VIPER DOPING - A Volume Profile to estimate trend probabilityDESCRIPTION :
VIPER DOPING uses volume analysis to help trader to understand trading keys below:
Support and Resistance
Profit and Loss
Estimate candle direction
Trend
Biggest Buy and Sell on level prices
HOW TO USE:
The volume bar will have buy and sell colors, by default the buy color is blue and the sell is red. The size of bar is important matter, the biggest bar size means that price level has strong volume or transaction and the smallest bar size indicates the lowest transaction or volume. How to read it?
The bar above the candle is the resistance
The bar below the candle is the support
If you want long the market, find the biggest or bigger support, which is below the candle
If you want short the market, find the biggest or bigger resistance which is above the candle
Trading style and the maximum range (total candle), default is 60. This setup to analyze volumes in specific candle range. Please check the following recommendation based on trading style:
Scalping: 30 - 60 candles, recommendation timeframe: 5m - 1h
Day Trading: 50 - 120 candles, recommendation timeframe: 30m - 4h
Swing Trading: 100- 240 candles, recommendation timeframe: 1h- 3D
The white box is to visualize trading area by total candle. Every line has the meaning:
The left line is the start candle
The right line is the end candle
The top line is the highest price of volume profile
The bottom line is the lowest price of volume profile
The fibonacci line will help you to confirm and compare of supports and resistances with the volume profile lines.
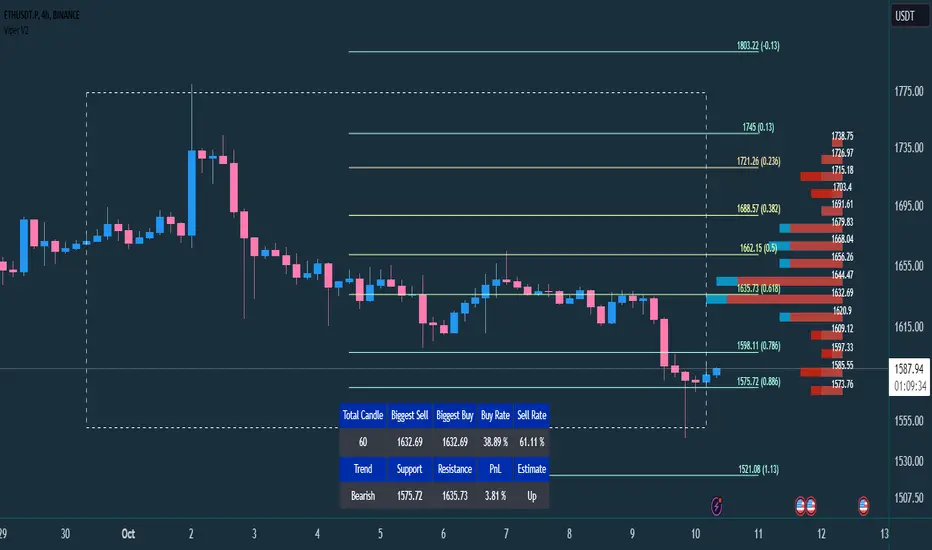
The TABLE CELLS
it contains information to help trader to understand the recent situation of market and to take strategy of trading:
Total Candle : the maximum candles are used to analyze the volume from previous active candle
Biggest Sell : the horizontal price area which has the largest of sell volume of the last total candle
Biggest Buy : the horizontal price area which has the largest of buy volume of the last total candle
Buy Rate : the ratio of buy and sell volume of the last total candle
Support: the closest price to be the support from the active candle, auto changed if support to be invalid
Resistance : the closest price to be the resistance from the active candle, auto changed if support to be invalid
PnL : the percentage profit if you trade using the support and resistance prices and it can be used for Risk Management. Wisely the risk is 50% of the profit, example if the profit 1% the your risk should be 0.5% from entry.
Estimate : to analize the next direction of candle or target, it will be changed automatically by volume condition.
CONFIGURATION:
Table Position : You can change the table position to top or bottom, to left, right or center
Calculation : You can include the active candle in volume calculation or you can choose the behind active candle. If you use active candle, there could be possible repainting.
The volume profile configuration is about appearance configuration, to setup the thickness, colors, position.
The fibonacci configuration is about appearance configuration, to setup the thickness, extend lines, label styles.
Probability
Pro Bollinger Bands CalculatorThe "Pro Bollinger Bands Calculator" indicator joins our suite of custom trading tools, which includes the "Pro Supertrend Calculator", the "Pro RSI Calculator" and the "Pro Momentum Calculator."
Expanding on this series, the "Pro Bollinger Bands Calculator" is tailored to offer traders deeper insights into market dynamics by harnessing the power of the Bollinger Bands indicator.
Its core mission remains unchanged: to scrutinize historical price data and provide informed predictions about future price movements, with a specific focus on detecting potential bullish (green) or bearish (red) candlestick patterns.
1. Bollinger Bands Calculation:
The indicator kicks off by computing the Bollinger Bands, a well-known volatility indicator. It calculates two pivotal Bollinger Bands parameters:
- Bollinger Bands Length: This parameter sets the lookback period for Bollinger Bands calculations.
- Bollinger Bands Deviation: It determines the deviation multiplier for the upper and lower bands, typically set at 2.0.
2. Visualizing Bollinger Bands:
The Bollinger Bands derived from the calculations are skillfully plotted on the price chart:
- Red Line: Represents the upper Bollinger Band during bearish trends, suggesting potential price declines.
- Teal Line: Represents the lower Bollinger Band in bullish market conditions, signaling the possibility of price increases.
3.Analyzing Consecutive Candlesticks:
The indicator's core functionality revolves around tracking consecutive candlestick patterns based on their relationship with the Bollinger Bands lines. To be considered for analysis, a candlestick must consistently close either above (green candles) or below (red candles) the Bollinger Bands lines for multiple consecutive periods.
4. Labeling and Enumeration:
To convey the count of consecutive candles displaying consistent trend behavior, the indicator meticulously assigns labels to the price chart. The position of these labels varies depending on the direction of the trend, appearing either below (for bullish patterns) or above (for bearish patterns) the candlesticks. The label colors match the candle colors: green labels for bullish candles and red labels for bearish ones.
5. Tabular Data Presentation:
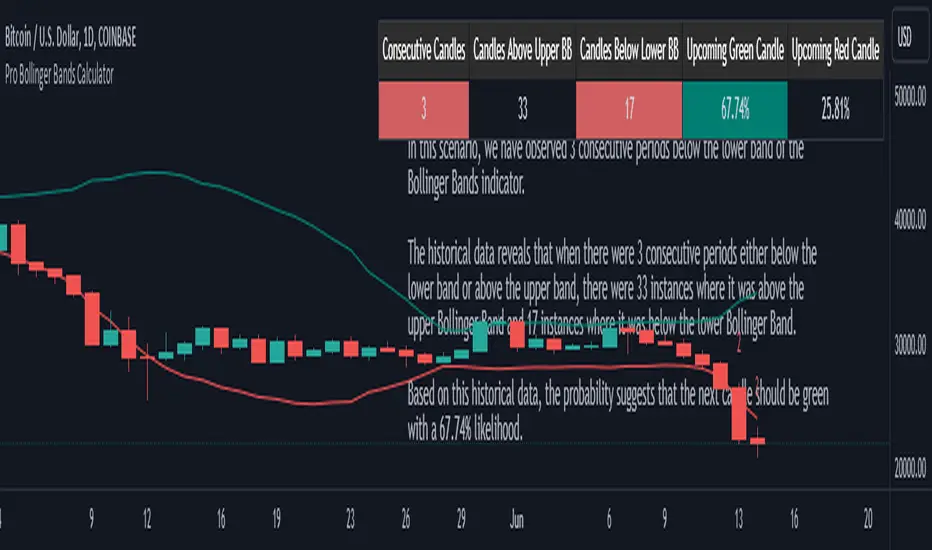
The indicator complements its graphical analysis with a customizable table that prominently displays comprehensive statistical insights. Key data points within the table encompass:
- Consecutive Candles: The count of consecutive candles displaying consistent trend characteristics.
- Candles Above Upper BB: The number of candles closing above the upper Bollinger Band during the consecutive period.
- Candles Below Lower BB: The number of candles closing below the lower Bollinger Band during the consecutive period.
- Upcoming Green Candle: An estimated probability of the next candlestick being bullish, derived from historical data.
- Upcoming Red Candle: An estimated probability of the next candlestick being bearish, also based on historical data.
6. Custom Configuration:
To cater to diverse trading strategies and preferences, the indicator offers extensive customization options. Traders can fine-tune parameters such as Bollinger Bands length, upper and lower band deviations, label and table placement, and table size to align with their unique trading approaches.
