Hodrick-Prescott Extrapolation of Price [Loxx]Hodrick-Prescott Extrapolation of Price is a Hodrick-Prescott filter used to extrapolate price.
The distinctive feature of the Hodrick-Prescott filter is that it does not delay. It is calculated by minimizing the objective function.
F = Sum((y(i) - x(i))^2,i=0..n-1) + lambda*Sum((y(i+1)+y(i-1)-2*y(i))^2,i=1..n-2)
where x() - prices, y() - filter values.
If the Hodrick-Prescott filter sees the future, then what future values does it suggest? To answer this question, we should find the digital low-frequency filter with the frequency parameter similar to the Hodrick-Prescott filter's one but with the values calculated directly using the past values of the "twin filter" itself, i.e.
y(i) = Sum(a(k)*x(i-k),k=0..nx-1) - FIR filter
or
y(i) = Sum(a(k)*x(i-k),k=0..nx-1) + Sum(b(k)*y(i-k),k=1..ny) - IIR filter
It is better to select the "twin filter" having the frequency-independent delay Тdel (constant group delay). IIR filters are not suitable. For FIR filters, the condition for a frequency-independent delay is as follows:
a(i) = +/-a(nx-1-i), i = 0..nx-1
The simplest FIR filter with constant delay is Simple Moving Average (SMA):
y(i) = Sum(x(i-k),k=0..nx-1)/nx
In case nx is an odd number, Тdel = (nx-1)/2. If we shift the values of SMA filter to the past by the amount of bars equal to Тdel, SMA values coincide with the Hodrick-Prescott filter ones. The exact math cannot be achieved due to the significant differences in the frequency parameters of the two filters.
To achieve the closest match between the filter values, I recommend their channel widths to be similar (for example, -6dB). The Hodrick-Prescott filter's channel width of -6dB is calculated as follows:
wc = 2*arcsin(0.5/lambda^0.25).
The channel width of -6dB for the SMA filter is calculated by numerical computing via the following equation:
|H(w)| = sin(nx*wc/2)/sin(wc/2)/nx = 0.5
Prediction algorithms:
The indicator features the two prediction methods:
Metod 1:
1. Set SMA length to 3 and shift it to the past by 1 bar. With such a length, the shifted SMA does not exist only for the last bar (Bar = 0), since it needs the value of the next future price Close(-1).
2. Calculate SMA filer's channel width. Equal it to the Hodrick-Prescott filter's one. Find lambda.
3. Calculate Hodrick-Prescott filter value at the last bar HP(0) and assume that SMA(0) with unknown Close(-1) gives the same value.
4. Find Close(-1) = 3*HP(0) - Close(0) - Close(1)
5. Increase the length of SMA to 5. Repeat all calculations and find Close(-2) = 5*HP(0) - Close(-1) - Close(0) - Close(1) - Close(2). Continue till the specified amount of future FutBars prices is calculated.
Method 2:
1. Set SMA length equal to 2*FutBars+1 and shift SMA to the past by FutBars
2. Calculate SMA filer's channel width. Equal it to the Hodrick-Prescott filter's one. Find lambda.
3. Calculate Hodrick-Prescott filter values at the last FutBars and assume that SMA behaves similarly when new prices appear.
4. Find Close(-1) = (2*FutBars+1)*HP(FutBars-1) - Sum(Close(i),i=0..2*FutBars-1), Close(-2) = (2*FutBars+1)*HP(FutBars-2) - Sum(Close(i),i=-1..2*FutBars-2), etc.
The indicator features the following inputs:
Method - prediction method
Last Bar - number of the last bar to check predictions on the existing prices (LastBar >= 0)
Past Bars - amount of previous bars the Hodrick-Prescott filter is calculated for (the more, the better, or at least PastBars>2*FutBars)
Future Bars - amount of predicted future values
The second method is more accurate but often has large spikes of the first predicted price. For our purposes here, this price has been filtered from being displayed in the chart. This is why method two starts its prediction 2 bars later than method 1. The described prediction method can be improved by searching for the FIR filter with the frequency parameter closer to the Hodrick-Prescott filter. For example, you may try Hanning, Blackman, Kaiser, and other filters with constant delay instead of SMA.
Related indicators
Itakura-Saito Autoregressive Extrapolation of Price
Helme-Nikias Weighted Burg AR-SE Extra. of Price
Weighted Burg AR Spectral Estimate Extrapolation of Price
Levinson-Durbin Autocorrelation Extrapolation of Price
Fourier Extrapolator of Price w/ Projection Forecast
Cari dalam skrip untuk "algo"

Real-Fast Fourier Transform of Price w/ Linear Regression [Loxx]Real-Fast Fourier Transform of Price w/ Linear Regression is a indicator that implements a Real-Fast Fourier Transform on Price and modifies the output by a measure of Linear Regression. The solid line is the Linear Regression Trend of the windowed data, The green/red line is the Real FFT of price.
What is the Discrete Fourier Transform?
In mathematics, the discrete Fourier transform (DFT) converts a finite sequence of equally-spaced samples of a function into a same-length sequence of equally-spaced samples of the discrete-time Fourier transform (DTFT), which is a complex-valued function of frequency. The interval at which the DTFT is sampled is the reciprocal of the duration of the input sequence. An inverse DFT is a Fourier series, using the DTFT samples as coefficients of complex sinusoids at the corresponding DTFT frequencies. It has the same sample-values as the original input sequence. The DFT is therefore said to be a frequency domain representation of the original input sequence. If the original sequence spans all the non-zero values of a function, its DTFT is continuous (and periodic), and the DFT provides discrete samples of one cycle. If the original sequence is one cycle of a periodic function, the DFT provides all the non-zero values of one DTFT cycle.
What is the Complex Fast Fourier Transform?
The complex Fast Fourier Transform algorithm transforms N real or complex numbers into another N complex numbers. The complex FFT transforms a real or complex signal x in the time domain into a complex two-sided spectrum X in the frequency domain. You must remember that zero frequency corresponds to n = 0, positive frequencies 0 < f < f_c correspond to values 1 ≤ n ≤ N/2 −1, while negative frequencies −fc < f < 0 correspond to N/2 +1 ≤ n ≤ N −1. The value n = N/2 corresponds to both f = f_c and f = −f_c. f_c is the critical or Nyquist frequency with f_c = 1/(2*T) or half the sampling frequency. The first harmonic X corresponds to the frequency 1/(N*T).
The complex FFT requires the list of values (resolution, or N) to be a power 2. If the input size if not a power of 2, then the input data will be padded with zeros to fit the size of the closest power of 2 upward.
What is Real-Fast Fourier Transform?
Has conditions similar to the complex Fast Fourier Transform value, except that the input data must be purely real. If the time series data has the basic type complex64, only the real parts of the complex numbers are used for the calculation. The imaginary parts are silently discarded.
Inputs:
src = source price
uselreg = whether you wish to modify output with linear regression calculation
Windowin = windowing period, restricted to powers of 2: "4", "8", "16", "32", "64", "128", "256", "512", "1024", "2048"
Treshold = to modified power output to fine tune signal
dtrendper = adjust regression calculation
barsback = move window backward from bar 0
mutebars = mute bar coloring for the range
Further reading:
Real-valued Fast Fourier Transform Algorithms IEEE Transactions on Acoustics, Speech, and Signal Processing, June 1987
Related indicators utilizing Fourier Transform
Fourier Extrapolator of Variety RSI w/ Bollinger Bands
Fourier Extrapolation of Variety Moving Averages
Fourier Extrapolator of Price w/ Projection Forecast

Phase Accumulation, Smoothed Williams %R Histogram [Loxx]Phase Accumulation, Smoothed Williams %R Histogram is a Williams %R indicator using dynamic inputs from Ehlers Phase Accumulation Dominant Cycle Period Algorithm. This indicator includes alerts and signals and is in a smoothed histogram form. The version of Phase Accumulation in this indicator is a modified form of of Ehlers algorithm to allow for better smoothing and cycle length selection.
