mean of all the Optimal RSI’s with a length of Machine Learning. Or, you can opt to use a k-Nearest Neighbour (KNN) calculation which takes a Fast and Slow Speed. We essentially turn the Optimal RSI into a MA with different lengths and then compare the distance between the two within our KNN Function.
RSI may very well be one of the most used Indicators for identifying crucial Overbought and Oversold locations. Not only that but when it crosses its Moving Average (MA) line it may also indicate good locations to Buy and Sell. Many traders simply use the RSI with the standard length (14), however, does that mean this is the best length?
By using the length of the top performing RSI and then applying some Machine Learning logic to it, we hope to create what may be a more accurate, smooth, optimal, RSI.
Tutorial:
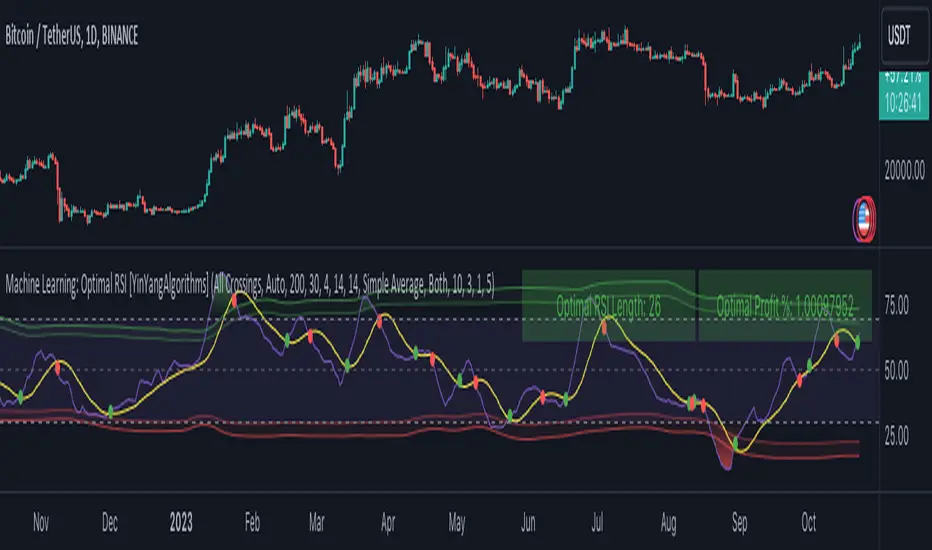
This is a pretty zoomed out Perspective of what the Indicator looks like with its default settings (except with Bollinger Bands and Signals disabled). If you look at the Tables above, you’ll notice, currently the Top Performing RSI Length is 13 with an Optimal Profit % of: 1.00054973. On its default settings, what it does is Scan X amount of RSI Lengths and checks for when the RSI and RSI MA cross each other. It then records the profitability of each cross to identify which length produced the overall highest crossing profitability. Whichever length produces the highest profit is then the RSI length that is used in the plots, until another length takes its place. This may result in what we deem to be the ‘Optimal RSI’ as it is an adaptive RSI which changes based on performance.
In our next example, we changed the ‘Optimal RSI Type’ from ‘All Crossings’ to ‘Extremity Crossings’. If you compare the last two examples to each other, you’ll notice some similarities, but overall they’re quite different. The reason why is, the Optimal RSI is calculated differently. When using ‘All Crossings’ everytime the RSI and RSI MA cross, we evaluate it for profit (short and long). However, with ‘Extremity Crossings’, we only evaluate it when the RSI crosses over the RSI MA and RSI <= 40 or RSI crosses under the RSI MA and RSI >= 60. We conclude the crossing when it crosses back on its opposite of the extremity, and that is how it finds its Optimal RSI.
The way we determine the Optimal RSI is crucial to calculating which length is currently optimal.
In this next example we have zoomed in a bit, and have the full default settings on. Now we have signals (which you can set alerts for), for when the RSI and RSI MA cross (green is bullish and red is bearish). We also have our Optimal RSI Bollinger Bands enabled here too. These bands allow you to see where there may be Support and Resistance within the RSI at levels that aren’t static; such as 30 and 70. The length the RSI Bollinger Bands use is the Optimal RSI Length, allowing it to likewise change in correlation to the Optimal RSI.
In the example above, we’ve zoomed out as far as the Optimal RSI Bollinger Bands go. You’ll notice, the Bollinger Bands may act as Support and Resistance locations within and outside of the RSI Mid zone (30-70). In the next example we will highlight these areas so they may be easier to see.
Circled above, you may see how many times the Optimal RSI faced Support and Resistance locations on the Bollinger Bands. These Bollinger Bands may give a second location for Support and Resistance. The key Support and Resistance may still be the 30/50/70, however the Bollinger Bands allows us to have a more adaptive, moving form of Support and Resistance. This helps to show where it may ‘bounce’ if it surpasses any of the static levels (30/50/70).
Due to the fact that this Indicator may take a long time to execute and it can throw errors for such, we have added a Setting called: Adjust Optimal RSI Lookback and RSI Count. This settings will automatically modify the Optimal RSI Lookback Length and the RSI Count based on the Time Frame you are on and the Bar Indexes that are within. For instance, if we switch to the 1 Hour Time Frame, it will adjust the length from 200->90 and RSI Count from 30->20. If this wasn’t adjusted, the Indicator would Timeout.
You may however, change the Setting ‘Adjust Optimal RSI Lookback and RSI Count’ to ‘Manual’ from ‘Auto’. This will give you control over the ‘Optimal RSI Lookback Length’ and ‘RSI Count’ within the Settings. Please note, it will likely take some “fine tuning” to find working settings without the Indicator timing out, but there are definitely times you can find better settings than our ‘Auto’ will create; especially on higher Time Frames. The Minimum our ‘Auto’ will create is:
Optimal RSI Lookback Length: 90
RSI Count: 20
The Maximum it will create is:
Optimal RSI Lookback Length: 200
RSI Count: 30
If there isn’t much bar index history, for instance, if you’re on the 1 Day and the pair is BTC/USDT you’ll get < 4000 Bar Indexes worth of data. For this reason it is possible to manually increase the settings to say:
Optimal RSI Lookback Length: 500
RSI Count: 50
But, please note, if you make it too high, it may also lead to inaccuracies.
We will conclude our Tutorial here, hopefully this has given you some insight as to how calculating our Optimal RSI and then using it within Machine Learning may create a more adaptive RSI.
Settings:
Optimal RSI:
Show Crossing Signals: Display signals where the RSI and RSI Cross.
Show Tables: Display Information Tables to show information like, Optimal RSI Length, Best Profit, New Optimal RSI Lookback Length and New RSI Count.
Show Bollinger Bands: Show RSI Bollinger Bands. These bands work like the TDI Indicator, except its length changes as it uses the current RSI Optimal Length.
Optimal RSI Type: This is how we calculate our Optimal RSI. Do we use all RSI and RSI MA Crossings or just when it crosses within the Extremities.
Adjust Optimal RSI Lookback and RSI Count: Auto means the script will automatically adjust the Optimal RSI Lookback Length and RSI Count based on the current Time Frame and Bar Index's on chart. This will attempt to stop the script from 'Taking too long to Execute'. Manual means you have full control of the Optimal RSI Lookback Length and RSI Count.
Optimal RSI Lookback Length: How far back are we looking to see which RSI length is optimal? Please note the more bars the lower this needs to be. For instance with BTC/USDT you can use 500 here on 1D but only 200 for 15 Minutes; otherwise it will timeout.
RSI Count: How many lengths are we checking? For instance, if our 'RSI Minimum Length' is 4 and this is 30, the valid RSI lengths we check is 4-34.
RSI Minimum Length: What is the RSI length we start our scans at? We are capped with RSI Count otherwise it will cause the Indicator to timeout, so we don't want to waste any processing power on irrelevant lengths.
RSI MA Length: What length are we using to calculate the optimal RSI cross' and likewise plot our RSI MA with?
Extremity Crossings RSI Backup Length: When there is no Optimal RSI (if using Extremity Crossings), which RSI should we use instead?
Machine Learning:
Use Rational Quadratics: Rationalizing our Close may be beneficial for usage within ML calculations.
Filter RSI and RSI MA: Should we filter the RSI's before usage in ML calculations? Essentially should we only use RSI data that are of the same type as our Optimal RSI? For instance if our Optimal RSI is Bullish (RSI > RSI MA), should we only use ML RSI's that are likewise bullish?
Machine Learning Type: Are we using a Simple ML Average, KNN Mean Average, KNN Exponential Average or None?
KNN Distance Type: We need to check if distance is within the KNN Min/Max distance, which distance checks are we using.
Machine Learning Length: How far back is our Machine Learning going to keep data for.
k-Nearest Neighbour (KNN) Length: How many k-Nearest Neighbours will we account for?
Fast ML Data Length: What is our Fast ML Length? This is used with our Slow Length to create our KNN Distance.
Slow ML Data Length: What is our Slow ML Length? This is used with our Fast Length to create our KNN Distance.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!
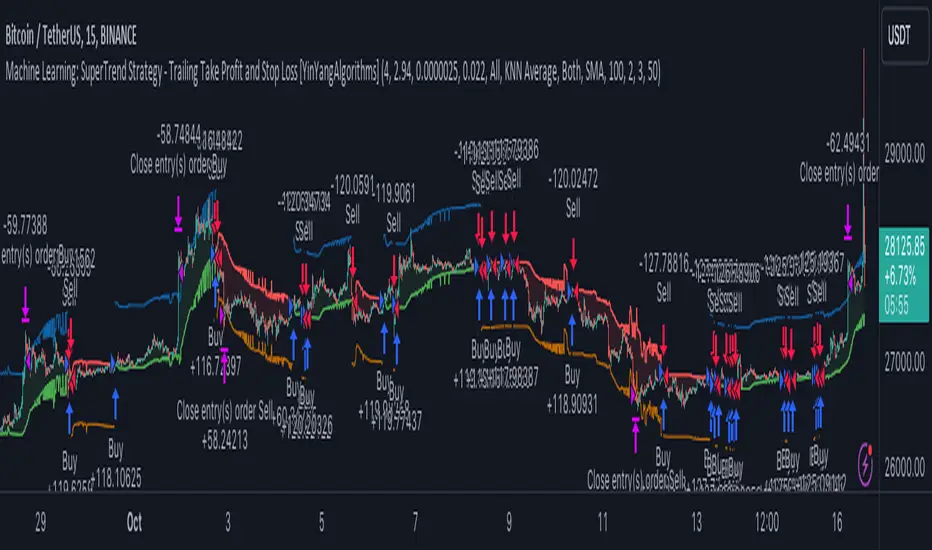
Machine Learning: SuperTrend Strategy TP/SL [YinYangAlgorithms]The SuperTrend is a very useful Indicator to display when trends have shifted based on the Average True Range (ATR). Its underlying ideology is to calculate the ATR using a fixed length and then multiply it by a factor to calculate the SuperTrend +/-. When the close crosses the SuperTrend it changes direction.