SimilarityMeasuresLibrary "SimilarityMeasures"
Similarity measures are statistical methods used to quantify the distance between different data sets
or strings. There are various types of similarity measures, including those that compare:
- data points (SSD, Euclidean, Manhattan, Minkowski, Chebyshev, Correlation, Cosine, Camberra, MAE, MSE, Lorentzian, Intersection, Penrose Shape, Meehl),
- strings (Edit(Levenshtein), Lee, Hamming, Jaro),
- probability distributions (Mahalanobis, Fidelity, Bhattacharyya, Hellinger),
- sets (Kumar Hassebrook, Jaccard, Sorensen, Chi Square).
---
These measures are used in various fields such as data analysis, machine learning, and pattern recognition. They
help to compare and analyze similarities and differences between different data sets or strings, which
can be useful for making predictions, classifications, and decisions.
---
References:
en.wikipedia.org
cran.r-project.org
numerics.mathdotnet.com
github.com
github.com
github.com
Encyclopedia of Distances, doi.org
ssd(p, q)
Sum of squared difference for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Measure of distance that calculates the squared euclidean distance.
euclidean(p, q)
Euclidean distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Measure of distance that calculates the straight-line (or Euclidean).
manhattan(p, q)
Manhattan distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Measure of absolute differences between both points.
minkowski(p, q, p_value)
Minkowsky Distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
p_value (float) : `float` P value, default=1.0(1: manhatan, 2: euclidean), does not support chebychev.
Returns: Measure of similarity in the normed vector space.
chebyshev(p, q)
Chebyshev distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Measure of maximum absolute difference.
correlation(p, q)
Correlation distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Measure of maximum absolute difference.
cosine(p, q)
Cosine distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Cosine distance between vectors `p` and `q`.
---
angiogenesis.dkfz.de
camberra(p, q)
Camberra distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Weighted measure of absolute differences between both points.
mae(p, q)
Mean absolute error is a normalized version of the sum of absolute difference (manhattan).
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Mean absolute error of vectors `p` and `q`.
mse(p, q)
Mean squared error is a normalized version of the sum of squared difference.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Mean squared error of vectors `p` and `q`.
lorentzian(p, q)
Lorentzian distance between provided vectors.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Lorentzian distance of vectors `p` and `q`.
---
angiogenesis.dkfz.de
intersection(p, q)
Intersection distance between provided vectors.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Intersection distance of vectors `p` and `q`.
---
angiogenesis.dkfz.de
penrose(p, q)
Penrose Shape distance between provided vectors.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Penrose shape distance of vectors `p` and `q`.
---
angiogenesis.dkfz.de
meehl(p, q)
Meehl distance between provided vectors.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Meehl distance of vectors `p` and `q`.
---
angiogenesis.dkfz.de
edit(x, y)
Edit (aka Levenshtein) distance for indexed strings.
Parameters:
x (int ) : `array` Indexed array.
y (int ) : `array` Indexed array.
Returns: Number of deletions, insertions, or substitutions required to transform source string into target string.
---
generated description:
The Edit distance is a measure of similarity used to compare two strings. It is defined as the minimum number of
operations (insertions, deletions, or substitutions) required to transform one string into another. The operations
are performed on the characters of the strings, and the cost of each operation depends on the specific algorithm
used.
The Edit distance is widely used in various applications such as spell checking, text similarity, and machine
translation. It can also be used for other purposes like finding the closest match between two strings or
identifying the common prefixes or suffixes between them.
---
github.com
www.red-gate.com
planetcalc.com
lee(x, y, dsize)
Distance between two indexed strings of equal length.
Parameters:
x (int ) : `array` Indexed array.
y (int ) : `array` Indexed array.
dsize (int) : `int` Dictionary size.
Returns: Distance between two strings by accounting for dictionary size.
---
www.johndcook.com
hamming(x, y)
Distance between two indexed strings of equal length.
Parameters:
x (int ) : `array` Indexed array.
y (int ) : `array` Indexed array.
Returns: Length of different components on both sequences.
---
en.wikipedia.org
jaro(x, y)
Distance between two indexed strings.
Parameters:
x (int ) : `array` Indexed array.
y (int ) : `array` Indexed array.
Returns: Measure of two strings' similarity: the higher the value, the more similar the strings are.
The score is normalized such that `0` equates to no similarities and `1` is an exact match.
---
rosettacode.org
mahalanobis(p, q, VI)
Mahalanobis distance between two vectors with population inverse covariance matrix.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
VI (matrix) : `matrix` Inverse of the covariance matrix.
Returns: The mahalanobis distance between vectors `p` and `q`.
---
people.revoledu.com
stat.ethz.ch
docs.scipy.org
fidelity(p, q)
Fidelity distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Bhattacharyya Coefficient between vectors `p` and `q`.
---
en.wikipedia.org
bhattacharyya(p, q)
Bhattacharyya distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Bhattacharyya distance between vectors `p` and `q`.
---
en.wikipedia.org
hellinger(p, q)
Hellinger distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The hellinger distance between vectors `p` and `q`.
---
en.wikipedia.org
jamesmccaffrey.wordpress.com
kumar_hassebrook(p, q)
Kumar Hassebrook distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Kumar Hassebrook distance between vectors `p` and `q`.
---
github.com
jaccard(p, q)
Jaccard distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Jaccard distance between vectors `p` and `q`.
---
github.com
sorensen(p, q)
Sorensen distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Sorensen distance between vectors `p` and `q`.
---
people.revoledu.com
chi_square(p, q, eps)
Chi Square distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
eps (float)
Returns: The Chi Square distance between vectors `p` and `q`.
---
uw.pressbooks.pub
stats.stackexchange.com
www.itl.nist.gov
kulczynsky(p, q, eps)
Kulczynsky distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
eps (float)
Returns: The Kulczynsky distance between vectors `p` and `q`.
---
github.com

FunctionMatrixCovarianceLibrary "FunctionMatrixCovariance"
In probability theory and statistics, a covariance matrix (also known as auto-covariance matrix, dispersion matrix, variance matrix, or variance–covariance matrix) is a square matrix giving the covariance between each pair of elements of a given random vector.
Intuitively, the covariance matrix generalizes the notion of variance to multiple dimensions. As an example, the variation in a collection of random points in two-dimensional space cannot be characterized fully by a single number, nor would the variances in the `x` and `y` directions contain all of the necessary information; a `2 × 2` matrix would be necessary to fully characterize the two-dimensional variation.
Any covariance matrix is symmetric and positive semi-definite and its main diagonal contains variances (i.e., the covariance of each element with itself).
The covariance matrix of a random vector `X` is typically denoted by `Kxx`, `Σ` or `S`.
~wikipedia.
method cov(M, bias)
Estimate Covariance matrix with provided data.
Namespace types: matrix
Parameters:
M (matrix) : `matrix` Matrix with vectors in column order.
bias (bool)
Returns: Covariance matrix of provided vectors.
---
en.wikipedia.org
numpy.org
Candles In Row (Expo)█ Overview
The Candles In Row (Expo) indicator is a powerful tool designed to track and visualize sequences of consecutive candlesticks in a price chart. Whether you're looking to gauge momentum or determine the prevailing trend, this indicator offers versatile functionality tailored to the needs of active traders. The Candles In Row indicator can be an integral part of a multi-timeframe trading strategy, allowing traders to understand market momentum, and set trading bias. By recognizing the patterns and likelihood of future price movements, traders can make more informed decisions and align their trades with the overall market direction.
█ How to use
The indicator enhances traders' understanding of the consecutive candle patterns, helping them to uncover trends and momentum. Consecutive candles in the same direction may indicate a strong trend. The Candles In Row indicator can be an essential tool for traders employing a multiple timeframes strategy.
Analyzing a Higher Timeframe:
Understanding Momentum: By analyzing consecutive green or red candles in a higher timeframe, traders can identify the prevailing momentum in the market. A series of green candles would suggest an upward trend, while a series of red candles would indicate a downward trend.
Predicting Next Candle: The indicator's predictive feature calculates the likelihood of the next candle being green or red based on historical patterns. This probability helps traders gauge the potential continuation of the trend.
Setting the Trading Bias: If the likelihood of the next candle being green is high, the trader may decide to focus on long (buy) opportunities. Conversely, if the likelihood of the next candle being red is high, the trader may look for short (sell) opportunities.
In this example, we are using the Heikin Ashi candles.
Moving to a Lower Timeframe:
Finding Entry Points: Once the trading bias is set based on the higher timeframe analysis, traders can switch to a lower timeframe to look for entry points in the direction of the bias. For example, if the higher timeframe suggests a high likelihood of a green candle, traders may look for buy opportunities in the lower timeframe.
Combining Timeframes for a Comprehensive Strategy:
Confirmation and Alignment: By analyzing the higher timeframe and confirming the direction in the lower timeframe, traders can ensure that they are trading in alignment with the broader trend.
Avoiding False Signals: By using a higher timeframe to set the trading bias and a lower timeframe to find entries, traders can avoid false signals and whipsaws that might be present in a single timeframe analysis.