What is Williams %R?
Williams %R , also known as the Williams Percent Range, is a type of momentum indicator that moves between 0 and -100 and measures overbought and oversold levels. The Williams %R may be used to find entry and exit points in the market. The indicator is very similar to the Stochastic oscillator and is used in the same way. It was developed by Larry Williams and it compares a stock’s closing price to the high-low range over a specific period, typically 14 days or periods.
What is Phase Accumulation?
The phase accumulation method of computing the dominant cycle is perhaps the easiest to comprehend. In this technique, we measure the phase at each sample by taking the arctangent of the ratio of the quadrature component to the in-phase component. A delta phase is generated by taking the difference of the phase between successive samples. At each sample we can then look backwards, adding up the delta phases.When the sum of the delta phases reaches 360 degrees, we must have passed through one full cycle, on average.The process is repeated for each new sample.
The phase accumulation method of cycle measurement always uses one full cycle’s worth of historical data.This is both an advantage and a disadvantage.The advantage is the lag in obtaining the answer scales directly with the cycle period.That is, the measurement of a short cycle period has less lag than the measurement of a longer cycle period. However, the number of samples used in making the measurement means the averaging period is variable with cycle period. longer averaging reduces the noise level compared to the signal.Therefore, shorter cycle periods necessarily have a higher out- put signal-to-noise ratio.
Included:
-Toggle on/off bar coloring
-Toggle on/off signals
-Alerts long/short
-Loxx's Expanded Source Types Library

Jurik DMX Histogram [Loxx]Jurik DMX Histogram is the ultra-smooth, low lag version of your classic DMI indicator.
What is the directional movement index?
The directional movement index (DMI) is an indicator developed by J. Welles Wilder in 1978 that identifies in which direction the price of an asset is moving. The indicator does this by comparing prior highs and lows and drawing two lines: a positive directional movement line (+DI) and a negative directional movement line (-DI). An optional third line, called the average directional index (ADX), can also be used to gauge the strength of the uptrend or downtrend.
When +DI is above -DI, there is more upward pressure than downward pressure in the price. Conversely, if -DI is above +DI, then there is more downward pressure on the price. This indicator may help traders assess the trend direction. Crossovers between the lines are also sometimes used as trade signals to buy or sell.
What is Jurik Volty used in the Juirk Filter?
One of the lesser known qualities of Juirk smoothing is that the Jurik smoothing process is adaptive. "Jurik Volty" (a sort of market volatility ) is what makes Jurik smoothing adaptive. The Jurik Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
What is the Jurik Moving Average?
Have you noticed how moving averages add some lag (delay) to your signals? ... especially when price gaps up or down in a big move, and you are waiting for your moving average to catch up? Wait no more! JMA eliminates this problem forever and gives you the best of both worlds: low lag and smooth lines.
Ideally, you would like a filtered signal to be both smooth and lag-free. Lag causes delays in your trades, and increasing lag in your indicators typically result in lower profits. In other words, late comers get what's left on the table after the feast has already begun.
What is an adaptive cycle, and what is Ehlers Autocorrelation Periodogram Algorithm?
From his Ehlers' book Cycle Analytics for Traders Advanced Technical Trading Concepts by John F. Ehlers , 2013, page 135:
"Adaptive filters can have several different meanings. For example, Perry Kaufman’s adaptive moving average ( KAMA ) and Tushar Chande’s variable index dynamic average ( VIDYA ) adapt to changes in volatility . By definition, these filters are reactive to price changes, and therefore they close the barn door after the horse is gone.The adaptive filters discussed in this chapter are the familiar Stochastic , relative strength index ( RSI ), commodity channel index ( CCI ), and band-pass filter.The key parameter in each case is the look-back period used to calculate the indicator. This look-back period is commonly a fixed value. However, since the measured cycle period is changing, it makes sense to adapt these indicators to the measured cycle period. When tradable market cycles are observed, they tend to persist for a short while.Therefore, by tuning the indicators to the measure cycle period they are optimized for current conditions and can even have predictive characteristics.
The dominant cycle period is measured using the Autocorrelation Periodogram Algorithm. That dominant cycle dynamically sets the look-back period for the indicators. I employ my own streamlined computation for the indicators that provide smoother and easier to interpret outputs than traditional methods. Further, the indicator codes have been modified to remove the effects of spectral dilation.This basically creates a whole new set of indicators for your trading arsenal."
Included
- Toggle on/off bar coloring
Adaptive, Jurik-Filtered, JMA/DWMA MACD [Loxx]Adaptive, Jurik-Filtered, JMA/DWMA MACD is MACD oscillator with a twist. The traditional calculation of MACD is the between two EMAs of price. This traditional approach yields a very noisy and lagged signal. To solve this problem, JMA/DWMA MACD uses the difference between adaptive Juirk-Filtered price and adaptive DWMA to yield a marked improvement over traditional MACD.
What is JMA / DWMA oscillator (MACD)?
Of all the different combinations of moving average filters to use for a MACD oscillator, we prefer using the JMA - DWMA combination.
JMA is ideal for the fast moving average line because it is quick to respond to reversals, is smooth and can be set to have no overshoot. DWMA (double weighted moving average) is ideal for the slower line as is tends to delay reversing direction until JMA crosses it.
What is Jurik Volty used in the Juirk Filter?
One of the lesser known qualities of Juirk smoothing is that the Jurik smoothing process is adaptive. "Jurik Volty" (a sort of market volatility ) is what makes Jurik smoothing adaptive. The Jurik Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
What is the Jurik Moving Average?
Have you noticed how moving averages add some lag (delay) to your signals? ... especially when price gaps up or down in a big move, and you are waiting for your moving average to catch up? Wait no more! JMA eliminates this problem forever and gives you the best of both worlds: low lag and smooth lines.
Ideally, you would like a filtered signal to be both smooth and lag-free. Lag causes delays in your trades, and increasing lag in your indicators typically result in lower profits. In other words, late comers get what's left on the table after the feast has already begun.
What is an adaptive cycle, and what is Ehlers Autocorrelation Periodogram Algorithm?
From his Ehlers' book Cycle Analytics for Traders Advanced Technical Trading Concepts by John F. Ehlers , 2013, page 135:
"Adaptive filters can have several different meanings. For example, Perry Kaufman’s adaptive moving average ( KAMA ) and Tushar Chande’s variable index dynamic average ( VIDYA ) adapt to changes in volatility . By definition, these filters are reactive to price changes, and therefore they close the barn door after the horse is gone.The adaptive filters discussed in this chapter are the familiar Stochastic , relative strength index ( RSI ), commodity channel index ( CCI ), and band-pass filter.The key parameter in each case is the look-back period used to calculate the indicator. This look-back period is commonly a fixed value. However, since the measured cycle period is changing, it makes sense to adapt these indicators to the measured cycle period. When tradable market cycles are observed, they tend to persist for a short while.Therefore, by tuning the indicators to the measure cycle period they are optimized for current conditions and can even have predictive characteristics.