This Strategy features the Traditional SuperTrend Calculations with Machine Learning (ML) and Take Profit / Stop Loss applied to it. Using ML on the SuperTrend allows for the ability to sort data from previous SuperTrend calculations. We can filter the data so only previous SuperTrends that follow the same direction and are within the distance bounds of our k-Nearest Neighbour (KNN) will be added and then averaged. This average can either be achieved using a Mean or with an Exponential calculation which puts added weight on the initial source. Take Profits and Stop Losses are then added to the ML SuperTrend so it may capitalize on Momentum changes meanwhile remaining in the Trend during consolidation.
By applying Machine Learning logic and adding a Take Profit and Stop Loss to the Traditional SuperTrend, we may enhance its underlying calculations with potential to withhold the trend better. The main purpose of this Strategy is to minimize losses and false trend changes while maximizing gains. This may be achieved by quick reversals of trends where strategic small losses are taken before a large trend occurs with hopes of potentially occurring large gain. Due to this logic, the Win/Loss ratio of this Strategy may be quite poor as it may take many small marginal losses where there is consolidation. However, it may also take large gains and capitalize on strong momentum movements.
Tutorial:
In this example above, we can get an idea of what the default settings may achieve when there is momentum. It focuses on attempting to hit the Trailing Take Profit which moves in accord with the SuperTrend just with a multiplier added. When momentum occurs it helps push the SuperTrend within it, which on its own may act as a smaller Trailing Take Profit of its own accord.
We’ve highlighted some key points from the last example to better emphasize how it works. As you can see, the White Circle is where profit was taken from the ML SuperTrend simply from it attempting to switch to a Bullish (Buy) Trend. However, that was rejected almost immediately and we went back to our Bearish (Sell) Trend that ended up resulting in our Take Profit being hit (Yellow Circle). This Strategy aims to not only capitalize on the small profits from SuperTrend to SuperTrend but to also capitalize when the Momentum is so strong that the price moves X% away from the SuperTrend and is able to hit the Take Profit location. This Take Profit addition to this Strategy is crucial as momentum may change state shortly after such drastic price movements; and if we were to simply wait for it to come back to the SuperTrend, we may lose out on lots of potential profit.
If you refer to the Yellow Circle in this example, you’ll notice what was talked about in the Summary/Overview above. During periods of consolidation when there is little momentum and price movement and we don’t have any Stop Loss activated, you may see ‘Signal Flashing’. Signal Flashing is when there are Buy and Sell signals that keep switching back and forth. During this time you may be taking small losses. This is a normal part of this Strategy. When a signal has finally been confirmed by Momentum, is when this Strategy shines and may produce the profit you desire.
You may be wondering, what causes these jagged like patterns in the SuperTrend? It's due to the ML logic, and it may be a little confusing, but essentially what is happening is the Fast Moving SuperTrend and the Slow Moving SuperTrend are creating KNN Min and Max distances that are extreme due to (usually) parabolic movement. This causes fewer values to be added to and averaged within the ML and causes less smooth and more exponential drastic movements. This is completely normal, and one of the perks of using k-Nearest Neighbor for ML calculations. If you don’t know, the Min and Max Distance allowed is derived from the most recent(0 index of data array) to KNN Length. So only SuperTrend values that exhibit distances within these Min/Max will be allowed into the average.
Since the KNN ML logic can cause these exponential movements in the SuperTrend, they likewise affect its Take Profit. The Take Profit may benefit from this movement like displayed in the example above which helped it claim profit before then exhibiting upwards movement.
By default our Stop Loss Multiplier is kept quite low at 0.0000025. Keeping it low may help to reduce some Signal Flashing while not taking extra losses more so than not using it at all. However, if we increase it even more to say 0.005 like is shown in the example above. It can really help the trend keep momentum. Please note, although previous results don’t imply future results, at 0.0000025 Stop Loss we are currently exhibiting 69.27% profit while at 0.005 Stop Loss we are exhibiting 33.54% profit. This just goes to show that although there may be less Signal Flashing, it may not result in more profit.
We will conclude our Tutorial here. Hopefully this has given you some insight as to how Machine Learning, combined with Trailing Take Profit and Stop Loss may have positive effects on the SuperTrend when turned into a Strategy.
Settings:
SuperTrend:
ATR Length: ATR Length used to create the Original Supertrend.
Factor: Multiplier used to create the Original Supertrend.
Stop Loss Multiplier: 0 = Don't use Stop Loss. Stop loss can be useful for helping to prevent false signals but also may result in more loss when hit and less profit when switching trends.
Take Profit Multiplier: Take Profits can be useful within the Supertrend Strategy to stop the price reverting all the way to the Stop Loss once it's been profitable.
Machine Learning:
Only Factor Same Trend Direction: Very useful for ensuring that data used in KNN is not manipulated by different SuperTrend Directional data. Please note, it doesn't affect KNN Exponential.
Rationalized Source Type: Should we Rationalize only a specific source, All or None?
Machine Learning Type: Are we using a Simple ML Average, KNN Mean Average, KNN Exponential Average or None?
Machine Learning Smoothing Type: How should we smooth our Fast and Slow ML Datas to be used in our KNN Distance calculation? SMA, EMA or VWMA?
KNN Distance Type: We need to check if distance is within the KNN Min/Max distance, which distance checks are we using.
Machine Learning Length: How far back is our Machine Learning going to keep data for.
k-Nearest Neighbour (KNN) Length: How many k-Nearest Neighbours will we account for?
Fast ML Data Length: What is our Fast ML Length?? This is used with our Slow Length to create our KNN Distance.
Slow ML Data Length: What is our Slow ML Length?? This is used with our Fast Length to create our KNN Distance.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!
Machine Learning using Neural Networks | EducationalThe script provided is a comprehensive illustration of how to implement and execute a simplistic Neural Network (NN) on TradingView using PineScript.
It encompasses the entire workflow from data input, weight initialization, implicit neuron calculation, feedforward computation, backpropagation for weight adjustments, generating predictions, to visualizing the Mean Squared Error (MSE) Loss Curve for monitoring the training phase.
In the visual example above, you can see that the prediction is not aligned with the actual value. This is intentional for demonstrative purposes, and by incrementing the Epochs or Learning Rate, you will see these two values converge as the accuracy increases.
Hyperparameters:
Learning Rate, Epochs, and the choice between Simple Backpropagation and a verbose version are declared as script inputs, allowing users to tailor the training process.
Initialization:
Random initialization of weight matrices (w1, w2) is performed to ensure asymmetry, promoting effective gradient updates. A seed is added for reproducibility.
Utility Functions:
Functions for matrix randomization, sigmoid activation, MSE loss calculation, data normalization, and standardization are defined to streamline the computation process.
Neural Network Computation:
The feedforward function computes the hidden and output layer values given the input.
Two variants of the backpropagation function are provided for weight adjustment, with one offering a more verbose step-by-step computation of gradients.
A wrapper train_nn function iterates through epochs, performing feedforward, loss computation, and backpropagation in each epoch while logging and collecting loss values.
Training Invocation:
The input data is prepared by normalizing it to a value between 0 and 1 using the maximum standardized value, and the training process is invoked only on the last confirmed bar to preserve computational resources.
Output Forecasting and Visualization:
Post training, the NN's output (predicted price) is computed, standardized and visualized alongside the actual price on the chart.
The MSE loss between the predicted and actual prices is visualized, providing insight into the prediction accuracy.
Optionally, the MSE Loss Curve is plotted on the chart, illustrating the loss trajectory through epochs, assisting in understanding the training performance.
Customizable Visualization:
Various inputs control visualization aspects like Chart Scaling, Chart Horizontal Offset, and Chart Vertical Offset, allowing users to adapt the visualization to their preference.
-------------------------------------------------------
The following is this Neural Network structure, consisting of one hidden layer, with two hidden neurons.
Through understanding the steps outlined in my code, one should be able to scale the NN in any way they like, such as changing the input / output data and layers to fit their strategy ideas.
Additionally, one could forgo the backpropagation function, and load their own trained weights into the w1 and w2 matrices, to have this code run purely for inference.
-------------------------------------------------------
While this demonstration does create a “prediction”, it is on historical data. The purpose here is educational, rather than providing a ready tool for non-programmer consumers.
Normally in Machine Learning projects, the training process would be split into two segments, the Training and the Validation parts. For the purpose of conveying the core concept in a concise and non-repetitive way, I have foregone the Validation part. However, it is merely the application of your trained network on new data (feedforward), and monitoring the loss curve.
Essentially, checking the accuracy on “unseen” data, while training it on “seen” data.
-------------------------------------------------------
I hope that this code will help developers create interesting machine learning applications within the Tradingview ecosystem.

Machine Learning: Trend Lines [YinYangAlgorithms]Trend lines have always been a key indicator that may help predict many different types of price movements. They have been well known to create different types of formations such as: Pennants, Channels, Flags and Wedges. The type of formation they create is based on how the formation was created and the angle it was created. For instance, if there was a strong price increase and then there is a Wedge where both end points meet, this is considered a Bull Pennant. The formations Trend Lines create may be powerful tools that can help predict current Support and Resistance and also Future Momentum changes. However, not all Trend Lines will create formations, and alone they may stand as strong Support and Resistance locations on the Vertical.
The purpose of this Indicator is to apply Machine Learning logic to a Traditional Trend Line Calculation, and therefore allowing a new approach to a modern indicator of high usage. The results of such are quite interesting and goes to show the impacts a simple KNN Machine Learning model can have on Traditional Indicators.
Tutorial:
There are a few different settings within this Indicator. Many will greatly impact the results and if any are changed, lots will need ‘Fine Tuning’. So let's discuss the main toggles that have great effects and what they do before discussing the lengths. Currently in this example above we have the Indicator at its Default Settings. In this example, you can see how the Trend Lines act as key Support and Resistance locations. Due note, Support and Resistance are a relative term, as is their color. What starts off as Support or Resistance may change when the price crosses over / under them.
In the example above we have zoomed in and circled locations that exhibited markers of Support and Resistance along the Trend Lines. These Trend Lines are all created using the Default Settings. As you can see from the example above; just because it is a Green Upwards Trend Line, doesn’t mean it’s a Support Line. Support and Resistance is always shifting on Trend Lines based on the prices location relative to them.