█ Settings
Price Input Selection: Choose between regular open and close prices or Heikin Ashi candles as the basis for calculation.
Data Window Control: Decide between displaying the full data window or only the active data. You can also enable a counter that keeps track of the number of candles.
Alert Configuration: Set the desired number and color of consecutive candles that must occur in a row to trigger an alert.
Table Display Customization: Customize the location and size of the display table according to your preferences.
-----------------
Disclaimer
The information contained in my Scripts/Indicators/Ideas/Algos/Systems does not constitute financial advice or a solicitation to buy or sell any securities of any type. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
My Scripts/Indicators/Ideas/Algos/Systems are only for educational purposes!

Normal Distribution CurveThis Normal Distribution Curve is designed to overlay a simple normal distribution curve on top of any TradingView indicator. This curve represents a probability distribution for a given dataset and can be used to gain insights into the likelihood of various data levels occurring within a specified range, providing traders and investors with a clear visualization of the distribution of values within a specific dataset. With the only inputs being the variable source and plot colour, I think this is by far the simplest and most intuitive iteration of any statistical analysis based indicator I've seen here!
Traders can quickly assess how data clusters around the mean in a bell curve and easily see the percentile frequency of the data; or perhaps with both and upper and lower peaks identify likely periods of upcoming volatility or mean reversion. Facilitating the identification of outliers was my main purpose when creating this tool, I believed fixed values for upper/lower bounds within most indicators are too static and do not dynamically fit the vastly different movements of all assets and timeframes - and being able to easily understand the spread of information simplifies the process of identifying key regions to take action.
The curve's tails, representing the extreme percentiles, can help identify outliers and potential areas of price reversal or trend acceleration. For example using the RSI which typically has static levels of 70 and 30, which will be breached considerably more on a less liquid or more volatile asset and therefore reduce the actionable effectiveness of the indicator, likewise for an asset with little to no directional volatility failing to ever reach this overbought/oversold areas. It makes considerably more sense to look for the top/bottom 5% or 10% levels of outlying data which are automatically calculated with this indicator, and may be a noticeable distance from the 70 and 30 values, as regions to be observing for your investing.
This normal distribution curve employs percentile linear interpolation to calculate the distribution. This interpolation technique considers the nearest data points and calculates the price values between them. This process ensures a smooth curve that accurately represents the probability distribution, even for percentiles not directly present in the original dataset; and applicable to any asset regardless of timeframe. The lookback period is set to a value of 5000 which should ensure ample data is taken into calculation and consideration without surpassing any TradingView constraints and limitations, for datasets smaller than this the indicator will adjust the length to just include all data. The labels providing the percentile and average levels can also be removed in the style tab if preferred.
Additionally, as an unplanned benefit is its applicability to the underlying price data as well as any derived indicators. Turning it into something comparable to a volume profile indicator but based on the time an assets price was within a specific range as opposed to the volume. This can therefore be used as a tool for identifying potential support and resistance zones, as well as areas that mark market inefficiencies as price rapidly accelerated through. This may then give a cleaner outlook as it eliminates the potential drawbacks of volume based profiles that maybe don't collate all exchange data or are misrepresented due to large unforeseen increases/decreases underlying capital inflows/outflows.
Thanks to @ALifeToMake, @Bjorgum, vgladkov on stackoverflow (and possibly some chatGPT!) for all the assistance in bringing this indicator to life. I really hope every user can find some use from this and help bring a unique and data driven perspective to their decision making. And make sure to please share any original implementaions of this tool too! If you've managed to apply this to the average price change once you've entered your position to better manage your trade management, or maybe overlaying on an implied volatility indicator to identify potential options arbitrage opportunities; let me know! And of course if anyone has any issues, questions, queries or requests please feel free to reach out! Thanks and enjoy.

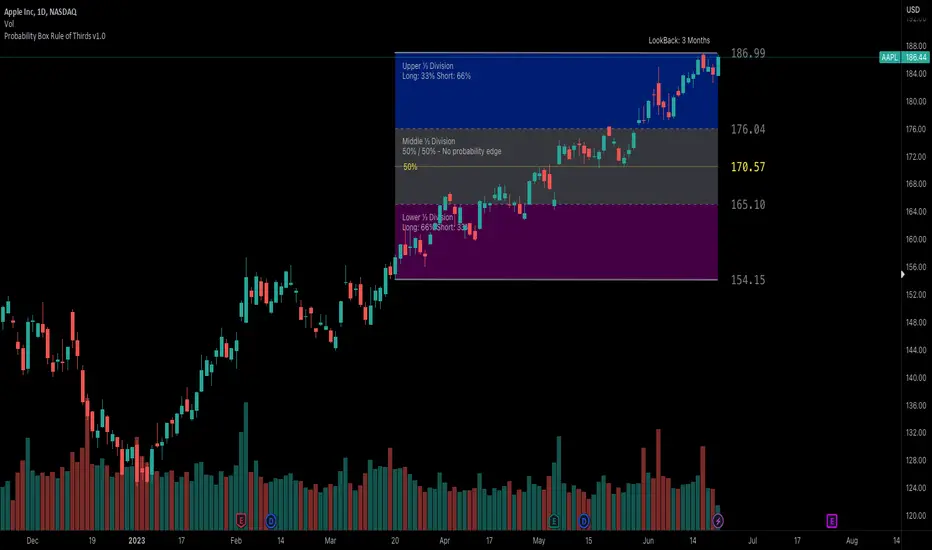
Probability Box Rule of Thirds [PPI]█ Probability Box Rule of Thirds
The Probability Box Rule of Thirds , is a visual indicator that helps traders identify possible overbought and oversold conditions. It does this by dividing the price range – highest high minus the lowest low of a given lookback period or date range – into thirds. Each third has distinct probability characteristics and when combined represent a probability box.
We have spent years refining the probability box concept, and have previously published a How To on Trading View – "How to Trade Probability Ranges – The Critical Rule of 1/3" which can be found here:
To quickly summarize the How To – when using the Rule of Thirds , you are using a combination of statistics, probabilities of success, and prior price action to determine when to enter a trade. The visual range division helps remove subjectivity and clearly shows when the trading odds are stacked in your favor. By identifying and taking higher probability trades, you have a higher chance of success as trading is all about probability and risk management.
Implementing the Rule of Thirds starts with finding an instrument that is consolidating and identifying the nearest important support and resistance levels based on your targeted trading timeframe or lookback period.
The range between the support and resistance levels is divided into thirds to form three zones within the consolidation range.
When going LONG , you want to BUY in the bottom third of the range. Once you buy, your objective is to hold during the middle third and sell when the price enters the top third.
When you buy in the lower third, there's a 66.6% probability of success. If you buy in the middle third, you only have a 50% / 50% chance of success. Going long in the top third of the range gives you a 33.3% chance of success as you are already close to the identified resistance level.
When going SHORT , the sequence and odds are reversed. You want to SELL in the top third of the range, hold the middle third and exit in the bottom third of the range. This gives you a 66.6% chance of success when entering in the top third, a 50% / 50% chance when entering in the middle third, and a 33.3% chance in the bottom third given you are already close to the identified support level.
When the price lies in the middle third, the even 50% / 50% odds provide no probability edge and a trader is better off waiting until the price reaches the upper or lower thirds of the price range.
The Rule of Thirds allows us to quickly visually evaluate trades based on probabilities, selectively enter trades that have the highest odds of success, and avoid likely losing trades. The Rule of Thirds gives you confidence to hold trades based on prior trading ranges and provides clear levels where the prices are likely to either reverse or start trending.
The Probability Box Rule of Thirds automatically implements the first two steps of the Rule of Thirds by using the highest high and lowest low of a given lookback period to identify the support and resistance levels, and automatically divides the range into thirds. The rest of the Rule of Thirds rules remain the same.
Just having the price within the bottom thirds or top thirds, however, does not mean the price will immediately reverse. The GE chart below is an example of a stock that remained 'stuck' in the upper thirds of the price range for an extended amount of time:
And the CVS chart below is an example where the price is 'stuck' in the lower thirds of the price range:
While the price is in the upper or lower thirds, it is very important that the trader should use other indicators to identify when a significant trend reversal occurs. Once a trend reversal event happens, the trader either enters a trade AND/OR exits a trade if already in one.
When the price exceeds the bounds of the probability box, there are three possible outcomes – a strong continuation trend, the price consolidates around the probability box edge, or a trend reversal. Your favorite indicators will help determine which event is happening.
The CVS chart above is a good example of the probability box being exceeded with the last bar. The price exceeding the price range is temporary event as the price range will expand to encompass the revised price range on the next trading day.
█ Indicator Features
Each supported timeframe – Monthly, Weekly, and Daily – allows the selection of an appropriate lookback period for your trading style. The defaults are a good starting point for swing trading and long-term investing. You many need to experiment to find the optimal lookback period for your trading style.
Even if you only day trade, the Probability Box Rule of Thirds with the appropriate lookback periods can help you visualize the bigger picture of where the instrument is heading.