The dominant cycle period is measured using the Autocorrelation Periodogram Algorithm. That dominant cycle dynamically sets the look-back period for the indicators. I employ my own streamlined computation for the indicators that provide smoother and easier to interpret outputs than traditional methods. Further, the indicator codes have been modified to remove the effects of spectral dilation.This basically creates a whole new set of indicators for your trading arsenal."
Included
- Toggle on/off bar coloring

Adaptive, Jurik-Filtered, Floating RSI [Loxx]Adaptive, Jurik-Filtered, Floating RSI is an adaptive RSI indicator that smooths the RSI signal with a Jurik Filter.
This indicator contains three different types of RSI. They are following.
Wilders' RSI:
The Relative Strength Index ( RSI ) is a well versed momentum based oscillator which is used to measure the speed (velocity) as well as the change (magnitude) of directional price movements. Essentially RSI , when graphed, provides a visual mean to monitor both the current, as well as historical, strength and weakness of a particular market. The strength or weakness is based on closing prices over the duration of a specified trading period creating a reliable metric of price and momentum changes. Given the popularity of cash settled instruments (stock indexes) and leveraged financial products (the entire field of derivatives); RSI has proven to be a viable indicator of price movements.
RSX RSI:
RSI is a very popular technical indicator, because it takes into consideration market speed, direction and trend uniformity. However, the its widely criticized drawback is its noisy (jittery) appearance. The Jurk RSX retains all the useful features of RSI , but with one important exception: the noise is gone with no added lag.
Rapid RSI:
Rapid RSI Indicator, from Ian Copsey's article in the October 2006 issue of Stocks & Commodities magazine.
RapidRSI resembles Wilder's RSI , but uses a SMA instead of a WilderMA for internal smoothing of price change accumulators.
This indicator also uses adaptive cycles to calculate input lengths
What is an adaptive cycle, and what is Ehlers Autocorrelation Periodogram Algorithm?
From his Ehlers' book Cycle Analytics for Traders Advanced Technical Trading Concepts by John F. Ehlers , 2013, page 135:
"Adaptive filters can have several different meanings. For example, Perry Kaufman’s adaptive moving average ( KAMA ) and Tushar Chande’s variable index dynamic average ( VIDYA ) adapt to changes in volatility . By definition, these filters are reactive to price changes, and therefore they close the barn door after the horse is gone.The adaptive filters discussed in this chapter are the familiar Stochastic , relative strength index ( RSI ), commodity channel index ( CCI ), and band-pass filter.The key parameter in each case is the look-back period used to calculate the indicator. This look-back period is commonly a fixed value. However, since the measured cycle period is changing, it makes sense to adapt these indicators to the measured cycle period. When tradable market cycles are observed, they tend to persist for a short while.Therefore, by tuning the indicators to the measure cycle period they are optimized for current conditions and can even have predictive characteristics.
The dominant cycle period is measured using the Autocorrelation Periodogram Algorithm. That dominant cycle dynamically sets the look-back period for the indicators. I employ my own streamlined computation for the indicators that provide smoother and easier to interpret outputs than traditional methods. Further, the indicator codes have been modified to remove the effects of spectral dilation.This basically creates a whole new set of indicators for your trading arsenal."
Lastly, RSI is filtered and smoothed using a Jurik Filter
What is Jurik Volty?
One of the lesser known qualities of Juirk smoothing is that the Jurik smoothing process is adaptive. "Jurik Volty" (a sort of market volatility ) is what makes Jurik smoothing adaptive. The Jurik Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
What is the Jurik Moving Average?
Have you noticed how moving averages add some lag (delay) to your signals? ... especially when price gaps up or down in a big move, and you are waiting for your moving average to catch up? Wait no more! JMA eliminates this problem forever and gives you the best of both worlds: low lag and smooth lines.
Ideally, you would like a filtered signal to be both smooth and lag-free. Lag causes delays in your trades, and increasing lag in your indicators typically result in lower profits. In other words, late comers get what's left on the table after the feast has already begun.
Usage
-Red fill color when RSI is in overbought zone means a possible bear trend is incoming
-Green fill color when RSI is in overbought zone means a possible bear trend is incoming
Included
-Bar coloring
Adaptive Jurik Filter MACD [Loxx]Adaptive Jurik Filter MACD uses Jurik Volty and Adaptive Double Jurik Filter Moving Average (AJFMA) to derive Jurik Filter smoothed volatility.
What is MACD?
Moving average convergence divergence (MACD) is a trend-following momentum indicator that shows the relationship between two moving averages of a security’s price. The MACD is calculated by subtracting the 26-period exponential moving average (EMA) from the 12-period EMA.
The result of that calculation is the MACD line. A nine-day EMA of the MACD called the "signal line," is then plotted on top of the MACD line, which can function as a trigger for buy and sell signals. Traders may buy the security when the MACD crosses above its signal line and sell—or short—the security when the MACD crosses below the signal line. Moving average convergence divergence (MACD) indicators can be interpreted in several ways, but the more common methods are crossovers, divergences, and rapid rises/falls.
What is Jurik Volty?
One of the lesser known qualities of Juirk smoothing is that the Jurik smoothing process is adaptive. "Jurik Volty" (a sort of market volatility ) is what makes Jurik smoothing adaptive. The Jurik Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
What is the Jurik Moving Average?
Have you noticed how moving averages add some lag (delay) to your signals? ... especially when price gaps up or down in a big move, and you are waiting for your moving average to catch up? Wait no more! JMA eliminates this problem forever and gives you the best of both worlds: low lag and smooth lines.
Ideally, you would like a filtered signal to be both smooth and lag-free. Lag causes delays in your trades, and increasing lag in your indicators typically result in lower profits. In other words, late comers get what's left on the table after the feast has already begun.
That's why investors, banks and institutions worldwide ask for the Jurik Research Moving Average ( JMA ). You may apply it just as you would any other popular moving average. However, JMA's improved timing and smoothness will astound you.
What is adaptive Jurik volatility?
One of the lesser known qualities of Juirk smoothing is that the Jurik smoothing process is adaptive. "Jurik Volty" (a sort of market volatility ) is what makes Jurik smoothing adaptive. The Jurik Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
What is an adaptive cycle, and what is Ehlers Autocorrelation Periodogram Algorithm?
From his Ehlers' book Cycle Analytics for Traders Advanced Technical Trading Concepts by John F. Ehlers , 2013, page 135:
"Adaptive filters can have several different meanings. For example, Perry Kaufman’s adaptive moving average ( KAMA ) and Tushar Chande’s variable index dynamic average ( VIDYA ) adapt to changes in volatility . By definition, these filters are reactive to price changes, and therefore they close the barn door after the horse is gone.The adaptive filters discussed in this chapter are the familiar Stochastic , relative strength index ( RSI ), commodity channel index ( CCI ), and band-pass filter.The key parameter in each case is the look-back period used to calculate the indicator. This look-back period is commonly a fixed value. However, since the measured cycle period is changing, it makes sense to adapt these indicators to the measured cycle period. When tradable market cycles are observed, they tend to persist for a short while.Therefore, by tuning the indicators to the measure cycle period they are optimized for current conditions and can even have predictive characteristics.
The dominant cycle period is measured using the Autocorrelation Periodogram Algorithm. That dominant cycle dynamically sets the look-back period for the indicators. I employ my own streamlined computation for the indicators that provide smoother and easier to interpret outputs than traditional methods. Further, the indicator codes have been modified to remove the effects of spectral dilation.This basically creates a whole new set of indicators for your trading arsenal."