We won’t go through all the Formations Trend Lines make, but the example above, we can see the Trend Lines formed a Downward Channel. Channels are when there are two parallel downwards Trend Lines that are at a relatively similar angle. This means that they won’t ever meet. What may happen when the price is within these channels, is it may bounce between the upper and lower bounds. These Channels may drive the price upwards or downwards, depending on if it is in an Upwards or Downwards Channel.
If you refer to the example above, you’ll notice that the Trend Lines are formed like traditional Trend Lines. They don’t stem from current Highs and Lows but rather Machine Learning Highs and Lows. More often than not, the Machine Learning approach to Trend Lines cause their start point and angle to be quite different than a Traditional Trend Line. Due to this, it may help predict Support and Resistance locations at are more uncommon and therefore can be quite useful.
In the example above we have turned off the toggle in Settings ‘Use Exponential Data Average’. This Settings uses a custom Exponential Data Average of the KNN rather than simply averaging the KNN. By Default it is enabled, but as you can see when it is disabled it may create some pretty strong lasting Trend Lines. This is why we advise you ZOOM OUT AS FAR AS YOU CAN. Trend Lines are only displayed when you’ve zoomed out far enough that their Start Point is visible.
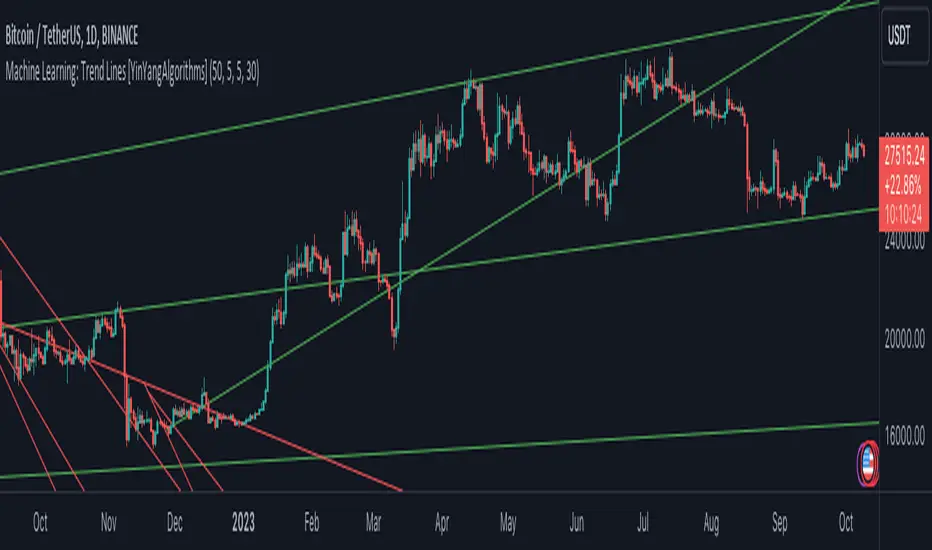
As you can see in this example above, there were 3 major Upward Trend Lines created in 2020 that have had a major impact on Support and Resistance Locations within the last year. Lets zoom in and get a closer look.
We have zoomed in for this example above, and circled some of the major Support and Resistance locations that these Upward Trend Lines may have had a major impact on.
Please note, these Machine Learning Trend Lines aren’t a ‘One Size Fits All’ kind of thing. They are completely customizable within the Settings, so that you can get a tailored experience based on what Pair and Time Frame you are trading on.
When any values are changed within the Settings, you’ll likely need to ‘Fine Tune’ the rest of the settings until your desired result is met. By default the modifiable lengths within the Settings are:
Machine Learning Length: 50
KNN Length:5
Fast ML Data Length: 5
Slow ML Data Length: 30
For example, let's toggle ‘Use Exponential Data Averages’ back on and change ‘Fast ML Data Length’ from 5 to 20 and ‘Slow ML Data Length’ from 30 to 50.
As you can in the example above, all of the lines have changed. Although there are still some strong Support Locations created by the Upwards Trend Lines.
We will conclude our Tutorial here. Hopefully you’ve learned how to use Machine Learning Trend Lines and will be able to now see some more unorthodox Support and Resistance locations on the Vertical.
Settings:
Use Machine Learning Sources: If disabled Traditional Trend line sources (High and Low) will be used rather than Rational Quadratics.
Use KNN Distance Sorting: You can disable this if you wish to not have the Machine Learning Data sorted using KNN. If disabled trend line logic will be Traditional.
Use Exponential Data Average: This Settings uses a custom Exponential Data Average of the KNN rather than simply averaging the KNN.
Machine Learning Length: How strong is our Machine Learning Memory? Please note, when this value is too high the data is almost 'too' much and can lead to poor results.
K-Nearest Neighbour (KNN) Length: How many K-Nearest Neighbours are allowed with our Distance Clustering? Please note, too high or too low may lead to poor results.
Fast ML Data Length: Fast and Slow speed needs to be adjusted properly to see results. 3/5/7 all seem to work well for Fast.
Slow ML Data Length: Fast and Slow speed needs to be adjusted properly to see results. 20 - 50 all seem to work well for Slow.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!
Machine Learning: MFI Heat Map [YinYangAlgorithms]Overview:
MFI Heat Maps are a visually appealing way to display the values of 29 different MFIs at the same time while being able to make sense of it. Each plot within the Indicator represents a different MFI value. The higher you get up, the longer the length that was used for this MFI. This Indicator also features the use of Machine Learning to help balance the MFI levels. It doesn’t solely rely upon Machine Learning but instead incorporates a growing length MFI averaged with the Machine Learning MFI at any given index.
For instance, say we are calculating the 10th plot from the bottom, the MFI would be an average of:
MFI(source, 11)
Machine Learning MFI at Index of 10
We do it this way as they both help smooth each other out without relying solely on just one calculation method.
Due to plot limitations, you are capped at 28 Plot Amounts within this indicator, but that is still quite a bit of information you can glean from a Heat Map.
The Machine Learning used in this indicator is of the K-Nearest Neighbor (KNN). It uses a Fast and Slow MFI calculation then sorts through them over Machine Learning Length and calculates the differences between them. It then slices off KNN length to create our Max/Min Distances allotted. It adds the average between Fast and Slow MFIs to a Viable Distances array if their distances are within the KNN Min/Max distance. It then averages all distances in the Viable Distances array and returns the result.
The result of the KNN Function is saved to another ML Data array whose length is that of Plot Amount (Heat Map Size). This way each Index of the ML Data array can be indexed according to the Heat Map Size.
The Average of the ML Data array is the MFI line (white) that you’ll see plotted on the Indicator. There is also the SMA of the MFI Average (orange) which is likewise plotted. These plots allow you to visualize where the ML MFI is sitting and can potentially be useful for seeing when the MFI Average and SMA cross over and under each other.
We’ve heard many people talk highly of RSI, but sadly not too many even refer to MFI. MFI oftentimes may be overlooked, especially with new traders who may not even know what it is. Essentially MFI is an RSI but it also incorporates Volume into its calculations, which in our opinion leads to a more accurate reading; afterall, what is price movement without Volume.
Tutorial:
You may be thinking, this Indicator looks appealing to the eye, but how do I benefit from it trading wise?
Before we get into our visual examples, let's talk briefly about what makes Heat Maps in general a useful tool for trading. Heat Maps give us the ability to visualize and understand lots of data while removing the clutter. We can understand the data of 29 different MFIs without having to look at and decipher 29 different MFI plots. When you overlay too many MFI lines on top of each other, they can be very difficult to read and oftentimes end up actually hindering your Technical Analysis. For this reason, we have a simple solution to this problem; Heat Maps. This MFI Heat Map allows you to easily know (in a relative %) what the MFI level is for varying lengths. For Instance, the First (bottom) plot indexes an MFI of (K(0) (loop of Plot Amount) + Smoothing Length (default 1)) = 1. Since this is indexing (usually) a very low length, it will change much quicker. Whereas the Last (top) plot indexes an MFI of (K(27) (loop of Plot Amount) + Smoothing Length (default 1)) = 28. This is indexing a much higher length of MFI which results in the MFI the higher you go up in the Heat Map to move much slower.
Heat Maps give us the ability to see changes happening over multiple MFIs at the same time, which can be very useful for seeing shifts in MFI / Momentum. Remember, MFI incorporates Volume, so even if the price goes up a lot, if there was low volume, the MFI won’t move as much as an RSI would. However, likewise, if there is high volume but low price movement, the MFI will move slightly more than the RSI.
Heat Maps change color based on their MFI level. If the MFI is >= 90 it is HOT (red), if the MFI <= 9 it is COLD (teal, think of ICE). Green represents an MFI of 50-59 and Dark Blue represents an MFI of 40-49. Green and Dark blue are the most common colors as all the others are more ‘Extreme’ MFI levels.
Okay, time to get to the Examples :
Since there is so much going on in Heat Maps, we’ve decided to focus this tutorial to this specific area and talk about individual locations before talking about it as a whole.
If you refer to the example above where there are 2 white circles; these white circles are highlighting a key location you’ll be wanting to identify within your Heat Maps, many things are happening here:
The MFI crossed over the SMA (bullish).
The Heat Map started changing from mid/dark Blue (30-50 MFI) to Green (50-59 MFI) around the midline (the 50% dashed like).
The Lower levels of the Heat Map are turning Yellow/Orange/Red (60-100 MFI).
The Upper Levels of the Heat Map are still Light Blue - Green (10-50 MFI).
The 4 Key points above, all point towards potential Bullish Momentum changes. You’re likely wondering, but why? Let's discuss about each one in more specific detail:
1. The MFI crossed over the SMA (bullish): What this tells us is that the current MFI Average is now greater than its average over the last (default) 16 bars. This means there's been a large amount of Money Flow (Price and Volume) recently (subjectively based on the last (default) 16 average). This is one of the leading Bullish / Bearish signals you will see within this Indicator. You can enable Signals within the Settings and/or even add Alerts for when these crossings occur.
2. The Heat Map started changing from mid/dark Blue (30-50 MFI) to Green (50-59 MFI) around the midline (the 50% dashed like): This shows us that the index’s in the mid (if using all 28 heat map plots it would be at 14) has already received some of this momentum change. If you look at the second white circle (right), you’ll also notice the higher MFI plot indexes are also green. This is because since their length is long they still have some momentum and strength from the first white circle (left). Just because the first white circle failed in its bullish push, doesn’t mean it didn’t achieve momentum that would later on help to push the price up.
3. The Lower levels of the Heat Map are turning Yellow/Orange/Red (60-100 MFI): It occurred somewhat in the left white circle, but mainly in the right white circle. This shows us the MFI is very high on the lower lengths, this may lead to the current, middle and higher length MFIs following suit soon. Remember it has to work its way up, the higher levels can’t go red unless the lower levels go red first and the higher levels can also lag quite a bit behind and take awhile to catch up, this is normal, expected and meant to happen. Vice versa is also true with getting higher levels to go cold (light teal (think of ICE)).