When viewing the charts, you can find the currently selected lookback period above the upper edge of the price range.
The indicator will display a dotted yellow line at 50% of the price range and show the line's value when requested.
The visibility of the actual thirds and border price values are controlled by the " Show Probability Box Values " checkbox. You may need to expand the chart's right margin to see the values.
The " Show Internal Labels " checkbox controls the display of the internal ⅓ Division labels and the percentage odds, along with the 50% label. This option by default is set to off.
The " Show Error Messages " checkbox controls the display of error messages and by default is turned on. Turn off to prevent error messages from being shown on intraday timeframes. Save as indicator default to prevent having to turn off this setting each time added to chart.
The color and transparency controls allow the user to modify the colors used for each third. The default settings are optimized for use with a DARK background.
█ Implementation Notes
IMPORTANT - the Probability Box Rule of Thirds is set up to only handle Monthly, Weekly and Daily charts. This is intentional as the indicator is designed to be used for safer multiple day and longer swing trades. When viewed on intraday charts, the indicator will be hidden.
The Probability Box Rule of Thirds uses a rolling window of the equivalent number of bars for the lookback period rather than relying on the bar starting and ending dates. This allows the use of a standard number of days in the selected lookback window across various instruments and ensures fast, efficient calculations.
The lookback periods are adjusted when non-standard timeframe multipliers are used – e.g., a 12M chart timeframe and a 3-year lookback period will result in a 3 bar lookback. Fractional bars in this calculation are rounded up and any incompatible lookback period and chart timeframe combination will generate a runtime error.
In summary, the Probability Box Rule of Thirds automates and visually identifies overbought and oversold areas, which combined with the Rule of Thirds probability risk profiles, increases your odds of success through better trade selections and higher confidence in your trades.
█ Disclaimer
There is substantial risk in trading. Losses incurred in trading can be significant. Only trade with money you can afford to lose. We make no claims whatsoever regarding the impact of past or future performance on your trading results.
Probability Trend IndicatorUnderstanding the Indicator:
The indicator calculates the probabilities of upward and downward trends based on the percentage change in price over a specified lookback period.
It displays these probabilities in a table and plots a histogram to represent the difference between the probabilities.
The colors of the histogram bars indicate the trend direction and whether the trend is increasing or decreasing.
Setting the Lookback Period:
The indicator allows you to specify the lookback period, which determines the number of bars to consider for calculating the probabilities.
By default, the lookback period is set to 50 bars. However, you can adjust it based on your trading preferences and the timeframe you're analyzing.
Analyzing the Probabilities:
The indicator calculates the probabilities of upward and downward trends and displays them in a table on the chart.
The probabilities are presented as percentages, representing the likelihood of each type of trend occurring.
You can use these probabilities to gain insights into the potential market direction and assess the strength of the prevailing trend.
Interpreting the Histogram:
The histogram is plotted based on the difference between the probabilities of upward and downward trends, known as the oscillator value.
The histogram bars are colored to provide visual cues about the trend direction and whether the trend is gaining or losing strength.
Green bars indicate upward trends, and red bars indicate downward trends.
Lighter shades of green or red suggest increasing trends, while darker shades suggest decreasing trends.
Making Trading Decisions:
The indicator serves as a tool for assessing the probabilities of trends and can be used alongside other technical analysis methods.
You can consider the probabilities, the histogram pattern, and the overall market context to make informed trading decisions.
It's important to remember that no indicator or tool can guarantee future market movements, so prudent risk management and additional analysis are essential.

BenfordsLawLibrary "BenfordsLaw"
Methods to deal with Benford's law which states that a distribution of first and higher order digits
of numerical strings has a characteristic pattern.
"Benford's law is an observation about the leading digits of the numbers found in real-world data sets.
Intuitively, one might expect that the leading digits of these numbers would be uniformly distributed so that
each of the digits from 1 to 9 is equally likely to appear. In fact, it is often the case that 1 occurs more
frequently than 2, 2 more frequently than 3, and so on. This observation is a simplified version of Benford's law.
More precisely, the law gives a prediction of the frequency of leading digits using base-10 logarithms that
predicts specific frequencies which decrease as the digits increase from 1 to 9." ~(2)
---
reference:
- 1: en.wikipedia.org
- 2: brilliant.org
- 4: github.com
cumsum_difference(a, b)
Calculate the cumulative sum difference of two arrays of same size.
Parameters:
a (float ) : `array` List of values.
b (float ) : `array` List of values.
Returns: List with CumSum Difference between arrays.
fractional_int(number)
Transform a floating number including its fractional part to integer form ex:. `1.2345 -> 12345`.
Parameters:
number (float) : `float` The number to transform.
Returns: Transformed number.
split_to_digits(number, reverse)
Transforms a integer number into a list of its digits.
Parameters:
number (int) : `int` Number to transform.
reverse (bool) : `bool` `default=true`, Reverse the order of the digits, if true, last will be first.
Returns: Transformed number digits list.
digit_in(number, digit)
Digit at index.
Parameters:
number (int) : `int` Number to parse.
digit (int) : `int` `default=0`, Index of digit.
Returns: Digit found at the index.
digits_from(data, dindex)
Process a list of `int` values and get the list of digits.
Parameters:
data (int ) : `array` List of numbers.
dindex (int) : `int` `default=0`, Index of digit.
Returns: List of digits at the index.
digit_counters(digits)
Score digits.
Parameters:
digits (int ) : `array` List of digits.
Returns: List of counters per digit (1-9).
digit_distribution(counters)
Calculates the frequency distribution based on counters provided.
Parameters:
counters (int ) : `array` List of counters, must have size(9).
Returns: Distribution of the frequency of the digits.
digit_p(digit)
Expected probability for digit according to Benford.
Parameters:
digit (int) : `int` Digit number reference in range `1 -> 9`.
Returns: Probability of digit according to Benford's law.
benfords_distribution()
Calculated Expected distribution per digit according to Benford's Law.
Returns: List with the expected distribution.
benfords_distribution_aprox()
Aproximate Expected distribution per digit according to Benford's Law.
Returns: List with the expected distribution.
test_benfords(digits, calculate_benfords)
Tests Benford's Law on provided list of digits.
Parameters:
digits (int ) : `array` List of digits.
calculate_benfords (bool)
Returns: Tuple with:
- Counters: Score of each digit.
- Sample distribution: Frequency for each digit.
- Expected distribution: Expected frequency according to Benford's.
- Cumulative Sum of difference:
to_table(digits, _text_color, _border_color, _frame_color)
Parameters:
digits (int )
_text_color (color)
_border_color (color)
_frame_color (color)

Trend Reversal Probability CalculatorThe "Trend Reversal Probability Calculator" is a TradingView indicator that calculates the probability of a trend reversal based on the crossover of multiple moving averages and the rate of change (ROC) of their slopes. This indicator is designed to help traders identify potential trend reversals by providing signals when the short-term moving averages start to slope in the opposite direction of the long-term moving average.
To use the indicator, simply add it to your TradingView chart and adjust the input parameters according to your preferences. The input parameters include the length of the moving averages, the ROC length (trend sensitivity), and the reversal sensitivity (signal percentage).
The indicator calculates the ROC of the moving averages and determines if the short-term moving averages are sloping in the opposite direction of the long-term moving average. The number of short-term moving averages that meet this condition is then counted, and the probability of a trend reversal is calculated based on the percentage of short-term moving averages that meet this condition.
When the probability of a trend reversal is high, a bullish or bearish signal is generated, depending on the direction of the reversal. The bullish signal is generated when the short-term moving averages start to slope upward, and the bearish signal is generated when the short-term moving averages start to slope downward.
Traders can use the "Trend Reversal Probability Calculator" to identify potential trend reversals and adjust their trading strategies accordingly. It is important to note that this indicator is not a guarantee of a trend reversal and should be used in conjunction with other technical analysis tools to make informed trading decisions.

Bayesian predictive leading indicator--------- ENGLISH ---------
This is a predictive indicator ( leading indicator ) that uses Bayes' formula to calculate the conditional probability of price increases given the angular coefficient. The indicator calculates the angular coefficient and its regression and uses it to predict prices.
Bayes' theorem is a fundamental result of probability theory and is used to calculate the probability of a cause causing the verified event. In other words, for our indicator, Bayes' theorem is used to calculate the conditional probability of one event (price event in this case) with respect to another event by calculating the probabilities of the two events (past price) and the conditional probability of the second event (future price) with respect to the first event.
The red line represents the angular coefficient. The blue line represents the normalized expected price. Finally, the yellow line represents the conditional probability that the price will increase or decrease.
How to use it. In addition to the convenient histogram, which follows the angular coefficient, another practical operational application might be to go long when the blue line is above the red and yellow lines. Conversely short when the blue is below the red and yellow.
When the yellow line passes above all others, a reversal in the long direction is imminent and vice versa.
The extent of the reversal depends on how far the yellow line will be away in price from the other 2 lines.