Included
- Change colors of oscillators and bars

Adaptive Jurik Filter Volatility Oscillator [Loxx]Adaptive Jurik Filter Volatility Oscillator uses Jurik Volty and Adaptive Double Jurik Filter Moving Average (AJFMA) to derive Jurik Filter smoothed volatility.
What is Jurik Volty?
One of the lesser known qualities of Juirk smoothing is that the Jurik smoothing process is adaptive. "Jurik Volty" (a sort of market volatility ) is what makes Jurik smoothing adaptive. The Jurik Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
What is the Jurik Moving Average?
Have you noticed how moving averages add some lag (delay) to your signals? ... especially when price gaps up or down in a big move, and you are waiting for your moving average to catch up? Wait no more! JMA eliminates this problem forever and gives you the best of both worlds: low lag and smooth lines.
Ideally, you would like a filtered signal to be both smooth and lag-free. Lag causes delays in your trades, and increasing lag in your indicators typically result in lower profits. In other words, late comers get what's left on the table after the feast has already begun.
That's why investors, banks and institutions worldwide ask for the Jurik Research Moving Average ( JMA ). You may apply it just as you would any other popular moving average. However, JMA's improved timing and smoothness will astound you.
What is adaptive Jurik volatility?
One of the lesser known qualities of Juirk smoothing is that the Jurik smoothing process is adaptive. "Jurik Volty" (a sort of market volatility ) is what makes Jurik smoothing adaptive. The Jurik Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
What is an adaptive cycle, and what is Ehlers Autocorrelation Periodogram Algorithm?
From his Ehlers' book Cycle Analytics for Traders Advanced Technical Trading Concepts by John F. Ehlers , 2013, page 135:
"Adaptive filters can have several different meanings. For example, Perry Kaufman’s adaptive moving average ( KAMA ) and Tushar Chande’s variable index dynamic average ( VIDYA ) adapt to changes in volatility . By definition, these filters are reactive to price changes, and therefore they close the barn door after the horse is gone.The adaptive filters discussed in this chapter are the familiar Stochastic , relative strength index ( RSI ), commodity channel index ( CCI ), and band-pass filter.The key parameter in each case is the look-back period used to calculate the indicator. This look-back period is commonly a fixed value. However, since the measured cycle period is changing, it makes sense to adapt these indicators to the measured cycle period. When tradable market cycles are observed, they tend to persist for a short while.Therefore, by tuning the indicators to the measure cycle period they are optimized for current conditions and can even have predictive characteristics.
The dominant cycle period is measured using the Autocorrelation Periodogram Algorithm. That dominant cycle dynamically sets the look-back period for the indicators. I employ my own streamlined computation for the indicators that provide smoother and easier to interpret outputs than traditional methods. Further, the indicator codes have been modified to remove the effects of spectral dilation.This basically creates a whole new set of indicators for your trading arsenal."
Included
- UI options to color bars
Adaptive Jurik Filter Volatility Bands [Loxx]Adaptive Jurik Filter Volatility Bands uses Jurik Volty and Adaptive, Double Jurik Filter Moving Average (AJFMA) to derive Jurik Filter smoothed volatility channels around an Adaptive Jurik Filter Moving Average. Bands are placed at 1, 2, and 3 deviations from the core basline.
What is Jurik Volty?
One of the lesser known qualities of Juirk smoothing is that the Jurik smoothing process is adaptive. "Jurik Volty" (a sort of market volatility ) is what makes Jurik smoothing adaptive. The Jurik Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
What is the Jurik Moving Average?
Have you noticed how moving averages add some lag (delay) to your signals? ... especially when price gaps up or down in a big move, and you are waiting for your moving average to catch up? Wait no more! JMA eliminates this problem forever and gives you the best of both worlds: low lag and smooth lines.
Ideally, you would like a filtered signal to be both smooth and lag-free. Lag causes delays in your trades, and increasing lag in your indicators typically result in lower profits. In other words, late comers get what's left on the table after the feast has already begun.
That's why investors, banks and institutions worldwide ask for the Jurik Research Moving Average ( JMA ). You may apply it just as you would any other popular moving average. However, JMA's improved timing and smoothness will astound you.
What is adaptive Jurik volatility?
One of the lesser known qualities of Juirk smoothing is that the Jurik smoothing process is adaptive. "Jurik Volty" (a sort of market volatility ) is what makes Jurik smoothing adaptive. The Jurik Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
What is an adaptive cycle, and what is Ehlers Autocorrelation Periodogram Algorithm?
From his Ehlers' book Cycle Analytics for Traders Advanced Technical Trading Concepts by John F. Ehlers , 2013, page 135:
"Adaptive filters can have several different meanings. For example, Perry Kaufman’s adaptive moving average ( KAMA ) and Tushar Chande’s variable index dynamic average ( VIDYA ) adapt to changes in volatility . By definition, these filters are reactive to price changes, and therefore they close the barn door after the horse is gone.The adaptive filters discussed in this chapter are the familiar Stochastic , relative strength index ( RSI ), commodity channel index ( CCI ), and band-pass filter.The key parameter in each case is the look-back period used to calculate the indicator. This look-back period is commonly a fixed value. However, since the measured cycle period is changing, it makes sense to adapt these indicators to the measured cycle period. When tradable market cycles are observed, they tend to persist for a short while.Therefore, by tuning the indicators to the measure cycle period they are optimized for current conditions and can even have predictive characteristics.
The dominant cycle period is measured using the Autocorrelation Periodogram Algorithm. That dominant cycle dynamically sets the look-back period for the indicators. I employ my own streamlined computation for the indicators that provide smoother and easier to interpret outputs than traditional methods. Further, the indicator codes have been modified to remove the effects of spectral dilation.This basically creates a whole new set of indicators for your trading arsenal."
Included
- UI options to shut off colors and bands
Adaptive, Jurik-Smoothed, Trend Continuation Factor [Loxx]Adaptive, Jurik-Smoothed, Trend Continuation Factor is a Trend Continuation Factor indicator with adaptive length and volatility inputs
What is the Trend Continuation Factor?
The Trend Continuation Factor (TCF) identifies the trend and its direction. TCF was introduced by M. H. Pee. Positive values of either the Positive Trend Continuation Factor (TCF+) and the Negative Trend Continuation Factor (TCF-) indicate the presence of a strong trend.
What is the Jurik Moving Average?
Have you noticed how moving averages add some lag (delay) to your signals? ... especially when price gaps up or down in a big move, and you are waiting for your moving average to catch up? Wait no more! JMA eliminates this problem forever and gives you the best of both worlds: low lag and smooth lines.
Ideally, you would like a filtered signal to be both smooth and lag-free. Lag causes delays in your trades, and increasing lag in your indicators typically result in lower profits. In other words, late comers get what's left on the table after the feast has already begun.
That's why investors, banks and institutions worldwide ask for the Jurik Research Moving Average ( JMA ). You may apply it just as you would any other popular moving average. However, JMA's improved timing and smoothness will astound you.
What is adaptive Jurik volatility?
One of the lesser known qualities of Juirk smoothing is that the Jurik smoothing process is adaptive. "Jurik Volty" (a sort of market volatility ) is what makes Jurik smoothing adaptive. The Jurik Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
What is an adaptive cycle, and what is Ehlers Autocorrelation Periodogram Algorithm?