4. The Upper Levels of the Heat Map are still Light Blue - Green (10-50 MFI): You might think at first that this is a bad thing, but it's not! Remember you want to be Fearful when others are Greedy and Greedy when others are Fearful! You don’t want to buy when the higher levels have a high MFI, you want to buy when you see the momentum pushing up in the lower MFI levels (getting yellow/orange/red in the low levels) while it is still Cold in the higher levels (BLUE OR GREEN, nothing higher than green as it is already slightly too high). There will be many times that it is Yellow or possibly Orange in the high levels and the bullish push still happens, but this is much more risky! The key to trading is to minimize risks while maximizing potential.
Hopefully now you’re getting an idea of how to spot potential bullish momentum changes, but what about bearish momentum changes? Technically they are the exact opposite, so we don’t need to go into as much detail, but lets still take a look at a few examples:
In the example above we marked the 3 times where it was displaying overly bullish characteristics. We marked the bullish momentum occurring with arrows. If you look closely at the start of the arrow to where it finishes, you’ll notice how the heat (HOT)(RED) works its way up from the lower levels to the higher levels. We then see the MFI to SMA cross under. In all 3 of these examples the heat made it all the way to the top of the chart. These are all very bearish signals that represent a bearish momentum movement that may occur soon.
Also, please note, the level the MFI is at DOES matter! That line isn’t there simply for you to see when there are crosses over and under. The MFI is considered to be Overbought when it is greater than 70 (the upper white dashed line, it is just formatted to be on a different scale cause there are 28 plots, but it represents 70). The MFI is considered to be Oversold when it is less than 30 (the lower white dashed line).
If we look to the left a little here where a big drop in price occurred shortly after our MFI and SMA crossed, would we have been able to identify it using the Heat Maps? Likely, No. There was some color change in the lower levels a few bars prior that went yellow/orange/red but before this cross happened they all went back to Dark Blue. In the middle section when the cross happened it was only Green and Yellow and in the upper section we are Blue. This would be a very risky trade to go on as the only real Bearish Indication was the MFI to SMA cross under. Remember, you want to reduce risk, you don’t want to simply trade on everytime the MFI and SMA cross each other or you’ll be getting yourself into many risky trades based on false signals.
Based on what you’ve learned above, can you see the signs that are indicating where this white circle may have potential for a bullish momentum change?
Now that we are more zoomed in, you may also be noticing there are colors to the price bars. This can be disabled in the settings, but just so you know what they mean, let’s zoom in a little more and talk about it.
We’ve condensed the Indicator a bit so you can see the bars better here. The colors that are displayed on these bars are the Heat Map value for your MFI (the white line in the Indicator). This way you can better see when the Price is Hot and Cold. As you may see while looking, the colors generally go from cold to hot when bullish momentum is happening and hot to cold when bearish momentum is happening. We don’t recommend solely looking at the bars as indicators to MFI momentum change, as seeing the Heat Map will give you much more data; however it can be nice to see the Heat Map projected on the bars rather than trying to eyeball it yourself or hover over each bar specifically to see their levels.
We will conclude our Tutorial here. Hopefully this has given you some insight to how useful Heat Maps can be and why it works well with a Machine Learning (KNN) Model applied to the MFI.
PLEASE NOTE: You can adjust the line width for the Heat Map within the settings. If you condense the Indicator a lot or have a small screen, likely use a length of 1-2. If you have it stretched out or a large screen, a length of 2-3 will work nice. You just don’t want to have the lines overlapping or it defeats the purpose of a Heat Map. Also, the bigger the linewidth, generally you’ll want to increase the Transparency within the Settings also as it can get quite bright and hurt your eyes over time.
Settings:
MFI:
Show MFI and SMA Crossing Signals: MFI and SMA Crossing is one of the leading Bullish and Bearish Signals in this Indicator. You can also add alerts for these signals.
Plot Amount: How many plots are used in this Heat Map. (2 - 28).
Source: The Source to use in all MFI calculations.
Smooth Initial MFI Length: How much to smooth the Fast and Slow MFI calculation by. 1 = No smoothing.
MFI SMA Length: What length we smooth the MFI Average over to get our MFI SMA.
Machine Learning:
Average MFI data by adding a lookback to the Source: While populating our Heat Map with the MFI's, should use use the Source each MFI Length increase or should we also lookback a Source each MFI Length Increase.
KNN Distance Requirement: To be a valid KNN, it needs to abide by a Distance calculation. Generally only Max is used, but you can change it if it suits your trading style better.
Machine Learning Length: How much ML data should we store? The longer the length generally the smoother the result; which may not be as accurate for something like a Heat Map, so keeping this relatively low may lead to more accurate results.
KNN Length: How many KNN are used in the slice to calculate max/min distance allowed.
Fast Length: Fast MFI length used in KNN to calculate distances by comparing its distance with the Slow MFI Length.
Slow Length: Slow MFI length used in KNN to calculate distances by comparing its distance with the Fast MFI Length.
Smoothing Length: When populating our Heat Map, at what length do we start our MFI calculations with (A Higher value with result in a slower and more smoothed MFI / Heat Map).
Colors:
Change Bar Color: Change bar colors to MFI Avg Color.
Heat Map Transparency: If there isn't any transparency it can be a little hard on the eyes. The Greater the Line Width, generally the more transparency you'll want for your eyes.
Line Width: Set how wide the Heat Map lines are
MFI 90-100 Color: Color when the MFI is between these levels.
MFI 80-89 Color: Color when the MFI is between these levels.
MFI 70-79 Color: Color when the MFI is between these levels.
MFI 60-69 Color: Color when the MFI is between these levels.
MFI 50-59 Color: Color when the MFI is between these levels.
MFI 40-49 Color: Color when the MFI is between these levels.
MFI 30-39 Color: Color when the MFI is between these levels.
MFI 20-29 Color: Color when the MFI is between these levels.
MFI 10-19 Color: Color when the MFI is between these levels.
MFI 0-100 Color: Color when the MFI is between these levels.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!

AI Momentum [YinYang]Overview:
AI Momentum is a kernel function based momentum Indicator. It uses Rational Quadratics to help smooth out the Moving Averages, this may give them a more accurate result. This Indicator has 2 main uses, first it displays ‘Zones’ that help you visualize the potential movement areas and when the price is out of bounds (Overvalued or Undervalued). Secondly it creates signals that display the momentum of the current trend.
The Zones are composed of the Highest Highs and Lowest lows turned into a Rational Quadratic over varying lengths. These create our Rational High and Low zones. There is however a second zone. The second zone is composed of the avg of the Inner High and Inner Low zones (yellow line) and the Rational Quadratic of the current Close. This helps to create a second zone that is within the High and Low bounds that may represent momentum changes within these zones. When the Rationalized Close crosses above the High and Low Zone Average it may signify a bullish momentum change and vice versa when it crosses below.
There are 3 different signals created to display momentum:
Bullish and Bearish Momentum. These signals display when there is current bullish or bearish momentum happening within the trend. When the momentum changes there will likely be a lull where there are neither Bullish or Bearish momentum signals. These signals may be useful to help visualize when the momentum has started and stopped for both the bulls and the bears. Bullish Momentum is calculated by checking if the Rational Quadratic Close > Rational Quadratic of the Highest OHLC4 smoothed over a VWMA. The Bearish Momentum is calculated by checking the opposite.
Overly Bullish and Bearish Momentum. These signals occur when the bar has Bullish or Bearish Momentum and also has an Rationalized RSI greater or less than a certain level. Bullish is >= 57 and Bearish is <= 43. There is also the option to ‘Factor Volume’ into these signals. This means, the Overly Bullish and Bearish Signals will only occur when the Rationalized Volume > VWMA Rationalized Volume as well as the previously mentioned factors above. This can be useful for removing ‘clutter’ as volume may dictate when these momentum changes will occur, but it can also remove some of the useful signals and you may miss the swing too if the volume just was low. Overly Bullish and Bearish Momentum may dictate when a momentum change will occur. Remember, they are OVERLY Bullish and Bearish, meaning there is a chance a correction may occur around these signals.
Bull and Bear Crosses. These signals occur when the Rationalized Close crosses the Gaussian Close that is 2 bars back. These signals may show when there is a strong change in momentum, but be careful as more often than not they’re predicting that the momentum may change in the opposite direction.
Tutorial:
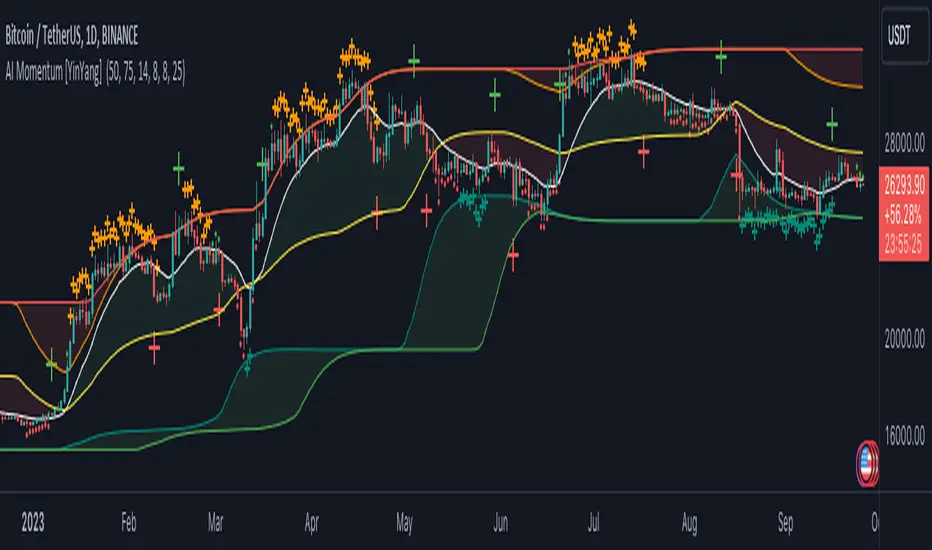
As we can see in the example above, generally what happens is we get the regular Bullish or Bearish momentum, followed by the Rationalized Close crossing the Zone average and finally the Overly Bullish or Bearish signals. This is normally the order of operations but isn’t always how it happens as sometimes momentum changes don’t make it that far; also the Rationalized Close and Zone Average don’t follow any of the same math as the Signals which can result in differing appearances. The Bull and Bear Crosses are also quite sporadic in appearance and don’t generally follow any sort of order of operations. However, they may occur as a Predictor between Bullish and Bearish momentum, signifying the beginning of the momentum change.