This indicator is in its embryonic state and updates will follow to make it more graphically readable, add alerts, etc.
Stay tuned! Leave a boost and comment or write to me if you wish.
--------- ITALIANO ---------
Questo è un indicatore predittivo ( leading indicator ) che utilizza la formula di Bayes per calcolare la probabilità condizionata che il prezzo aumenti dato il coefficiente angolare. L’indicatore calcola il coefficiente angolare e la sua regressione e lo utilizza per prevedere i prezzi.
Il teorema di Bayes è un risultato fondamentale della teoria della probabilità e viene impiegato per calcolare la probabilità di una causa che ha provocato l’evento verificato. In altre parole, per il nostro indicatore, il teorema di Bayes serve per calcolare la probabilità condizionata di un evento (di prezzo in questo caso) rispetto a un altro evento, calcolando le probabilità dei due eventi (prezzo passato) e la probabilità condizionata del secondo evento (prezzo futuro) rispetto al primo.
La linea rossa rappresenta il coefficiente angolare. La linea blu rappresenta il prezzo previsto normalizzato. Infine la linea gialla rappresenta la probabilità condizionata che il prezzo aumenti o diminuisca.
Come si usa? Oltre al comodo istogramma, che segue il coefficiente angolare, un'altra applicazione operativa pratica potrebbe essere di andare long quando la linea blu è sopra la linea rossa e gialla. Viceversa short quando la blu è sotto la rossa e la gialla.
Quando la linea gialla passa sopra tutte le altre è imminente un'inversione in direzione long e viceversa.
L'entità dell'inversione dipende da quanto la linea gialla sarà distante di prezzo dalle altre 2 linee.
Questo indicatore è al suo stato embrionale e seguiranno aggiornamenti per renderlo graficamente più leggibile, aggiungere alert, ecc.
Stay tuned! Lascia un boost e commenta o scrivimi se desideri.
MarkovChainLibrary "MarkovChain"
Generic Markov Chain type functions.
---
A Markov chain or Markov process is a stochastic model describing a sequence of possible events in which the
probability of each event depends only on the state attained in the previous event.
---
reference:
Understanding Markov Chains, Examples and Applications. Second Edition. Book by Nicolas Privault.
en.wikipedia.org
www.geeksforgeeks.org
towardsdatascience.com
github.com
stats.stackexchange.com
timeseriesreasoning.com
www.ris-ai.com
github.com
gist.github.com
github.com
gist.github.com
writings.stephenwolfram.com
kevingal.com
towardsdatascience.com
spedygiorgio.github.io
github.com
www.projectrhea.org
method to_string(this)
Translate a Markov Chain object to a string format.
Namespace types: MC
Parameters:
this (MC) : `MC` . Markov Chain object.
Returns: string
method to_table(this, position, text_color, text_size)
Namespace types: MC
Parameters:
this (MC)
position (string)
text_color (color)
text_size (string)
method create_transition_matrix(this)
Namespace types: MC
Parameters:
this (MC)
method generate_transition_matrix(this)
Namespace types: MC
Parameters:
this (MC)
new_chain(states, name)
Parameters:
states (state )
name (string)
from_data(data, name)
Parameters:
data (string )
name (string)
method probability_at_step(this, target_step)
Namespace types: MC
Parameters:
this (MC)
target_step (int)
method state_at_step(this, start_state, target_state, target_step)
Namespace types: MC
Parameters:
this (MC)
start_state (int)
target_state (int)
target_step (int)
method forward(this, obs)
Namespace types: HMC
Parameters:
this (HMC)
obs (int )
method backward(this, obs)
Namespace types: HMC
Parameters:
this (HMC)
obs (int )
method viterbi(this, observations)
Namespace types: HMC
Parameters:
this (HMC)
observations (int )
method baumwelch(this, observations)
Namespace types: HMC
Parameters:
this (HMC)
observations (int )
Node
Target node.
Fields:
index (series int) : . Key index of the node.
probability (series float) : . Probability rate of activation.
state
State reference.
Fields:
name (series string) : . Name of the state.
index (series int) : . Key index of the state.
target_nodes (Node ) : . List of index references and probabilities to target states.
MC
Markov Chain reference object.
Fields:
name (series string) : . Name of the chain.
states (state ) : . List of state nodes and its name, index, targets and transition probabilities.
size (series int) : . Number of unique states
transitions (matrix) : . Transition matrix
HMC
Hidden Markov Chain reference object.
Fields:
name (series string) : . Name of thehidden chain.
states_hidden (state ) : . List of state nodes and its name, index, targets and transition probabilities.
states_obs (state ) : . List of state nodes and its name, index, targets and transition probabilities.
transitions (matrix) : . Transition matrix
emissions (matrix) : . Emission matrix
initial_distribution (float )

FunctionProbabilityViterbiLibrary "FunctionProbabilityViterbi"
The Viterbi Algorithm calculates the most likely sequence of hidden states *(called Viterbi path)*
that results in a sequence of observed events.
viterbi(observations, transitions, emissions, initial_distribution)
Calculate most probable path in a Markov model.
Parameters:
observations (int ) : array . Observation states data.
transitions (matrix) : matrix . Transition probability table, (HxH, H:Hidden states).
emissions (matrix) : matrix . Emission probability table, (OxH, O:Observed states).
initial_distribution (float ) : array . Initial probability distribution for the hidden states.
Returns: array. Most probable path.

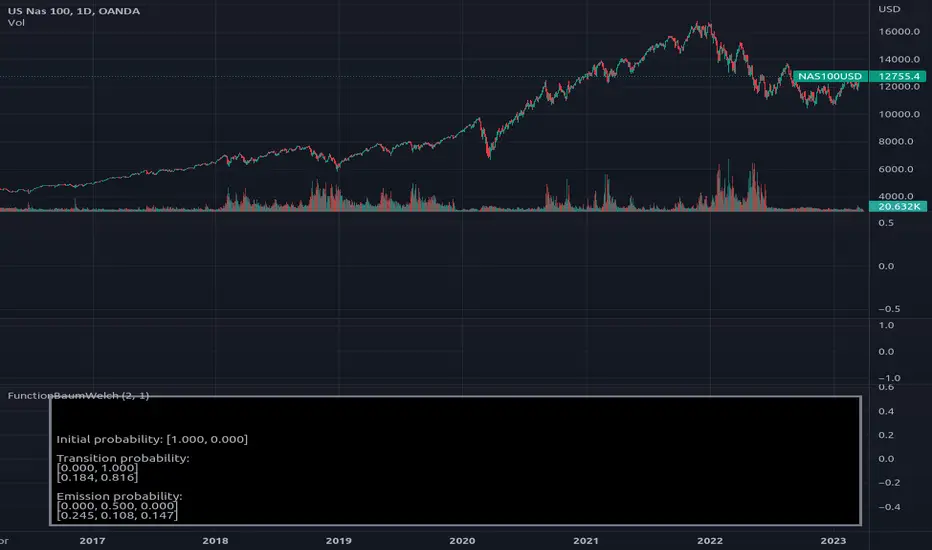
FunctionBaumWelchLibrary "FunctionBaumWelch"
Baum-Welch Algorithm, also known as Forward-Backward Algorithm, uses the well known EM algorithm
to find the maximum likelihood estimate of the parameters of a hidden Markov model given a set of observed
feature vectors.
---
### Function List:
> `forward (array pi, matrix a, matrix b, array obs)`
> `forward (array pi, matrix a, matrix b, array obs, bool scaling)`
> `backward (matrix a, matrix b, array obs)`
> `backward (matrix a, matrix b, array obs, array c)`
> `baumwelch (array observations, int nstates)`
> `baumwelch (array observations, array pi, matrix a, matrix b)`
---
### Reference:
> en.wikipedia.org
> github.com
> en.wikipedia.org
> www.rdocumentation.org
> www.rdocumentation.org
forward(pi, a, b, obs)
Computes forward probabilities for state `X` up to observation at time `k`, is defined as the
probability of observing sequence of observations `e_1 ... e_k` and that the state at time `k` is `X`.
Parameters:
pi (float ) : Initial probabilities.
a (matrix) : Transmissions, hidden transition matrix a or alpha = transition probability matrix of changing
states given a state matrix is size (M x M) where M is number of states.
b (matrix) : Emissions, matrix of observation probabilities b or beta = observation probabilities. Given
state matrix is size (M x O) where M is number of states and O is number of different
possible observations.
obs (int ) : List with actual state observation data.
Returns: - `matrix _alpha`: Forward probabilities. The probabilities are given on a logarithmic scale (natural logarithm). The first
dimension refers to the state and the second dimension to time.
forward(pi, a, b, obs, scaling)
Computes forward probabilities for state `X` up to observation at time `k`, is defined as the
probability of observing sequence of observations `e_1 ... e_k` and that the state at time `k` is `X`.