From his Ehlers' book Cycle Analytics for Traders Advanced Technical Trading Concepts by John F. Ehlers , 2013, page 135:
"Adaptive filters can have several different meanings. For example, Perry Kaufman’s adaptive moving average ( KAMA ) and Tushar Chande’s variable index dynamic average ( VIDYA ) adapt to changes in volatility . By definition, these filters are reactive to price changes, and therefore they close the barn door after the horse is gone.The adaptive filters discussed in this chapter are the familiar Stochastic , relative strength index ( RSI ), commodity channel index ( CCI ), and band-pass filter.The key parameter in each case is the look-back period used to calculate the indicator. This look-back period is commonly a fixed value. However, since the measured cycle period is changing, it makes sense to adapt these indicators to the measured cycle period. When tradable market cycles are observed, they tend to persist for a short while.Therefore, by tuning the indicators to the measure cycle period they are optimized for current conditions and can even have predictive characteristics.
The dominant cycle period is measured using the Autocorrelation Periodogram Algorithm. That dominant cycle dynamically sets the look-back period for the indicators. I employ my own streamlined computation for the indicators that provide smoother and easier to interpret outputs than traditional methods. Further, the indicator codes have been modified to remove the effects of spectral dilation.This basically creates a whole new set of indicators for your trading arsenal."
Included
-Your choice of length input calculation, either fixed or adaptive cycle
-Bar coloring to paint the trend
Happy trading!

Adaptive Look-back/Volatility Phase Change Index on Jurik [Loxx]Adaptive Look-back, Adaptive Volatility Phase Change Index on Jurik is a Phase Change Index but with adaptive length and volatility inputs to reduce phase change noise and better identify trends. This is an invese indicator which means that small values on the oscillator indicate bullish sentiment and higher values on the oscillator indicate bearish sentiment
What is the Phase Change Index?
Based on the M.H. Pee's TASC article "Phase Change Index".
Prices at any time can be up, down, or unchanged. A period where market prices remain relatively unchanged is referred to as a consolidation. A period that witnesses relatively higher prices is referred to as an uptrend, while a period of relatively lower prices is called a downtrend.
The Phase Change Index (PCI) is an indicator designed specifically to detect changes in market phases.
This indicator is made as he describes it with one deviation: if we follow his formula to the letter then the "trend" is inverted to the actual market trend. Because of that an option to display inverted (and more logical) values is added.
What is the Jurik Moving Average?
Have you noticed how moving averages add some lag (delay) to your signals? ... especially when price gaps up or down in a big move, and you are waiting for your moving average to catch up? Wait no more! JMA eliminates this problem forever and gives you the best of both worlds: low lag and smooth lines.
Ideally, you would like a filtered signal to be both smooth and lag-free. Lag causes delays in your trades, and increasing lag in your indicators typically result in lower profits. In other words, late comers get what's left on the table after the feast has already begun.
That's why investors, banks and institutions worldwide ask for the Jurik Research Moving Average ( JMA ). You may apply it just as you would any other popular moving average. However, JMA's improved timing and smoothness will astound you.
What is adaptive Jurik volatility
One of the lesser known qualities of Juirk smoothing is that the Jurik smoothing process is adaptive. "Jurik Volty" (a sort of market volatility ) is what makes Jurik smoothing adaptive. The Jurik Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
What is an adaptive cycle, and what is Ehlers Autocorrelation Periodogram Algorithm?
From his Ehlers' book Cycle Analytics for Traders Advanced Technical Trading Concepts by John F. Ehlers, 2013, page 135:
"Adaptive filters can have several different meanings. For example, Perry Kaufman’s adaptive moving average (KAMA) and Tushar Chande’s variable index dynamic average (VIDYA) adapt to changes in volatility. By definition, these filters are reactive to price changes, and therefore they close the barn door after the horse is gone.The adaptive filters discussed in this chapter are the familiar Stochastic, relative strength index (RSI), commodity channel index (CCI), and band-pass filter.The key parameter in each case is the look-back period used to calculate the indicator. This look-back period is commonly a fixed value. However, since the measured cycle period is changing, it makes sense to adapt these indicators to the measured cycle period. When tradable market cycles are observed, they tend to persist for a short while.Therefore, by tuning the indicators to the measure cycle period they are optimized for current conditions and can even have predictive characteristics.
The dominant cycle period is measured using the Autocorrelation Periodogram Algorithm. That dominant cycle dynamically sets the look-back period for the indicators. I employ my own streamlined computation for the indicators that provide smoother and easier to interpret outputs than traditional methods. Further, the indicator codes have been modified to remove the effects of spectral dilation.This basically creates a whole new set of indicators for your trading arsenal."
Included
-Your choice of length input calculation, either fixed or adaptive cycle
-Invert the signal to match the trend
-Bar coloring to paint the trend
Happy trading!
Adaptive MA Difference constructor [lastguru]A complimentary indicator to my Adaptive MA constructor. It calculates the difference between the two MA lines (inspired by the Moving Average Difference (MAD) indicator by John F. Ehlers). You can then further smooth the resulting curve. The parameters and options are explained here:
The difference is normalized by dividing the difference by twice its Root mean square (RMS) over Slow MA length. Inverse Fisher Transform is then used to force the -1..1 range.
Same Postfilter options are provided as in my Adaptive Oscillator constructor:
Stochastic - Stochastic
Super Smooth Stochastic - Super Smooth Stochastic (part of MESA Stochastic ) by John F. Ehlers
Inverse Fisher Transform - Inverse Fisher Transform
Noise Elimination Technology - a simplified Kendall correlation algorithm "Noise Elimination Technology" by John F. Ehlers
Momentum - momentum (derivative)
Except for Inverse Fisher Transform, all Postfilter algorithms can have Length parameter. If it is not specified (set to 0), then the calculated Slow MA Length is used.
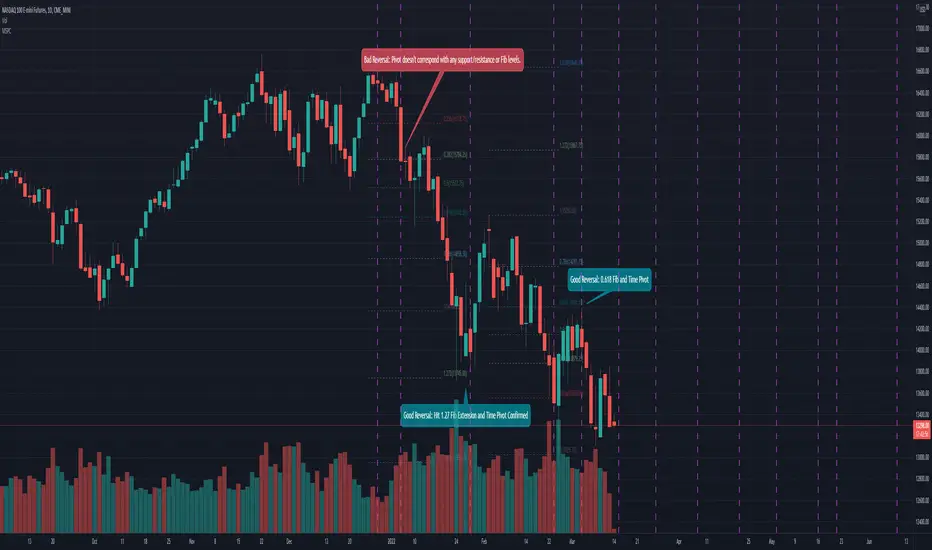
Mean Shift Pivot ClusteringCore Concepts
According to Jeff Greenblatt in his book "Breakthrough Strategies for Predicting Any Market", Fibonacci and Lucas sequences are observed repeated in the bar counts from local pivot highs/lows. They occur from high to high, low to high, high to low, or low to high. Essentially, this phenomenon is observed repeatedly from any pivot points on any time frame. Greenblatt combines this observation with Elliott Waves to predict the price and time reversals. However, I am no Elliottician so it was not easy for me to use this in a practical manner. I decided to only use the bar count projections and ignore the price. I projected a subset of Fibonacci and Lucas sequences along with the Fibonacci ratios from each pivot point. As expected, a projection from each pivot point resulted in a large set of plotted data and looks like a huge gong show of lines. Surprisingly, I did notice clusters and have observed those clusters to be fairly accurate.