The Bull and Bear crosses may be a Predictor of momentum change. They generally happen when there is no Bullish or Bearish momentum happening; and this helps to add strength to their prediction. When they occur during momentum (orange circle) there is a less likely chance that it will happen, and may instead signify the exact opposite; it may help predict a large spike in momentum in the direction of the Bullish or Bearish momentum. In the case of the orange circle, there is currently Bearish Momentum and therefore the Bull Cross may help predict a large momentum movement is about to occur in favor of the Bears.
We have disabled signals here to properly display and talk about the zones. As you can see, Rationalizing the Highest Highs and Lowest Lows over 2 different lengths creates inner and outer bounds that help to predict where parabolic movement and momentum may move to. Our Inner and Outer zones are great for seeing potential Support and Resistance locations.
The secondary zone, which can cross over and change from Green to Red is also a very important zone. Let's zoom in and talk about it specifically.
The Middle Zone Crosses may help deduce where parabolic movement and strong momentum changes may occur. Generally what may happen is when the cross occurs, you will see parabolic movement to the High / Low zones. This may be the Inner zone but can sometimes be the outer zone too. The hard part is sometimes it can be a Fakeout, like displayed with the Blue Circle. The Cross doesn’t mean it may move to the opposing side, sometimes it may just be predicting Parabolic movement in a general sense.
When we turn the Momentum Signals back on, we can see where the Fakeout occurred that it not only almost hit the Inner Low Zone but it also exhibited 2 Overly Bearish Signals. Remember, Overly bearish signals mean a momentum change in favor of the Bulls may occur soon and overly Bullish signals mean a momentum change in favor of the Bears may occur soon.
You may be wondering, well what does “may occur soon” mean and how do we tell?
The purpose of the momentum signals is not only to let you know when Momentum has occurred and when it is still prevalent. It also matters A LOT when it has STOPPED!
In this example above, we look at when the Overly Bullish and Bearish Momentum has STOPPED. As you can see, when the Overly Bullish or Bearish Momentum stopped may be a strong predictor of potential momentum change in the opposing direction.
We will conclude our Tutorial here, hopefully this Indicator has been helpful for showing you where momentum is occurring and help predict how far it may move. We have been dabbling with and are planning on releasing a Strategy based on this Indicator shortly.
Settings:
1. Momentum:
Show Signals: Sometimes it can be difficult to visualize the zones with signals enabled.
Factor Volume: Factor Volume only applies to Overly Bullish and Bearish Signals. It's when the Volume is > VWMA Volume over the Smoothing Length.
Zone Inside Length: The Zone Inside is the Inner zone of the High and Low. This is the length used to create it.
Zone Outside Length: The Zone Outside is the Outer zone of the High and Low. This is the length used to create it.
Smoothing length: Smoothing length is the length used to smooth out our Bullish and Bearish signals, along with our Overly Bullish and Overly Bearish Signals.
2. Kernel Settings:
Lookback Window: The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars. Recommended range: 3-50.
Relative Weighting: Relative weighting of time frames. As this value approaches zero, the longer time frames will exert more influence on the estimation. As this value approaches infinity, the behavior of the Rational Quadratic Kernel will become identical to the Gaussian kernel. Recommended range: 0.25-25.
Start Regression at Bar: Bar index on which to start regression. The first bars of a chart are often highly volatile, and omission of these initial bars often leads to a better overall fit. Recommended range: 5-25.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!
AI Channels (Clustering) [LuxAlgo]The AI Channels indicator is constructed based on rolling K-means clustering, a common machine learning method used for clustering analysis. These channels allow users to determine the direction of the underlying trends in the price.
We also included an option to display the indicator as a trailing stop from within the settings.
🔶 USAGE
Each channel extremity allows users to determine the current trend direction. Price breaking over the upper extremity suggesting an uptrend, and price breaking below the lower extremity suggesting a downtrend. Using a higher Window Size value will return longer-term indications.
The "Clusters" setting allows users to control how easy it is for the price to break an extremity, with higher values returning extremities further away from the price.
The "Denoise Channels" is enabled by default and allows to see less noisy extremities that are more coherent with the detected trend.
Users who wish to have more focus on a detected trend can display the indicator as a trailing stop.
🔹 Centroid Dispersion Areas
Each extremity is made of one area. The width of each area indicates how spread values within a cluster are around their centroids. A wider area would suggest that prices within a cluster are more spread out around their centroid, as such one could say that it is indicative of the volatility of a cluster.
Wider areas around a specific extremity can indicate a larger and more spread-out amount of prices within the associated cluster. In practice price entering an area has a higher chance to break an associated extremity.
🔶 DETAILS
The indicator performs K-means clustering over the most recent Window Size prices, finding a number of user-specified clusters. See here to find more information on cluster detection.
The channel extremities are returned as the centroid of the lowest, average, and highest price clusters.
K-means clustering can be computationally expensive and as such we allow users to determine the maximum number of iterations used to find the centroids as well as the number of most historical bars to perform the indicator calculation. Do note that increasing the calculation window of the indicator as well as the number of clusters will return slower results.
🔶 SETTINGS
Window Size: Amount of most recent prices to use for the calculation of the indicator.
Clusters": Amount of clusters detected for the calculation of the indicator.
Denoise Channels: When enabled, return less noisy channels extremities, disabling this setting will return the exact centroids at each time but will produce less regular extremities.
As Trailing Stop: Display the indicator as a trailing stop.
🔹 Optimization
This group of settings affects the runtime performance of the script.
Maximum Iteration Steps: Maximum number of iterations allowed for finding centroids. Excessively low values can return a better script load time but poor clustering.
Historical Bars Calculation: Calculation window of the script (in bars).
Machine Learning Regression Trend [LuxAlgo]The Machine Learning Regression Trend tool uses random sample consensus (RANSAC) to fit and extrapolate a linear model by discarding potential outliers, resulting in a more robust fit.
🔶 USAGE
The proposed tool can be used like a regular linear regression, providing support/resistance as well as forecasting an estimated underlying trend.
Using RANSAC allows filtering out outliers from the input data of our final fit, by outliers we are referring to values deviating from the underlying trend whose influence on a fitted model is undesired. For financial prices and under the assumptions of segmented linear trends, these outliers can be caused by volatile moves and/or periodic variations within an underlying trend.
Adjusting the "Allowed Error" numerical setting will determine how sensitive the model is to outliers, with higher values returning a more sensitive model. The blue margin displayed shows the allowed error area.
The number of outliers in the calculation window (represented by red dots) can also be indicative of the amount of noise added to an underlying linear trend in the price, with more outliers suggesting more noise.
Compared to a regular linear regression which does not discriminate against any point in the calculation window, we see that the model using RANSAC is more conservative, giving more importance to detecting a higher number of inliners.
🔶 DETAILS
RANSAC is a general approach to fitting more robust models in the presence of outliers in a dataset and as such does not limit itself to a linear regression model.
This iterative approach can be summarized as follow for the case of our script:
Step 1: Obtain a subset of our dataset by randomly selecting 2 unique samples
Step 2: Fit a linear regression to our subset
Step 3: Get the error between the value within our dataset and the fitted model at time t , if the absolute error is lower than our tolerance threshold then that value is an inlier
Step 4: If the amount of detected inliers is greater than a user-set amount save the model
Repeat steps 1 to 4 until the set number of iterations is reached and use the model that maximizes the number of inliers
🔶 SETTINGS
Length: Calculation window of the linear regression.
Width: Linear regression channel width.
Source: Input data for the linear regression calculation.
🔹 RANSAC
Minimum Inliers: Minimum number of inliers required to return an appropriate model.
Allowed Error: Determine the tolerance threshold used to detect potential inliers. "Auto" will automatically determine the tolerance threshold and will allow the user to multiply it through the numerical input setting at the side. "Fixed" will use the user-set value as the tolerance threshold.
Maximum Iterations Steps: Maximum number of allowed iterations.

Pro Supertrend CalculatorThis indicator is an adapted version of Julien_Eche's 'Pro Momentum Calculator' tailored specifically for TradingView's 'Supertrend indicator'.
The "Pro Supertrend Calculator" indicator has been developed to provide traders with a data-driven perspective on price movements in financial markets. Its primary objective is to analyze historical price data and make probabilistic predictions about the future direction of price movements, specifically in terms of whether the next candlestick will be bullish (green) or bearish (red). Here's a deeper technical insight into how it accomplishes this task:
1. Supertrend Computation:
The indicator initiates by computing the Supertrend indicator, a sophisticated technical analysis tool. This calculation involves two essential parameters:
- ATR Length (Average True Range Length): This parameter determines the sensitivity of the Supertrend to price fluctuations.
- Factor: This multiplier plays a pivotal role in establishing the distance between the Supertrend line and prevailing market prices. A higher factor value results in a more significant separation.
2. Supertrend Visualization:
The Supertrend values derived from the calculation are meticulously plotted on the price chart, manifesting as two distinct lines:
- Green Line: This line represents the Supertrend when it indicates a bullish trend, signifying an anticipation of rising prices.
- Red Line: This line signifies the Supertrend in bearish market conditions, indicating an expectation of falling prices.
3. Consecutive Candle Analysis:
- The core function of the indicator revolves around tracking successive candlestick patterns concerning their relationship with the Supertrend line.
- To be included in the analysis, a candlestick must consistently close either above (green candles) or below (red candles) the Supertrend line for multiple consecutive periods.
4.Labeling and Enumeration:
- To communicate the count of consecutive candles displaying uniform trend behavior, the indicator meticulously applies labels to the price chart.
- The positioning of these labels varies based on the direction of the trend, residing either below (for bullish patterns) or above (for bearish patterns) the candlestick.
- The color scheme employed aligns with the color of the candle, using green labels for bullish candles and red labels for bearish ones.
5. Tabular Data Presentation:
- The indicator augments its graphical analysis with a customizable table prominently displayed on the chart. This table delivers comprehensive statistical insights.
- The tabular data comprises the following key elements for each consecutive period:
a. Consecutive Candles: A tally of the number of consecutive candles displaying identical trend characteristics.
b. Candles Above Supertrend: A count of candles that remained above the Supertrend during the sequential period.
3. Candles Below Supertrend: A count of candles that remained below the Supertrend during the sequential period.
4. Upcoming Green Candle: An estimation of the probability that the next candlestick will be bullish, grounded in historical data.
5. Upcoming Red Candle: An estimation of the probability that the next candlestick will be bearish, based on historical data.
6. Tailored Configuration:
To accommodate diverse trading strategies and preferences, the indicator offers extensive customization options. Traders can fine-tune parameters such as ATR length, factor, label and table placement, and table size to align with their unique trading approaches.
