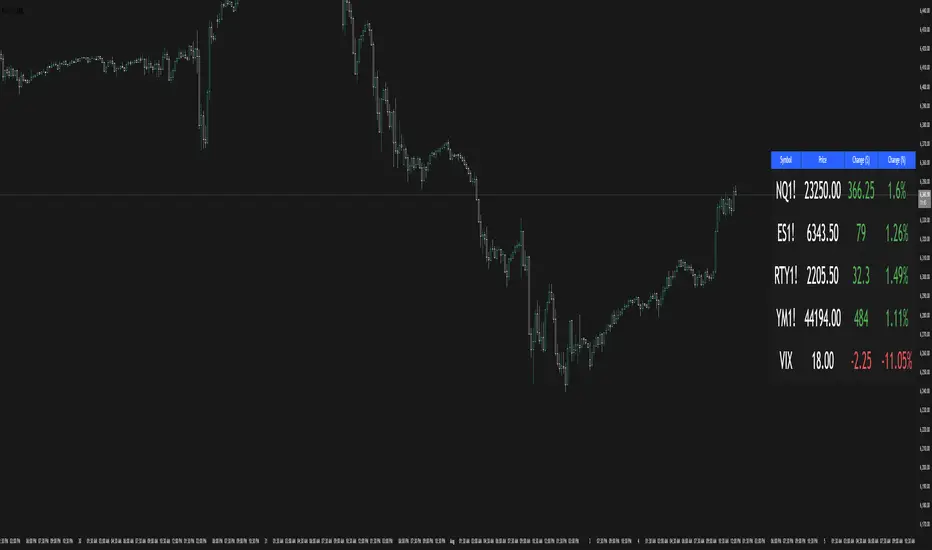
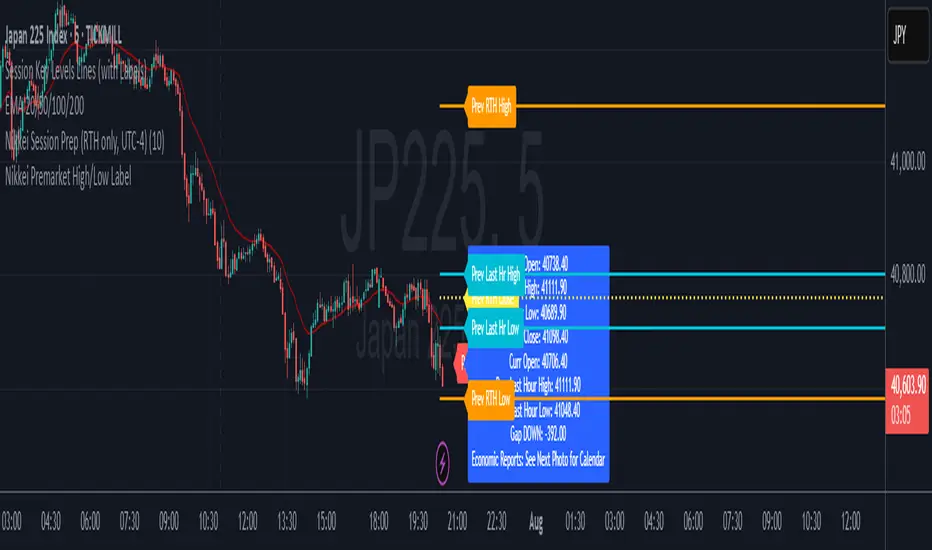
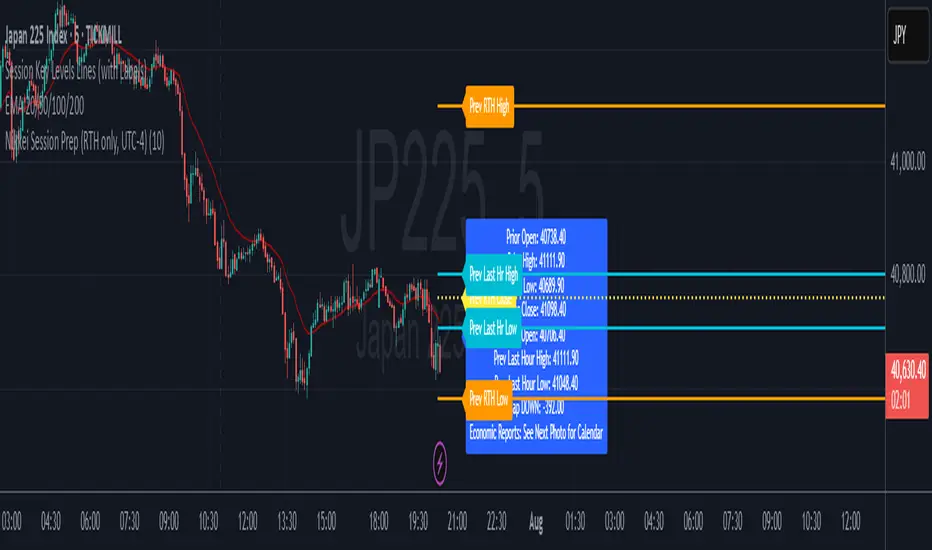
Multi-Ticker TableMulti-Ticker Table
A customizable TradingView indicator that displays a clean, organized table of up to 10 user-defined ticker symbols with their current daily price, daily dollar change, and daily percentage change.
Key features include:
Enable/disable individual tickers with custom symbols
Customizable font sizes and colors for header and body rows
Customizable table background colors for header and data rows
Flexible table positioning anywhere on the chart (top/middle/bottom × left/center/right)
Highlights positive changes in green and negative changes in red for quick visual analysis
Hides chart candles to display the table as a standalone dashboard
Ideal for traders who want a quick, at-a-glance summary of multiple markets or instruments without cluttering the chart.
Penunjuk Pine Script®