Fibonacci Sequence: 1, 2, 3, 5, 8, 13, 21, 34...
Lucas Sequence: 2, 1, 3, 4, 7, 11, 18, 29, 47...
Fibonacci Ratios (converted to whole numbers): 23, 38, 50, 61, 78, 127, 161...
Light Bulb Moment
My eyes may suck at grouping the lines together but what about clustering algorithms? I chose to use a gimped version of Mean Shift because it doesn't require me to know in advance how many lines to expect like K-Means. Mean shift is computationally expensive and with Pinescript's 500ms timeout, I had to make due without the KDE. In other words, I skipped the weighting part but I may try to incorporate it in the future. The code is from Harrison Kinsley . He's a fantastic teacher!
Usage
Search Radius: how far apart should the bars be before they are excluded from the cluster? Try to stick with a figure between 1-5. Too large a figure will give meaningless results.
Pivot Offset: looks left and right X number of bars for a pivot. Same setting as the default TradingView pivot high/low script.
Show Lines Back: show historical predicted lines. (These can change)
Use this script in conjunction with Fibonacci price retracement/extension levels and/or other support/resistance levels. If it's no where near a support/resistance and there's a projected time pivot coming up, it's probably a fake out.
Notes
Re-painting is intended. When a new pivot is found, it will project out the Fib/Lucas sequences so the algorithm will run again with additional information.
The script is for informational and educational purposes only.
Do not use this indicator by itself to trade!
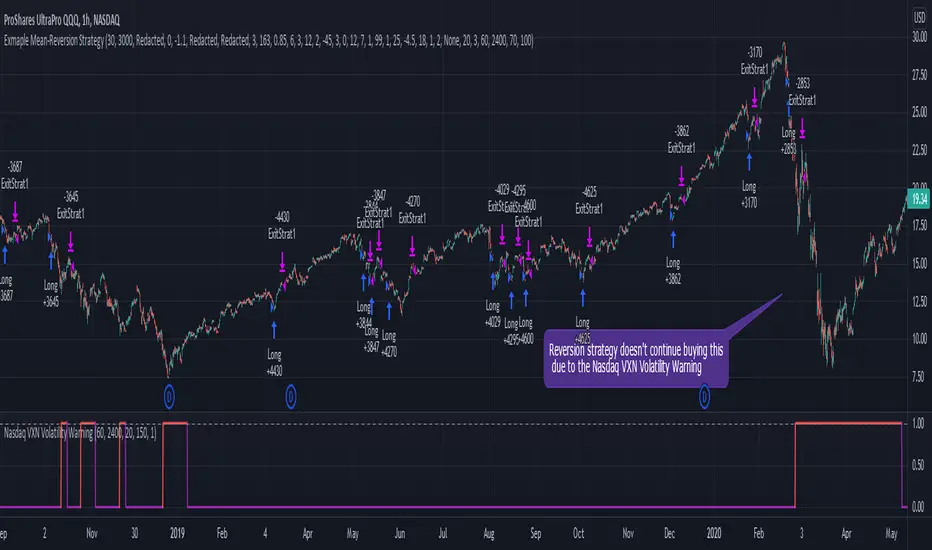
Nasdaq VXN Volatility Warning IndicatorToday I am sharing with the community a volatility indicator that uses the Nasdaq VXN Volatility Index to help you or your algorithms avoid black swan events. This is a similar the indicator I published last week that uses the SP500 VIX, but this indicator uses the Nasdaq VXN and can help inform strategies on the Nasdaq index or Nasdaq derivative instruments.
Variance is most commonly used in statistics to derive standard deviation (with its square root). It does have another practical application, and that is to identify outliers in a sample of data. Variance is defined as the squared difference between a value and its mean. Calculating that squared difference means that the farther away the value is from the mean, the more the variance will grow (exponentially). This exponential difference makes outliers in the variance data more apparent.
Why does this matter?
There are assets or indices that exist in the stock market that might make us adjust our trading strategy if they are behaving in an unusual way. In some instances, we can use variance to identify that behavior and inform our strategy.
Is that really possible?
Let’s look at the relationship between VXN and the Nasdaq100 as an example. If you trade a Nasdaq index with a mean reversion strategy or algorithm, you know that they typically do best in times of volatility . These strategies essentially attempt to “call bottom” on a pullback. Their downside is that sometimes a pullback turns into a regime change, or a black swan event. The other downside is that there is no logical tight stop that actually increases their performance, so when they lose they tend to lose big.
So that begs the question, how might one quantitatively identify if this dip could turn into a regime change or black swan event?
The Nasdaq Volatility Index ( VXN ) uses options data to identify, on a large scale, what investors overall expect the market to do in the near future. The Volatility Index spikes in times of uncertainty and when investors expect the market to go down. However, during a black swan event, historically the VXN has spiked a lot harder. We can use variance here to identify if a spike in the VXN exceeds our threshold for a normal market pullback, and potentially avoid entering trades for a period of time (I.e. maybe we don’t buy that dip).
Does this actually work?
In backtesting, this cut the drawdown of my index reversion strategies in half. It also cuts out some good trades (because high investor fear isn’t always indicative of a regime change or black swan event). But, I’ll happily lose out on some good trades in exchange for half the drawdown. Lets look at some examples of periods of time that trades could have been avoided using this strategy/indicator:
Example 1 – With the Volatility Warning Indicator, the mean reversion strategy could have avoided repeatedly buying this pullback that led to this asset losing over 75% of its value:
Example 2 - June 2018 to June 2019 - With the Volatility Warning Indicator, the drawdown during this period reduces from 22% to 11%, and the overall returns increase from -8% to +3%
How do you use this indicator?
This indicator determines the variance of VXN against a long term mean. If the variance of the VXN spikes over an input threshold, the indicator goes up. The indicator will remain up for a defined period of bars/time after the variance returns below the threshold. I have included default values I’ve found to be significant for a short-term mean-reversion strategy, but your inputs might depend on your risk tolerance and strategy time-horizon. The default values are for 1hr VXN data/charts. It will pull in variance data for the VXN regardless of which chart the indicator is applied to.
Disclaimer: Open-source scripts I publish in the community are largely meant to spark ideas or be used as building blocks for part of a more robust trade management strategy. If you would like to implement a version of any script, I would recommend making significant additions/modifications to the strategy & risk management functions. If you don’t know how to program in Pine, then hire a Pine-coder. We can help!
S&P500 VIX Volatility Warning IndicatorToday I am sharing with the community a volatility indicator that can help you or your algorithms avoid black swan events. Variance is most commonly used in statistics to derive standard deviation (with its square root). It does have another practical application, and that is to identify outliers in a sample of data. Variance in statistics is defined as the squared difference between a value and its mean. Calculating that squared difference means that the farther away the value is from the mean, the more the variance will grow (exponentially). This exponential difference makes outliers in the variance data more apparent.
Why does this matter?
There are assets or indices that exist in the stock market that might make us adjust our trading strategy if they are behaving in an unusual way. In some instances, we can use variance to identify that behavior and inform our strategy.