In summation, the "Pro Supertrend Calculator" indicator is an intricately designed tool that leverages the Supertrend indicator in conjunction with historical price data to furnish traders with an informed outlook on potential future price dynamics, with a particular emphasis on the likelihood of specific bullish or bearish candlestick patterns stemming from consecutive price behavior.

Support & Resistance AI (K means/median) [ThinkLogicAI]█ OVERVIEW
K-means is a clustering algorithm commonly used in machine learning to group data points into distinct clusters based on their similarities. While K-means is not typically used directly for identifying support and resistance levels in financial markets, it can serve as a tool in a broader analysis approach.
Support and resistance levels are price levels in financial markets where the price tends to react or reverse. Support is a level where the price tends to stop falling and might start to rise, while resistance is a level where the price tends to stop rising and might start to fall. Traders and analysts often look for these levels as they can provide insights into potential price movements and trading opportunities.
█ BACKGROUND
The K-means algorithm has been around since the late 1950s, making it more than six decades old. The algorithm was introduced by Stuart Lloyd in his 1957 research paper "Least squares quantization in PCM" for telecommunications applications. However, it wasn't widely known or recognized until James MacQueen's 1967 paper "Some Methods for Classification and Analysis of Multivariate Observations," where he formalized the algorithm and referred to it as the "K-means" clustering method.
So, while K-means has been around for a considerable amount of time, it continues to be a widely used and influential algorithm in the fields of machine learning, data analysis, and pattern recognition due to its simplicity and effectiveness in clustering tasks.
█ COMPARE AND CONTRAST SUPPORT AND RESISTANCE METHODS
1) K-means Approach:
Cluster Formation: After applying the K-means algorithm to historical price change data and visualizing the resulting clusters, traders can identify distinct regions on the price chart where clusters are formed. Each cluster represents a group of similar price change patterns.
Cluster Analysis: Analyze the clusters to identify areas where clusters tend to form. These areas might correspond to regions of price behavior that repeat over time and could be indicative of support and resistance levels.
Potential Support and Resistance Levels: Based on the identified areas of cluster formation, traders can consider these regions as potential support and resistance levels. A cluster forming at a specific price level could suggest that this level has been historically significant, causing similar price behavior in the past.
Cluster Standard Deviation: In addition to looking at the means (centroids) of the clusters, traders can also calculate the standard deviation of price changes within each cluster. Standard deviation is a measure of the dispersion or volatility of data points around the mean. A higher standard deviation indicates greater price volatility within a cluster.
Low Standard Deviation: If a cluster has a low standard deviation, it suggests that prices within that cluster are relatively stable and less likely to exhibit sudden and large price movements. Traders might consider placing tighter stop-loss orders for trades within these clusters.
High Standard Deviation: Conversely, if a cluster has a high standard deviation, it indicates greater price volatility within that cluster. Traders might opt for wider stop-loss orders to allow for potential price fluctuations without getting stopped out prematurely.
Cluster Density: Each data point is assigned to a cluster so a cluster that is more dense will act more like gravity and
2) Traditional Approach:
Trendlines: Draw trendlines connecting significant highs or lows on a price chart to identify potential support and resistance levels.
Chart Patterns: Identify chart patterns like double tops, double bottoms, head and shoulders, and triangles that often indicate potential reversal points.
Moving Averages: Use moving averages to identify levels where the price might find support or resistance based on the average price over a specific period.
Psychological Levels: Identify round numbers or levels that traders often pay attention to, which can act as support and resistance.
Previous Highs and Lows: Identify significant previous price highs and lows that might act as support or resistance.
The key difference lies in the approach and the foundation of these methods. Traditional methods are based on well-established principles of technical analysis and market psychology, while the K-means approach involves clustering price behavior without necessarily incorporating market sentiment or specific price patterns.
It's important to note that while the K-means approach might provide an interesting way to analyze price data, it should be used cautiously and in conjunction with other traditional methods. Financial markets are influenced by a wide range of factors beyond just price behavior, and the effectiveness of any method for identifying support and resistance levels should be thoroughly tested and validated. Additionally, developments in trading strategies and analysis techniques could have occurred since my last update.
█ K MEANS ALGORITHM
The algorithm for K means is as follows:
Initialize cluster centers
assign data to clusters based on minimum distance
calculate cluster center by taking the average or median of the clusters
repeat steps 1-3 until cluster centers stop moving
█ LIMITATIONS OF K MEANS
There are 3 main limitations of this algorithm:
Sensitive to Initializations: K-means is sensitive to the initial placement of centroids. Different initializations can lead to different cluster assignments and final results.
Assumption of Equal Sizes and Variances: K-means assumes that clusters have roughly equal sizes and spherical shapes. This may not hold true for all types of data. It can struggle with identifying clusters with uneven densities, sizes, or shapes.
Impact of Outliers: K-means is sensitive to outliers, as a single outlier can significantly affect the position of cluster centroids. Outliers can lead to the creation of spurious clusters or distortion of the true cluster structure.
█ LIMITATIONS IN APPLICATION OF K MEANS IN TRADING
Trading data often exhibits characteristics that can pose challenges when applying indicators and analysis techniques. Here's how the limitations of outliers, varying scales, and unequal variance can impact the use of indicators in trading:
Outliers are data points that significantly deviate from the rest of the dataset. In trading, outliers can represent extreme price movements caused by rare events, news, or market anomalies. Outliers can have a significant impact on trading indicators and analyses:
Indicator Distortion: Outliers can skew the calculations of indicators, leading to misleading signals. For instance, a single extreme price spike could cause indicators like moving averages or RSI (Relative Strength Index) to give false signals.
Risk Management: Outliers can lead to overly aggressive trading decisions if not properly accounted for. Ignoring outliers might result in unexpected losses or missed opportunities to adjust trading strategies.
Different Scales: Trading data often includes multiple indicators with varying units and scales. For example, prices are typically in dollars, volume in units traded, and oscillators have their own scale. Mixing indicators with different scales can complicate analysis:
Normalization: Indicators on different scales need to be normalized or standardized to ensure they contribute equally to the analysis. Failure to do so can lead to one indicator dominating the analysis due to its larger magnitude.
Comparability: Without normalization, it's challenging to directly compare the significance of indicators. Some indicators might have a larger numerical range and could overshadow others.
Unequal Variance: Unequal variance in trading data refers to the fact that some indicators might exhibit higher volatility than others. This can impact the interpretation of signals and the performance of trading strategies:
Volatility Adjustment: When combining indicators with varying volatility, it's essential to adjust for their relative volatilities. Failure to do so might lead to overemphasizing or underestimating the importance of certain indicators in the trading strategy.
Risk Assessment: Unequal variance can impact risk assessment. Indicators with higher volatility might lead to riskier trading decisions if not properly taken into account.
█ APPLICATION OF THIS INDICATOR
This indicator can be used in 2 ways:
1) Make a directional trade:
If a trader thinks price will go higher or lower and price is within a cluster zone, The trader can take a position and place a stop on the 1 sd band around the cluster. As one can see below, the trader can go long the green arrow and place a stop on the one standard deviation mark for that cluster below it at the red arrow. using this we can calculate a risk to reward ratio.
Calculating risk to reward: targeting a risk reward ratio of 2:1, the trader could clearly make that given that the next resistance area above that in the orange cluster exceeds this risk reward ratio.
2) Take a reversal Trade:
We can use cluster centers (support and resistance levels) to go in the opposite direction that price is currently moving in hopes of price forming a pivot and reversing off this level.
Similar to the directional trade, we can use the standard deviation of the cluster to place a stop just in case we are wrong.
In this example below we can see that shorting on the red arrow and placing a stop at the one standard deviation above this cluster would give us a profitable trade with minimal risk.
Using the cluster density table in the upper right informs the trader just how dense the cluster is. Higher density clusters will give a higher likelihood of a pivot forming at these levels and price being rejected and switching direction with a larger move.
█ FEATURES & SETTINGS
General Settings:
Number of clusters: The user can select from 3 to five clusters. A good rule of thumb is that if you are trading intraday, less is more (Think 3 rather than 5). For daily 4 to 5 clusters is good.
Cluster Method: To get around the outlier limitation of k means clustering, The median was added. This gives the user the ability to choose either k means or k median clustering. K means is the preferred method if the user things there are no large outliers, and if there appears to be large outliers or it is assumed there are then K medians is preferred.
Bars back To train on: This will be the amount of bars to include in the clustering. This number is important so that the user includes bars that are recent but not so far back that they are out of the scope of where price can be. For example the last 2 years we have been in a range on the sp500 so 505 days in this setting would be more relevant than say looking back 5 years ago because price would have to move far to get there.
Show SD Bands: Select this to show the 1 standard deviation bands around the support and resistance level or unselect this to just show the support and resistance level by itself.
Features:
Besides the support and resistance levels and standard deviation bands, this indicator gives a table in the upper right hand corner to show the density of each cluster (support and resistance level) and is color coded to the cluster line on the chart. Higher density clusters mean price has been there previously more than lower density clusters and could mean a higher likelihood of a reversal when price reaches these areas.
█ WORKS CITED
Victor Sim, "Using K-means Clustering to Create Support and Resistance", 2020, towardsdatascience.com
Chris Piech, "K means", stanford.edu
█ ACKNOLWEDGMENTS
@jdehorty- Thanks for the publish template. It made organizing my thoughts and work alot easier.

Pro Momentum CalculatorThe Pro Momentum Calculator Indicator is a tool for traders seeking to gauge market momentum and predict future price movements. It achieves this by counting consecutive candle periods above or below a chosen Simple Moving Average (SMA) and then providing a percentage-based probability for the direction of the next candle.
Here's how this principle works:
1. Counting Consecutive Periods: The indicator continuously tracks whether the closing prices of candles are either above or below the chosen SMA.
- When closing prices are above the SMA, it counts consecutive periods as "green" or indicating potential upward momentum.
- When closing prices are below the SMA, it counts consecutive periods as "red" or suggesting potential downward momentum.
2. Assessing Momentum: By monitoring these consecutive periods, the indicator assesses the strength and duration of the current market trend.
This is important information for traders looking to understand the market's behavior.
3. Predicting the Next Candle: Based on the historical data of consecutive green and red periods, the indicator calculates a percentage probability for the direction of the next candle:
- If there have been more consecutive green periods, it suggests a higher likelihood of the next candle being green (indicating a potential upward movement).
- If there have been more consecutive red periods, it suggests a higher likelihood of the next candle being red (indicating a potential downward movement).
The Pro Momentum Calculator indicator's versatility makes it suitable for a wide range of financial markets, including stocks, Forex, indices, commodities, cryptocurrencies...