Parameters:
pi (float ) : Initial probabilities.
a (matrix) : Transmissions, hidden transition matrix a or alpha = transition probability matrix of changing
states given a state matrix is size (M x M) where M is number of states.
b (matrix) : Emissions, matrix of observation probabilities b or beta = observation probabilities. Given
state matrix is size (M x O) where M is number of states and O is number of different
possible observations.
obs (int ) : List with actual state observation data.
scaling (bool) : Normalize `alpha` scale.
Returns: - #### Tuple with:
> - `matrix _alpha`: Forward probabilities. The probabilities are given on a logarithmic scale (natural logarithm). The first
dimension refers to the state and the second dimension to time.
> - `array _c`: Array with normalization scale.
backward(a, b, obs)
Computes backward probabilities for state `X` and observation at time `k`, is defined as the probability of observing the sequence of observations `e_k+1, ... , e_n` under the condition that the state at time `k` is `X`.
Parameters:
a (matrix) : Transmissions, hidden transition matrix a or alpha = transition probability matrix of changing states
given a state matrix is size (M x M) where M is number of states
b (matrix) : Emissions, matrix of observation probabilities b or beta = observation probabilities. given state
matrix is size (M x O) where M is number of states and O is number of different possible observations
obs (int ) : Array with actual state observation data.
Returns: - `matrix _beta`: Backward probabilities. The probabilities are given on a logarithmic scale (natural logarithm). The first dimension refers to the state and the second dimension to time.
backward(a, b, obs, c)
Computes backward probabilities for state `X` and observation at time `k`, is defined as the probability of observing the sequence of observations `e_k+1, ... , e_n` under the condition that the state at time `k` is `X`.
Parameters:
a (matrix) : Transmissions, hidden transition matrix a or alpha = transition probability matrix of changing states
given a state matrix is size (M x M) where M is number of states
b (matrix) : Emissions, matrix of observation probabilities b or beta = observation probabilities. given state
matrix is size (M x O) where M is number of states and O is number of different possible observations
obs (int ) : Array with actual state observation data.
c (float ) : Array with Normalization scaling coefficients.
Returns: - `matrix _beta`: Backward probabilities. The probabilities are given on a logarithmic scale (natural logarithm). The first dimension refers to the state and the second dimension to time.
baumwelch(observations, nstates)
**(Random Initialization)** Baum–Welch algorithm is a special case of the expectation–maximization algorithm used to find the
unknown parameters of a hidden Markov model (HMM). It makes use of the forward-backward algorithm
to compute the statistics for the expectation step.
Parameters:
observations (int ) : List of observed states.
nstates (int)
Returns: - #### Tuple with:
> - `array _pi`: Initial probability distribution.
> - `matrix _a`: Transition probability matrix.
> - `matrix _b`: Emission probability matrix.
---
requires: `import RicardoSantos/WIPTensor/2 as Tensor`
baumwelch(observations, pi, a, b)
Baum–Welch algorithm is a special case of the expectation–maximization algorithm used to find the
unknown parameters of a hidden Markov model (HMM). It makes use of the forward-backward algorithm
to compute the statistics for the expectation step.
Parameters:
observations (int ) : List of observed states.
pi (float ) : Initial probaility distribution.
a (matrix) : Transmissions, hidden transition matrix a or alpha = transition probability matrix of changing states
given a state matrix is size (M x M) where M is number of states
b (matrix) : Emissions, matrix of observation probabilities b or beta = observation probabilities. given state
matrix is size (M x O) where M is number of states and O is number of different possible observations
Returns: - #### Tuple with:
> - `array _pi`: Initial probability distribution.
> - `matrix _a`: Transition probability matrix.
> - `matrix _b`: Emission probability matrix.
---
requires: `import RicardoSantos/WIPTensor/2 as Tensor`
VS Score [SpiritualHealer117]An experimental indicator that uses historical prices and readings of technical indicators to give the probability that stock and crypto prices will be in a certain range on the next close. This indicator may be helpful for options traders or for traders who want to see the probability of a move.
It classifies returns into five categories:
Extreme Rise - Over 2 standard deviations above normal returns
Rise - Between 0.5 standard deviations and 2 standard deviations above normal returns
Flat - Falling in the range of +/- 0.5 standard deviations of normal returns
Fall - Between 0.5 standard deviations and 2 standard deviations below normal returns
Extreme Fall - Over 2 standard deviations below normal returns
It is an adaptive probability model, which trains on the previous 1000 data points, and is calculated by creating probability vectors for the current reading of the PPO, MA, volume histogram, and previous return, and combining them into one probability vector.

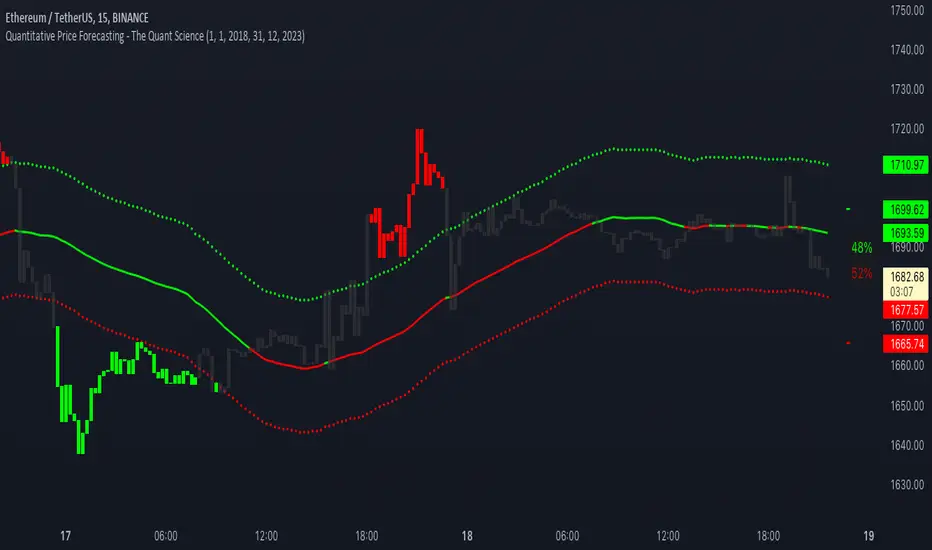
Quantitative Price Forecasting - The Quant ScienceThis script is a quantitative price forecasting indicator that forecasts price changes for a given asset.
The model aims to forecast future prices by analyzing past data within a selected time period. Mathematical probability is used to calculate whether starting from time X can lead to reaching prices Y1 and Y2. In this context, X represents the current selected time period, Y1 represents the selected percentage decrease, and Y2 represents the selected percentage increase. The probabilities are estimated using the simple average.
The simple average is displayed on the chart, showing in red the periods where the price is below the average and in green the periods where the price is above the average.
This powerful tool not only provides forecasts of future prices but also calculates the distribution of variations around the average. It then takes this information and creates an estimate of the average price variation around the simple average.
Using a mean-reverting logic, buying and selling opportunities are highlighted.
We recommend turning off the display of bars on your chart for a better experience when using this indicator.
Unlock the full potential of your trading strategy with our powerful indicator. By analyzing past price data, it provides accurate forecasts and calculates the probability of reaching specific price targets. Its mean-reverting logic highlights buying and selling opportunities, while the simple moving average displayed on the chart shows periods where the price is above or below the average. Additionally, it estimates the average variation of price around the simple average, giving you valuable insights into price movements. Don't miss out on this valuable tool that can take your trading to the next level
Triangulation : Statistically Approved ReversalsA lot of calculation, but a simple and effective result displayed on the chart.
It automatically identifies a very favorable period for a price reversal, by analyzing the daily and intraday price action statistics from the maximum of the most recent bars from the historical data. No repainting. Alerts can be set.
The statistical study is done in real time for each instrument. The probabilities therefore vary over time and adapt to the latest information collected by the indicator.
The time range of the data study can be changed by simply changing the UT :
- 30m = 3.5 last months feed statistics
- 15m = 52 last days feed statistics
- 5m = 17 last days feed statistics (recommanded)
HOW TO USE
This indicator informs when we are in a time period strongly favorable to reversal.
==> Crossing probabilities of different kinds, in price and in time => Triangulation of top and bottom !
HOW It WORK :
fractal statistics on high and low formation.
hour's probabilities of making the high/low of the day are crossed with day's probabilities of making the high/low of the week.
First for the day, we study:
- value of the probability compared to the average probabilities
- value of the coefficient between the high probability and the low probability
which we then refine for the hour, with the same calculation.
Result: bright color for a day + hour with high probability, weak color if the probability is low but remains the only possible bias. Between these two possibilities, intermediate colors are possible - just like looking for shorts if the day is bullish, if it is a high probability hour!
This color is displayed in the background, only if we are forming the high of the day for tops, and the low of the day for bottoms - detected with a stochastic.
All probabilities are studied in real time for the current asset.