Is that really possible?
Let’s look at the relationship between VIX and the S&P500 as an example. If you trade an S&P500 index with a mean reversion strategy or algorithm, you know that they typically do best in times of volatility. These strategies essentially attempt to “call bottom” on a pullback. Their downside is that sometimes a pullback turns into a regime change, or a black swan event. The other downside is that there is no logical tight stop that actually increases their performance, so when they lose they tend to lose big.
So that begs the question, how might one quantitatively identify if this dip could turn into a regime change or black swan event?
The CBOE Volatility Index (VIX) uses options data to identify, on a large scale, what investors overall expect the market to do in the near future. The Volatility Index spikes in times of uncertainty and when investors expect the market to go down. However, during a black swan event, the VIX spikes a lot harder. We can use variance here to identify if a spike in the VIX exceeds our threshold for a normal market pullback, and potentially avoid entering trades for a period of time (I.e. maybe we don’t buy that dip).
Does this actually work?
In backtesting, this cut the drawdown of my index reversion strategies in half. It also cuts out some good trades (because high investor fear isn’t always indicative of a regime change or black swan event). But, I’ll happily lose out on some good trades in exchange for half the drawdown. Lets look at some examples of periods of time that trades could have been avoided using this strategy/indicator:
Example 1 – With the Volatility Warning Indicator, the mean reversion strategy could have avoided repeatedly buying this pullback that led to SPXL losing over 75% of its value:
Example 2 - June 2018 to June 2019 - With the Volatility Warning Indicator, the drawdown during this period reduces from 22% to 11%, and the overall returns increase from -8% to +3%
How do you use this indicator?
This indicator determines the variance of the VIX against a long term mean. If the variance of the VIX spikes over an input threshold, the indicator goes up. The indicator will remain up for a defined period of bars/time after the variance returns below the threshold. I have included default values I’ve found to be significant for a short-term mean-reversion strategy, but your inputs might depend on your risk tolerance and strategy time-horizon. The default values are for 1hr VIX data. It will pull in variance data for the VIX regardless of which chart the indicator is applied to.
Disclaimer : Open-source scripts I publish in the community are largely meant to spark ideas or be used as building blocks for part of a more robust trade management strategy. If you would like to implement a version of any script, I would recommend making significant additions/modifications to the strategy & risk management functions. If you don’t know how to program in Pine, then hire a Pine-coder. We can help!

Total VolumeThis simple indicator unifies the volumes of multiple exchanges/brokers. The idea of this indicator stems from the need to monitor the movements made by whales on other markets that can actually influence the price (manipulations, arbitrage, etc.).
Basically, we can:
* choose the number and symbols
* choose with which algorithm to merge the volumes (sum, average, weighted average, maximum)
* color the histogram (based on the dominant exchange, classic green/red color, no color)
Furthermore, there is a summary table which, in addition to indicating the volume for each exchange, also indicates the color attributed.
you can see the volume of the current exchange behind the volume obtained by the algorithm.
If you have any questions, doubts or suggestions please write to me.

Pulu's Moving AveragesPulu's Moving Averages
This script allows you to customize sets of moving averages. It is configured default as 3 Vegas tunnels + an MA12. You can re-configure it for any of your moving average studies. At the first release, it supports up to 7 moving averages, many parameters, and eight types of algorithms:
ALMA, Arnaud Legoux Moving Average
EMA, Exponential Moving Average
RMA, Adjusted exponential moving average (aka Wilder’s EMA)
SMA, Simple Moving Average
SWMA, Symmetrically-Weighted Moving Average
VWAP, Volume-Weighted Average Price
VWMA, Volume-Weighted Moving Average
WMA, Weighted Moving Average
If you are looking for only 3 moving averages, there is another script "Pulu's 3 Moving Averages".
Vigia blai5VIGÍA is the latest and current version of this weighted indicator that collects, combines and harmonizes the values of four other classic indicators: RSI, MFI, Bollinger Bands and Stochastic.
It is a 2nd Generation indicator, as it does not base its algorithm on pure price data, but on its evolution (volatility, volume differences, power variations, cycle phase ...) working from first generation indicators included and mixed in the algorithm.
With the RSI we detect current power or depletion; the MFI adds the harmonization between price and volume; Bollinger Bands warn us of positions in areas close to support and resistance, and Stochastic informs us of the favorable and unfavorable phases of its cycle. VIGÍA tries to gather all this information in a single value and signal. This is how the curve of this indicator emerges.
The layout of this curve is its own and different from that of the other four separately. But the key idea of this complex indicator is to harmonize the signals.
By "harmonizing" we mean that an exaggerated value of one of the individual indicators, being part of a set, is nuanced. On the other hand, a simultaneous good look in two or more, enhances the resulting signal making it more visible and clear for trading.
One of the main effects that I have tried to enhance in the various versions of VIGÍA is its geometry, so one of the best ways to operate the indicator is divergences, which are generally quite reliable.
But, unlike so many conventional indicators, VIGÍA allows us a relatively large number of operations, which can satisfy both lovers of the most daring techniques and those who are more prudent in their trading.
In the first place, the black line is properly the Watch Signal (SV), the soul and central element of this entire invention.
On it you will see that a red line is oscillating. It is an Exponential Average of the indicator itself (by default, value 20). It is of enormous interest for trading since the SV cuts on its Average can be taken as entry and exit signals. (To check it, you just have to check it on the history of any value or index).
But there are more elements. An important change is the transformation of fixed levels into variable trading bands. This system allows the environment to adapt to changes in the asset price, recognizing and transforming itself according to the trend or laterality phases through which it runs. The signal moves above and below a central zero value and (as always) with no extreme limits, because it is important to remember that VIGÍA is not an oscillator and that prevents it from reaching a predefined extreme and being 'keyed in'.
On the upper variable band, we enter the overload zone, in Vigía's own jargon, while under the lower variable band, the situation of the indicator is on discharge. It is interesting to observe how, precisely the crossing of these variable bands by Vigía coincides on many occasions with the fastest and most productive phase of the entire price shift, far from concepts that in this phase we should already abandon as outdated and unreliable such as "overbought" or "oversold."
The last two elements remain to be described: a timid blue dashed line and that flickering central area of color called the Astro.
The blue dashed line is named Filter. It is a much more useful element than its smooth and modest journey appears. The Filter has some really fascinating features. Notice, for example, that it is the only line that I keep in visible numerical value, to know exactly when it has a positive and negative value. In periods of laterality, it is a good ally to help us make decisions. It does more things, but that is a prize reserved for whoever pays some attention to it… :-))
We will finish by Astro. Astro is an indicator with its own personality that I designed separately, it is available independently, but I ended up incorporating it into Watcher, which also happens with the Medium Proportional Volume (MPV). Both can be presented or hidden, according to the tastes or needs of the user.
Astro is an adjustable trend indicator, a very useful little tool that will help us identify the critical points where we must consider entries or changes in position. Its default value is 8 cycles, which is a good fit for daily stocks, but I have left open the possibility of modifying its period to be able to take advantage of all its power in intraday temporalities. Once again, I invite you to DO NOT believe me, but to launch the indicator on any asset and evaluate the signals that Astro has offered on its history.
VWMA with kNN Machine Learning: MFI/ADXThis is an experimental strategy that uses a Volume-weighted MA (VWMA) crossing together with Machine Learning kNN filter that uses ADX and MFI to predict, whether the signal is useful. k-nearest neighbours (kNN) is one of the simplest Machine Learning classification algorithms: it puts input parameters in a multidimensional space, and then when a new set of parameters are given, it makes a prediction based on plurality vote of its k neighbours.