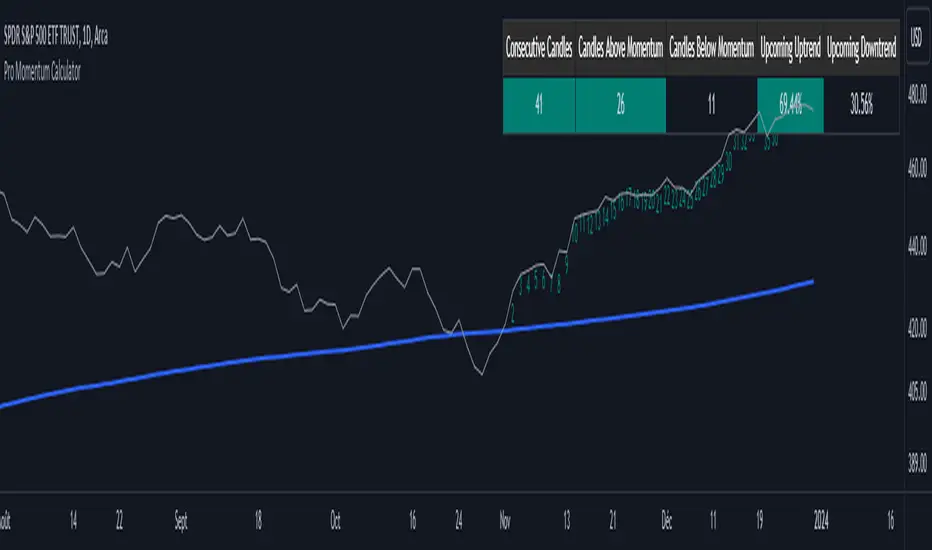
AI SuperTrend Clustering Oscillator [LuxAlgo]The AI SuperTrend Clustering Oscillator is an oscillator returning the most bullish/average/bearish centroids given by multiple instances of the difference between SuperTrend indicators.
This script is an extension of our previously posted SuperTrend AI indicator that makes use of k-means clustering. If you want to learn more about it see:
🔶 USAGE
The AI SuperTrend Clustering Oscillator is made of 3 distinct components, a bullish output (always the highest), a bearish output (always the lowest), and a "consensus" output always within the two others.
The general trend is given by the consensus output, with a value above 0 indicating an uptrend and under 0 indicating a downtrend. Using a higher minimum factor will weigh results toward longer-term trends, while lowering the maximum factor will weigh results toward shorter-term trends.
Strong trends are indicated when the bullish/bearish outputs are indicating an opposite sentiment. A strong bullish trend would for example be indicated when the bearish output is above 0, while a strong bearish trend would be indicated when the bullish output is below 0.
When the consensus output is indicating a specific trend direction, an opposite indication from the bullish/bearish output can highlight a potential reversal or retracement.
🔶 DETAILS
The indicator construction is based on finding three clusters from the difference between the closing price and various SuperTrend using different factors. The centroid of each cluster is then returned. This operation is done over all historical bars.
The highest cluster will be composed of the differences between the price and SuperTrends that are the highest, thus creating a more bullish group. The lowest cluster will be composed of the differences between the price and SuperTrends that are the lowest, thus creating a more bearish group.
The consensus cluster is composed of the differences between the price and SuperTrends that are not significant enough to be part of the other clusters.
🔶 SETTINGS
ATR Length: ATR period used for the calculation of the SuperTrends.
Factor Range: Determine the minimum and maximum factor values for the calculation of the SuperTrends.
Step: Increments of the factor range.
Smooth: Degree of smoothness of each output from the indicator.
🔹 Optimization
This group of settings affects the runtime performances of the script.
Maximum Iteration Steps: Maximum number of iterations allowed for finding centroids. Excessively low values can return a better script load time but poor clustering.
Historical Bars Calculation: Calculation window of the script (in bars).
SuperTrend AI (Clustering) [LuxAlgo]The SuperTrend AI indicator is a novel take on bridging the gap between the K-means clustering machine learning method & technical indicators. In this case, we apply K-Means clustering to the famous SuperTrend indicator.
🔶 USAGE
Users can interpret the SuperTrend AI trailing stop similarly to the regular SuperTrend indicator. Using higher minimum/maximum factors will return longer-term signals.
The displayed performance metrics displayed on each signal allow for a deeper interpretation of the indicator. Whereas higher values could indicate a higher potential for the market to be heading in the direction of the trend when compared to signals with lower values such as 1 or 0 potentially indicating retracements.
In the image above, we can notice more clear examples of the performance metrics on signals indicating trends, however, these performance metrics cannot perform or predict every signal reliably.
We can see in the image above that the trailing stop and its adaptive moving average can also act as support & resistance. Using higher values of the performance memory setting allows users to obtain a longer-term adaptive moving average of the returned trailing stop.
🔶 DETAILS
🔹 K-Means Clustering
When observing data points within a specific space, we can sometimes observe that some are closer to each other, forming groups, or "Clusters". At first sight, identifying those clusters and finding their associated data points can seem easy but doing so mathematically can be more challenging. This is where cluster analysis comes into play, where we seek to group data points into various clusters such that data points within one cluster are closer to each other. This is a common branch of AI/machine learning.
Various methods exist to find clusters within data, with the one used in this script being K-Means Clustering , a simple iterative unsupervised clustering method that finds a user-set amount of clusters.
A naive form of the K-Means algorithm would perform the following steps in order to find K clusters:
(1) Determine the amount (K) of clusters to detect.
(2) Initiate our K centroids (cluster centers) with random values.
(3) Loop over the data points, and determine which is the closest centroid from each data point, then associate that data point with the centroid.
(4) Update centroids by taking the average of the data points associated with a specific centroid.
Repeat steps 3 to 4 until convergence, that is until the centroids no longer change.
To explain how K-Means works graphically let's take the example of a one-dimensional dataset (which is the dimension used in our script) with two apparent clusters:
This is of course a simple scenario, as K will generally be higher, as well the amount of data points. Do note that this method can be very sensitive to the initialization of the centroids, this is why it is generally run multiple times, keeping the run returning the best centroids.
🔹 Adaptive SuperTrend Factor Using K-Means
The proposed indicator rationale is based on the following hypothesis:
Given multiple instances of an indicator using different settings, the optimal setting choice at time t is given by the best-performing instance with setting s(t) .
Performing the calculation of the indicator using the best setting at time t would return an indicator whose characteristics adapt based on its performance. However, what if the setting of the best-performing instance and second best-performing instance of the indicator have a high degree of disparity without a high difference in performance?
Even though this specific case is rare its however not uncommon to see that performance can be similar for a group of specific settings (this could be observed in a parameter optimization heatmap), then filtering out desirable settings to only use the best-performing one can seem too strict. We can as such reformulate our first hypothesis:
Given multiple instances of an indicator using different settings, an optimal setting choice at time t is given by the average of the best-performing instances with settings s(t) .
Finding this group of best-performing instances could be done using the previously described K-Means clustering method, assuming three groups of interest (K = 3) defined as worst performing, average performing, and best performing.
We first obtain an analog of performance P(t, factor) described as:
P(t, factor) = P(t-1, factor) + α * (∆C(t) × S(t-1, factor) - P(t-1, factor))
where 1 > α > 0, which is the performance memory determining the degree to which older inputs affect the current output. C(t) is the closing price, and S(t, factor) is the SuperTrend signal generating function with multiplicative factor factor .
We run this performance function for multiple factor settings and perform K-Means clustering on the multiple obtained performances to obtain the best-performing cluster. We initiate our centroids using quartiles of the obtained performances for faster centroids convergence.
The average of the factors associated with the best-performing cluster is then used to obtain the final factor setting, which is used to compute the final SuperTrend output.
Do note that we give the liberty for the user to get the final factor from the best, average, or worst cluster for experimental purposes.
🔶 SETTINGS
ATR Length: ATR period used for the calculation of the SuperTrends.
Factor Range: Determine the minimum and maximum factor values for the calculation of the SuperTrends.
Step: Increments of the factor range.
Performance Memory: Determine the degree to which older inputs affect the current output, with higher values returning longer-term performance measurements.
From Cluster: Determine which cluster is used to obtain the final factor.
🔹 Optimization
This group of settings affects the runtime performances of the script.
Maximum Iteration Steps: Maximum number of iterations allowed for finding centroids. Excessively low values can return a better script load time but poor clustering.
Historical Bars Calculation: Calculation window of the script (in bars).

AI Trend Navigator [K-Neighbor]█ Overview
In the evolving landscape of trading and investment, the demand for sophisticated and reliable tools is ever-growing. The AI Trend Navigator is an indicator designed to meet this demand, providing valuable insights into market trends and potential future price movements. The AI Trend Navigator indicator is designed to predict market trends using the k-Nearest Neighbors (KNN) classifier.
By intelligently analyzing recent price actions and emphasizing similar values, it helps traders to navigate complex market conditions with confidence. It provides an advanced way to analyze trends, offering potentially more accurate predictions compared to simpler trend-following methods.
█ Calculations
KNN Moving Average Calculation: The core of the algorithm is a KNN Moving Average that computes the mean of the 'k' closest values to a target within a specified window size. It does this by iterating through the window, calculating the absolute differences between the target and each value, and then finding the mean of the closest values. The target and value are selected based on user preferences (e.g., using the VWAP or Volatility as a target).
KNN Classifier Function: This function applies the k-nearest neighbor algorithm to classify the price action into positive, negative, or neutral trends. It looks at the nearest 'k' bars, calculates the Euclidean distance between them, and categorizes them based on the relative movement. It then returns the prediction based on the highest count of positive, negative, or neutral categories.
█ How to use
Traders can use this indicator to identify potential trend directions in different markets.
Spotting Trends: Traders can use the KNN Moving Average to identify the underlying trend of an asset. By focusing on the k closest values, this component of the indicator offers a clearer view of the trend direction, filtering out market noise.
Trend Confirmation: The KNN Classifier component can confirm existing trends by predicting the future price direction. By aligning predictions with current trends, traders can gain more confidence in their trading decisions.
█ Settings
PriceValue: This determines the type of price input used for distance calculation in the KNN algorithm.
hl2: Uses the average of the high and low prices.
VWAP: Uses the Volume Weighted Average Price.
VWAP: Uses the Volume Weighted Average Price.
Effect: Changing this input will modify the reference values used in the KNN classification, potentially altering the predictions.
TargetValue: This sets the target variable that the KNN classification will attempt to predict.
Price Action: Uses the moving average of the closing price.
VWAP: Uses the Volume Weighted Average Price.
Volatility: Uses the Average True Range (ATR).
Effect: Selecting different targets will affect what the KNN is trying to predict, altering the nature and intent of the predictions.
Number of Closest Values: Defines how many closest values will be considered when calculating the mean for the KNN Moving Average.
Effect: Increasing this value makes the algorithm consider more nearest neighbors, smoothing the indicator and potentially making it less reactive. Decreasing this value may make the indicator more sensitive but possibly more prone to noise.