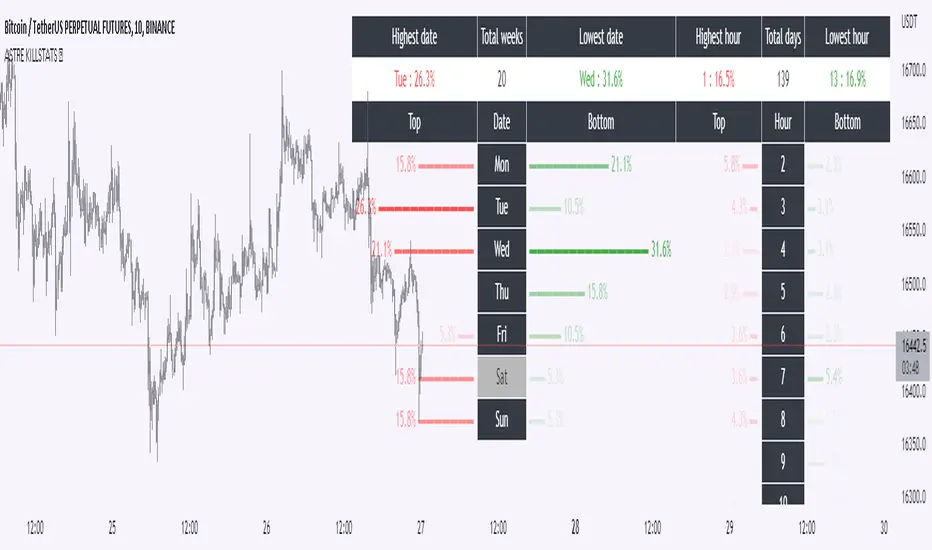
We will call this signal "killstats", for "killzones statistics"
fractal statistics on the probability of closure under specific predefined levels according to 36 cycles.
the probabilities of several cycles are studied, for example:
NY session versus London and Asian sessions, London session compared to its opening, NY session compared to its opening, "algorithmic cycles" ( 1h30), Opening of NY compared to its intersection with London..
Each cycle producing a probability of closing with respect to the opening price of each period. The periods are : (Etc/UTC)
15-18h / 15-16h / 9-13h / 14-17h / 18-22h / 10-12h / 9-10h30 / 10h30-12h / 12-13h30 / 13h30-15h / 15h-16h30 / 16h30-18h
The cycles can be superimposed, which allows to support or attenuate a signal for the key periods of the day: 9am-12pm, and 3pm-6pm. The period of the day covered by the study of cycles is 9h-22h.
Result : ==> a straight line with a half bell. Colors = almost transparent for 53% probability (low), and very intense for a high probability (75%). The line displayed corresponds to the opening price, which we are supposed to close within the time limit - before the end of the period, where the line stops.
If the price goes in the opposite direction to the one predicted by the statistics, then a background connects the price to the close level to be respected.
if direction and close is respected, nothing is displayed : there is no opportunity, no divergence between statistics and actual price moves.
By unchecking the "light mode", you can see each close level displayed on the chart, with the corresponding probability and the number of times the cycle was detected. The color varies from intense for a high probability (75%), to light for a low probability (53%)
We will call this signal "cyclic anomalies"
By default, as shown in the indicator presentation image, the "intersection only" option is checked: only the intersection between 1) killstats and 2) cyclic anomalies is displayed. (filter +-30% of killstats signals)
MORE INFORMATIONS
/!\ : during a backtest, it is necessary to refresh the studied data to benefit from the real time signals, and for that you have to use the replay mode. if "Backtesting informations?"is checked, labels are displayed on the graph to warn of the % distortion of the signals. I recommend using the replay mode every 250 candles, and every 1000 candles for premium accounts, to have real signals.
- Alerts can be set for killzone, or intersections ( As in presentation picture)
- The ideal use is in m5. It can trigger several times a day, sometimes in opposite directions, and sometimes not trigger for several days.
- Premium account have 20k candles data, and not 5k => signals may vary depending on your tradingview subscription.

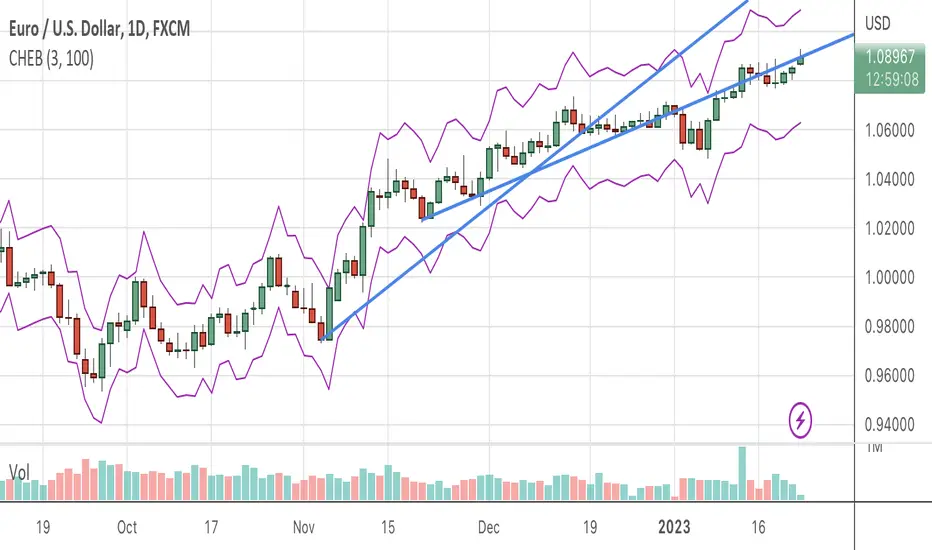
Chebyshevs BandsThis script calculates upper and lower bands using Chebyshev's inequality formula.
The main pros.: the band doesn't depend on particular distribution. It fits to any type of random variables. Also it allows to calculate bands for instruments with extremely high volatility.
Cons.: formula provides a rough estimation in some special cases like lognormal distribution.
Titan Investments|Quantitative THEMIS|Pro|BINANCE:BTCUSDTP:4hInvestment Strategy (Quantitative Trading)
| 🛑 | Watch "LIVE" and 'COPY' this strategy in real time:
🔗 Link: www.tradingview.com
Hello, welcome, feel free 🌹💐
Since the stone age to the most technological age, one thing has not changed, that which continues impress human beings the most, is the other human being!
Deep down, it's all very simple or very complicated, depends on how you look at it.
I believe that everyone was born to do something very well in life.
But few are those who have, let's use the word 'luck' .
Few are those who have the 'luck' to discover this thing.
That is why few are happy and successful in their jobs and professions.
Thank God I had this 'luck' , and discovered what I was born to do well.
And I was born to program. 👨💻
📋 Summary : Project Titan
0️⃣ : 🦄 Project Titan
1️⃣ : ⚖️ Quantitative THEMIS
2️⃣ : 🏛️ Titan Community
3️⃣ : 👨💻 Who am I ❔
4️⃣ : ❓ What is Statistical/Probabilistic Trading ❓
5️⃣ : ❓ How Statistical/Probabilistic Trading works ❓
6️⃣ : ❓ Why use a Statistical/Probabilistic system ❓
7️⃣ : ❓ Why the human brain is not prepared to do Trading ❓
8️⃣ : ❓ What is Backtest ❓
9️⃣ : ❓ How to build a Consistent system ❓
🔟 : ❓ What is a Quantitative Trading system ❓
1️⃣1️⃣ : ❓ How to build a Quantitative Trading system ❓
1️⃣2️⃣ : ❓ How to Exploit Market Anomalies ❓
1️⃣3️⃣ : ❓ What Defines a Robust, Profitable and Consistent System ❓
1️⃣4️⃣ : 🔧 Fixed Technical
1️⃣5️⃣ : ❌ Fixed Outputs : 🎯 TP(%) & 🛑SL(%)
1️⃣6️⃣ : ⚠️ Risk Profile
1️⃣7️⃣ : ⭕ Moving Exits : (Indicators)
1️⃣8️⃣ : 💸 Initial Capital
1️⃣9️⃣ : ⚙️ Entry Options
2️⃣0️⃣ : ❓ How to Automate this Strategy ❓ : 🤖 Automation : 'Third-Party Services'
2️⃣1️⃣ : ❓ How to Automate this Strategy ❓ : 🤖 Automation : 'Exchanges
2️⃣2️⃣ : ❓ How to Automate this Strategy ❓ : 🤖 Automation : 'Messaging Services'
2️⃣3️⃣ : ❓ How to Automate this Strategy ❓ : 🤖 Automation : '🧲🤖Copy-Trading'
2️⃣4️⃣ : ❔ Why be a Titan Pro 👽❔
2️⃣5️⃣ : ❔ Why be a Titan Aff 🛸❔
2️⃣6️⃣ : 📋 Summary : ⚖️ Strategy: Titan Investments|Quantitative THEMIS|Pro|BINANCE:BTCUSDTP:4h
2️⃣7️⃣ : 📊 PERFORMANCE : 🆑 Conservative
2️⃣8️⃣ : 📊 PERFORMANCE : Ⓜ️ Moderate
2️⃣9️⃣ : 📊 PERFORMANCE : 🅰 Aggressive
3️⃣0️⃣ : 🛠️ Roadmap
3️⃣1️⃣ : 🧻 Notes ❕
3️⃣2️⃣ : 🚨 Disclaimer ❕❗
3️⃣3️⃣ : ♻️ ® No Repaint
3️⃣4️⃣ : 🔒 Copyright ©️
3️⃣5️⃣ : 👏 Acknowledgments
3️⃣6️⃣ : 👮 House Rules : 📺 TradingView
3️⃣7️⃣ : 🏛️ Become a Titan Pro member 👽
3️⃣8️⃣ : 🏛️ Be a member Titan Aff 🛸
0️⃣ : 🦄 Project Titan
This is the first real, 100% automated Quantitative Strategy made available to the public and the pinescript community for TradingView.