Money Flow Index (MFI) is an oscillator similar to RSI, but with volume taken into account. Average Directional Index (ADX) is an indicator of trend strength. By putting them together on two-dimensional space and checking, whether nearby values have indicated a strong uptrend or downtrend, we hope to filter out bad signals from the MA crossing strategy.
This is an experiment, so any feedback would be appreciated. It was tested on BTC/USDT pair on 5 minute timeframe. I am planning to expand this strategy in the future to include more moving averages and filters.

Robust Channel [tbiktag]Introducing the Robust Channel indicator.
This indicator is based on a remarkable property of robust statistics , namely, the resistance to the presence of data points that deviate significantly from the established trend (generally speaking, outliers ). Being outlier-resistant, the Robust Channel indicator “remembers” a pre-existing trend and thus exhibits a very peculiar "lag" in case of a sharp price change. This allows high-confidence identification of such price actions as a trend reversal, range break, pullback, etc.
In the case of trending and range-bound market conditions, the price remains within the channel most of the time, fluctuating around the central line.
Technical details
The central line is calculated using the repeated median slope algorithm. For each data point in a lookback window of a user-specified Length , this method calculates the median slope of the lines that connect that point to all other points inside the window. The overall median of these median slopes is then calculated and used as an estimate of the trend slope. The algorithm is very efficient as it uses an on-the-fly procedure to update the array containing the slopes (new data pushed - old data removed).
The outer line is then calculated as the central line plus the Length -period standard deviation of the price data multiplied by a user-defined Channel Width Factor . The inner line is defined analogously below the central line.
Usage
As a stand-alone indicator, the Robust Channel can be applied similarly to the Bollinger Bands and the Keltner Channel:
A close above the outer line can be interpreted as a bullish signal and a close below the inner line as a bearish signal.
Likewise, a return to the channel from below after a break may serve as a bullish signal, while a return from above may indicate bearish sentiment.
Robust Channel can be also used to confirm chart patterns such as double tops and double bottoms.
If you like this indicator, feel free to leave your feedback in the comments below!

Max Drawdown Calculating Functions (Optimized)Maximum Drawdown and Maximum Relative Drawdown% calculating functions.
I needed a way to calculate the maxDD% of a serie of datas from an array (the different values of my balance account). I didn't find any builtin pinescript way to do it, so here it is.
There are 2 algorithms to calculate maxDD and relative maxDD%, one non optimized needs n*(n - 1)/2 comparisons for a collection of n datas, the other one only needs n-1 comparisons.
In the example we calculate the maxDDs of the last 10 close values.
There a 2 functions : "maximum_relative_drawdown" and "maximum_dradown" (and "optimized_maximum_relative_drawdown" and "optimized_maximum_drawdown") with names speaking for themselves.
Input : an array of floats of arbitrary size (the values we want the DD of)
Output : an array of 4 values
I added the iteration number just for fun.
Basically my script is the implementation of these 2 algos I found on the net :
var peak = 0;
var n = prices.length
for (var i = 1; i < n; i++){
dif = prices - prices ;
peak = dif < 0 ? i : peak;
maxDrawdown = maxDrawdown > dif ? maxDrawdown : dif;
}
var n = prices.length
for (var i = 0; i < n; i++){
for (var j = i + 1; j < n; j++){
dif = prices - prices ;
maxDrawdown = maxDrawdown > dif ? maxDrawdown : dif;
}
}
Feel free to use it.
@version=4

Resampling Reverse Engineering Bands [DW]This is an experimental study designed to reverse engineer price levels from centered oscillators at user defined sample rates.
This study aims to educate users on the process of oscillator reverse engineering, and to give users an alternative perspective on some of the most commonly used oscillators in the trading game.
Reverse engineering price levels from an oscillator is actually a rather simple, straightforward process.
Rather than plugging price values into a function to solve for oscillator values, we rearrange the function using some basic algebraic operations and plug in a specified oscillator value to solve for price values instead.
This process tells us what price value is needed in order for the oscillator to equal a certain value.
For example, if you wanted to know what price value would be considered “overbought” or “oversold” according to your oscillator, you can do that using this process.
In this study, the reverse engineering functions are used to calculate the price values of user defined high and low oscillator thresholds, and the price values for the oscillator center.
This allows you to visualize what prices will trigger thresholds as a sort of confidence interval, which is information that isn't inherently available when simply analyzing the oscillator directly.
This script is equipped with three reverse engineering functions to choose from for calculating the band values:
-> Reverse Relative Strength Index (RRSI)
-> Reverse Stochastic Oscillator (RStoch)
-> Reverse Commodity Channel Index (RCCI)
You can easily select the function you want to utilize from the "Band Calculation Type" dropdown tab.
These functions are specially designed to calculate at any sample rate (up to 1 bar per sample) utilizing the process of downsampling that I introduced in my Resampling Filter Pack.
The sample rate can be determined with any of these three methods:
-> BPS - Resamples based on the number of bars.
-> Interval - Resamples based on time in multiples of current charting timeframe.
-> PA - Resamples based on changes in price action by a specified size. The PA algorithm in this script is derived from my Range Filter algorithm.
The range for PA method can be sized in points, pips, ticks, % of price, ATR, average change, and absolute quantity.
Utilizing downsampled rates allows you to visualize the reverse engineered values of an oscillator calculated at larger sample scales.
This can be rather beneficial for trend analysis since lower sample rates completely remove certain levels of noise.
By default, the sample rate is set to 1 BPS, which is the same as bar-to-bar calculation. Feel free to experiment with the sample rate parameters and configure them how you like.
Custom bar colors are included as well. The color scheme is based on disparity between sources and the reverse engineered center level.
In addition, background highlights are included to indicate when price is outside the bands, thus indicating "overbought" and "oversold" conditions according to the thresholds you set.
I also included four external output variables for easy integration of signals with other scripts:
-> Trend Signals (Current Resolution Prices) - Outputs 1 for bullish and -1 for bearish based on disparity between current resolution source and the central level output.
-> Trend Signals (Resampled Prices) - Outputs 1 for bullish and -1 for bearish based on disparity between resampled source and the central level output.
-> Outside Band Signal (Current Resolution Prices) - Outputs 1 for overbought and -1 for oversold based on current resolution source being outside the bands. Returns 0 otherwise.
-> Outside Band Signal (Resampled Prices) - Outputs 1 for overbought and -1 for oversold based on resampled source being outside the bands. Returns 0 otherwise.
To use these signals with another script, simply select the corresponding external output you want to use from your script's source input dropdown tab.
Reverse engineering oscillators is a simple, yet powerful approach to incorporate into your momentum or trend analysis setup.
By incorporating projected price levels from oscillators into our analysis setups, we are able to gain valuable insights, make (potentially) smarter trading decisions, and visualize the oscillators we know and love in a totally different way.
I hope you all find this script useful and enjoyable!
BuyTheDipWell, I often had arguments in online forum with a guy who claimed to time the market perfectly without any technical analysis or prior experience. He often claimed that technical analysis does not work and it only works when you trade on other's emotions. He also argued that algorithmic trading isn't profitable - if so, everyone would do that. Hence, I thought I will convert his idea to algorithm.
In his own words, the strategy is as below:
Chose an instrument which is in full uptrend.
Wait for the panic sell and buy the dip
Once market recovers back exit immediately
It seems to do just fine with indexes. But, not so good when it comes to stocks.