Neighbors: This sets the number of neighbors that will be considered for the KNN Classifier part of the algorithm.
Effect: Adjusting the number of neighbors affects the sensitivity and smoothness of the KNN classifier.
Smoothing Period: Defines the smoothing period for the moving average used in the KNN classifier.
Effect: Increasing this value would make the KNN Moving Average smoother, potentially reducing noise. Decreasing it would make the indicator more reactive but possibly more prone to false signals.
█ What is K-Nearest Neighbors (K-NN) algorithm?
At its core, the K-NN algorithm recognizes patterns within market data and analyzes the relationships and similarities between data points. By considering the 'K' most similar instances (or neighbors) within a dataset, it predicts future price movements based on historical trends. The K-Nearest Neighbors (K-NN) algorithm is a type of instance-based or non-generalizing learning. While K-NN is considered a relatively simple machine-learning technique, it falls under the AI umbrella.
We can classify the K-Nearest Neighbors (K-NN) algorithm as a form of artificial intelligence (AI), and here's why:
Machine Learning Component: K-NN is a type of machine learning algorithm, and machine learning is a subset of AI. Machine learning is about building algorithms that allow computers to learn from and make predictions or decisions based on data. Since K-NN falls under this category, it is aligned with the principles of AI.
Instance-Based Learning: K-NN is an instance-based learning algorithm. This means that it makes decisions based on the entire training dataset rather than deriving a discriminative function from the dataset. It looks at the 'K' most similar instances (neighbors) when making a prediction, hence adapting to new information if the dataset changes. This adaptability is a hallmark of intelligent systems.
Pattern Recognition: The core of K-NN's functionality is recognizing patterns within data. It identifies relationships and similarities between data points, something akin to human pattern recognition, a key aspect of intelligence.
Classification and Regression: K-NN can be used for both classification and regression tasks, two fundamental problems in machine learning and AI. The indicator code is used for trend classification, a predictive task that aligns with the goals of AI.
Simplicity Doesn't Exclude AI: While K-NN is often considered a simpler algorithm compared to deep learning models, simplicity does not exclude something from being AI. Many AI systems are built on simple rules and can be combined or scaled to create complex behavior.
No Explicit Model Building: Unlike traditional statistical methods, K-NN does not build an explicit model during training. Instead, it waits until a prediction is required and then looks at the 'K' nearest neighbors from the training data to make that prediction. This lazy learning approach is another aspect of machine learning, part of the broader AI field.
-----------------
Disclaimer
The information contained in my Scripts/Indicators/Ideas/Algos/Systems does not constitute financial advice or a solicitation to buy or sell any securities of any type. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
My Scripts/Indicators/Ideas/Algos/Systems are only for educational purposes!

Wick-to-Body Ratio Trend Forecast | Flux ChartsThe Wick-to-Body Ratio Trend Forecast Indicator aims to forecast potential movements following the last closed candle using the wick-to-body ratio. The script identifies those candles within the loopback period with a ratio matching that of the last closed candle and provides an analysis of their trends.
➡️ USAGE
Wick-to-body ratios can be used in many strategies. The most common use in stock trading is to discern bullish or bearish sentiment. This indicator extends candle ratios, revealing previous patterns that follow a candle with a similar ratio. The most basic use of this indicator is the single forecast line.
➡️ FORECASTING SYSTEM
This line displays a compilation of the averages of all the previous trends resulting from those historical candles with a matching ratio. It shows the average movements of the trends as well as the 'strength' of the trend. The 'strength' of the trend is a gradient that is blue when the trend deviates more from the average and red when it deviates less.
Chart: AMEX:SPY 30 min; Indicator Settings: Loopback 700, Previous Trends ON
The color-coded deviation is visible in this image of the indicator with the default settings (except for Forecast Lines > Previous Trends ), and the trend line grows bluer as the past patterns deviate more.
➡️ ADAPTIVE ACCEPTABLE RANGE
The algorithm looks back at every candle within the loopback period to find candles that match the last closed candle. The algorithm adaptively changes the acceptable range to which a candle can differ from the ratio of the last closed candle. The algorithm will never have more than 15 historical points used, as it will lower its sensitivity before it reaches that point.
Chart: BITSTAMP:BTCUSD 5 min; Indicator Settings: Loopback 700
Here is the BTC chart on 7/6/23 with default settings except for the loopback period at 700.
Chart: BITSTAMP:BTCUSD 5 min; Indicator Settings: Loopback 200
Here is the exact same chart with a loopback period of 200. While the first ratio for both is the same, a new ratio is revealed for the chart with a loopback of only 200 because the adaptive range is adjusted in the algorithm to find an acceptable number of reference points. Note the table in the top right however, while the algorithm adapts the acceptable range between the current ratio and historical ones to find reference points, there is a threshold at which candles will be considered too inaccurate to be considered. This prevents meaningless associations between candles due to a particularly rare ratio. This threshold can be adjusted in the settings through "Default Accuracy".
Universal Moving Average Convergence DivergenceI changed MACD formula to divergence of (MA26/MA12 - 1).
And its make it more useful.
Cuz:
1) comparability with all other coins with different prices.
2) fix small numbers in low price coines like shiba
3) making a good indicator like RSI to use it for optimization and ML/AI projects as a variable
Most important thing about this indicator is that its Universal
Now you can compare the UMACD of Shiba with Bitcoin without any problem in matamatics space.No need to use virtuality and its important in Optimization problems that we rediuse the problem from a picture to a number(A plot to a list of numbers)
If we don't care about exagrated pumps and dumps, we can say to it Normalized-MACD too. Cuz in normal situations its MAX ≈ 0.1 and MIN ≈ -0.1
Tesla Coil MLThis is a re-implementation of @veryfid's wonderful Tesla Coil indicator to leverage basic Machine Learning Algorithms to help classify coil crossovers. The original Tesla Coil indicator requires extensive training and practice for the user to develop adequate intuition to interpret coil crossovers. The goal for this version is to help the user understand the underlying logic of the Tesla Coil indicator and provide a more intuitive way to interpret the indicator. The signals should be interpreted as suggestions rather than as a hard-coded set of rules.
NOTE: Please do NOT trade off the signals blindly. Always try to use your own intuition for understanding the coils and check for confluence with other indicators before initiating a trade.
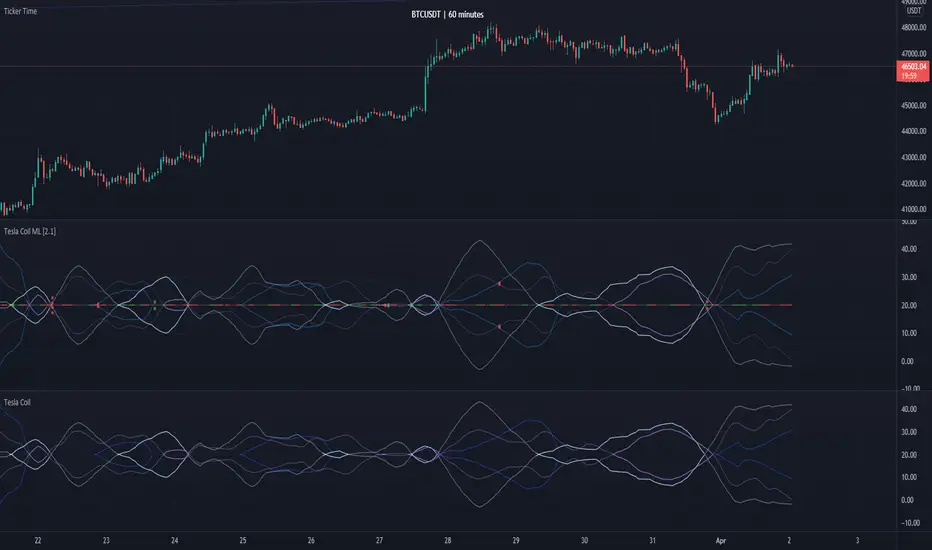
FunctionNNLayerLibrary "FunctionNNLayer"
Generalized Neural Network Layer method.
function(inputs, weights, n_nodes, activation_function, bias, alpha, scale) Generalized Layer.
Parameters:
inputs : float array, input values.
weights : float array, weight values.
n_nodes : int, number of nodes in layer.
activation_function : string, default='sigmoid', name of the activation function used.
bias : float, default=1.0, bias to pass into activation function.
alpha : float, default=na, if required to pass into activation function.
scale : float, default=na, if required to pass into activation function.
Returns: float
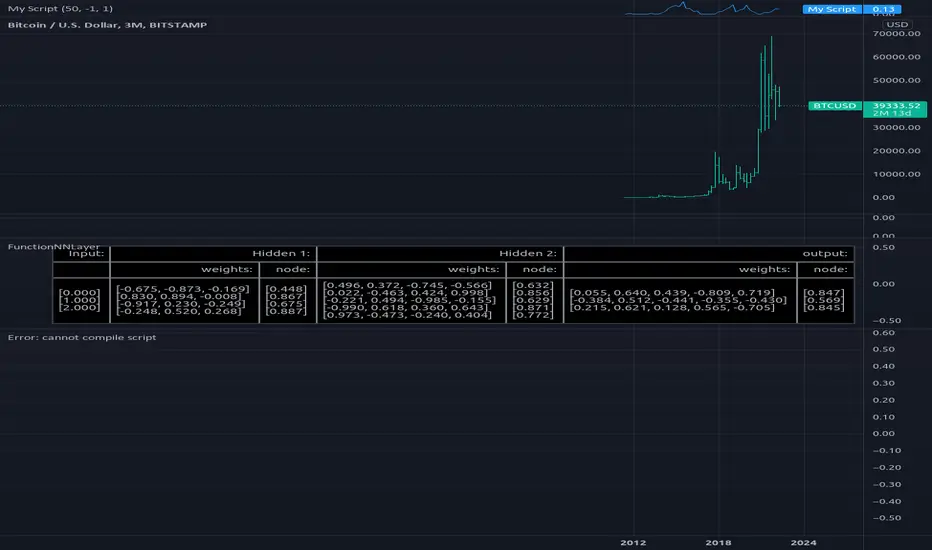
FunctionNNPerceptronLibrary "FunctionNNPerceptron"
Perceptron Function for Neural networks.
function(inputs, weights, bias, activation_function, alpha, scale) generalized perceptron node for Neural Networks.
Parameters:
inputs : float array, the inputs of the perceptron.
weights : float array, the weights for inputs.
bias : float, default=1.0, the default bias of the perceptron.
activation_function : string, default='sigmoid', activation function applied to the output.
alpha : float, default=na, if required for activation.
scale : float, default=na, if required for activation.
@outputs float