You will be able to automate all signals of this strategy for your broker , centralized or decentralized and also for messaging services : Discord, Telegram or Twitter .
This is the first strategy of a larger project, in 2023, I will provide a total of 6 100% automated 'Quantitative' strategies to the pinescript community for TradingView.
The future strategies to be shared here will also be unique , never before seen, real 'Quantitative' bots with real, validated results in real operation.
Just like the 'Quantitative THEMIS' strategy, it will be something out of the loop throughout the pinescript/tradingview community, truly unique tools for building mutual wealth consistently and continuously for our community.
1️⃣ : ⚖️ Quantitative THEMIS : Titan Investments|Quantitative THEMIS|Pro|BINANCE:BTCUSDTP:4h
This is a truly unique and out of the curve strategy for BTC /USD .
A truly real strategy, with real, validated results and in real operation.
A unique tool for building mutual wealth, consistently and continuously for the members of the Titan community.
Initially we will operate on a monthly, quarterly, annual or biennial subscription service.
Our goal here is to build a great community, in exchange for an extremely fair value for the use of our truly unique tools, which bring and will bring real results to our community members.
With this business model it will be possible to provide all Titan users and community members with the purest and highest degree of sophistication in the market with pinescript for tradingview, providing unique and truly profitable strategies.
My goal here is to offer the best to our members!
The best 'pinescript' tradingview service in the world!
We are the only Start-Up in the world that will decentralize real and full access to truly real 'quantitative' tools that bring and will bring real results for mutual and ongoing wealth building for our community.
2️⃣ : 🏛️ Titan Community : 👽 Pro 🔁 Aff 🛸
Become a Titan Pro 👽
To get access to the strategy: "Quantitative THEMIS" , and future Titan strategies in a 100% automated way, along with all tutorials for automation.
Pro Plans: 30 Days, 90 Days, 12 Months, 24 Months.
👽 Pro 🅼 Monthly
👽 Pro 🆀 Quarterly
👽 Pro🅰 Annual
👽 Pro👾Two Years
You will have access to a truly unique system that is out of the curve .
A 100% real, 100% automated, tested, validated, profitable, and in real operation strategy.
Become a Titan Affiliate 🛸
By becoming a Titan Affiliate 🛸, you will automatically receive 50% of the value of each new subscription you refer .
You will receive 50% for any of the above plans that you refer .
This way we will encourage our community to grow in a fair and healthy way, because we know what we have in our hands and what we deliver real value to our users.
We are at the highest level of sophistication in the market, the consistency here and the results here speak for themselves.
So growing our community means growing mutual wealth and raising collective conscience.
Wealth must be created not divided.
And here we are creating mutual wealth on all ends and in all ways.
A non-zero sum system, where everybody wins.
3️⃣ : 👨💻 Who am I ❔
My name is FilipeSoh I am 26 years old, Technical Analyst, Trader, Computer Engineer, pinescript Specialist, with extensive experience in several languages and technologies.
For the last 4 years I have been focusing on developing, editing and creating pinescript indicators and strategies for Tradingview for people and myself.
Full-time passionate workaholic pinescript developer with over 10,000 hours of pinescript development.
• Pinescript expert ▬Tradingview.
• Specialist in Automated Trading
• Specialist in Quantitative Trading.
• Statistical/Probabilistic Trading Specialist - Mark Douglas Scholl.
• Inventor of the 'Classic Forecast' Indicators.
• Inventor of the 'Backtest Table'.
4️⃣ : ❓ What is Statistical/Probabilistic Trading ❓
Statistical/probabilistic trading is the only way to get a positive mathematical expectation regarding the market and consequently that is the only way to make money consistently from it.
I will present below some more details about the Quantitative THEMIS strategy, it is a real strategy, tested, validated and in real operation, 'Skin in the Game' , a consistent way to make money with statistical/probabilistic trading in a 100% automated.
I am a Technical Analyst , I used to be a Discretionary Trader , today I am 100% a Statistical Trader .
I've gotten rich and made a lot of money, and I've also lost a lot with 'leverage'.
That was a few years ago.
The book that changed everything for me was "Trading in The Zone" by Mark Douglas.
That's when I understood that the market is just a game of statistics and probability, like a casino!
It was then that I understood that the human brain is not prepared for trading, because it involves triggers and mental emotions.
And emotions in trading and in making trading decisions do not go well together, not in the long run, because you always have the burden of being wrong with the outcome of that particular position.
But remembering that the market is just a statistical game!
5️⃣ : ❓ How Statistical/Probabilistic Trading works ❓
Let's use a 'coin' as an example:
If we toss a 'coin' up 10 times.
Do you agree that it is impossible for us to know exactly the result of the 'plays' before they actually happen?
As in the example above, would you agree, that we cannot "guess" the outcome of a position before it actually happens?
As much as we cannot "guess" whether the coin will drop heads or tails on each flip.
We can analyze the "backtest" of the 10 moves made with that coin:
If we analyze the 10 moves and count the number of times the coin fell heads or tails in a specific sequence, we then have a percentage of times the coin fell heads or tails, so we have a 'backtest' of those moves.
Then on the next flip we can now assume a point or a favorable position for one side, the side with the highest probability .
In a nutshell, this is more or less how probabilistic statistical trading works.
As Statistical Traders we can never say whether such a Trader/Position we take will be a winner or a loser.
But still we can have a positive and consistent result in a "sequence" of trades, because before we even open a position, backtests have already been performed so we identify an anomaly and build a system that will have a positive statistical advantage in our favor over the market.
The advantage will not be in one trade itself, but in the "sequence" of trades as a whole!
Because our system will work like a casino, having a positive mathematical expectation relative to the players/market.
Design, develop, test models and systems that can take advantage of market anomalies, until they change.
Be the casino! - Mark Douglas
6️⃣ : ❓ Why use a Statistical/Probabilistic system ❓
In recent years I have focused and specialized in developing 100% automated trading systems, essentially for the cryptocurrency market.
I have developed many extremely robust and efficient systems, with positive mathematical expectation towards the market.
These are not complex systems per se , because here we want to avoid 'over-optimization' as much as possible.
As Da Vinci said: "Simplicity is the highest degree of sophistication".
I say this because I have tested, tried and developed hundreds of systems/strategies.
I believe I have programmed more than 10,000 unique indicators/strategies, because this is my passion and purpose in life.
I am passionate about what I do, completely!
I love statistical trading because it is the only way to get consistency in the long run!
This is why I have studied, applied, developed, and specialized in 100% automated cryptocurrency trading systems.
The reason why our systems are extremely "simple" is because, as I mentioned before, in statistical trading we want to exploit the market anomaly to the maximum, that is, this anomaly will change from time to time, usually we can exploit a trading system efficiently for about 6 to 12 months, or for a few years, that is; for fixed 'scalpers' systems.
Because at some point these anomalies will be identified , and from the moment they are identified they will be exploited and will stop being anomalies .
With the system presented here; you can even copy the indicators and input values shared here;
However; what I have to offer you is: it is me , our team , and our community !
That is, we will constantly monitor this system, for life , because our goal here is to create a unique , perpetual , profitable , and consistent system for our community.
Myself , our team and our community will keep this script periodically updated , to ensure the positive mathematical expectation of it.
So we don't mind sharing the current parameters and values , because the real value is also in the future updates that this system will receive from me and our team , guided by our culture and our community of real users !
As we are hosted on 'tradingview', all future updates for this strategy, will be implemented and updated automatically on your tradingview account.
What we want here is: to make sure you get gains from our system, because if you get gains , our ecosystem will grow as a whole in a healthy and scalable way, so we will be generating continuous mutual wealth and raising the collective consciousness .
People Need People: 3️⃣🅿
7️⃣ : ❓ Why the human brain is not prepared to do Trading ❓
Today my greatest skill is to develop statistically profitable and 100% automated strategies for 'pinescript' tradingview.
Note that I said: 'profitable' because in fact statistical trading is the only way to make money in a 'consistent' way from the market.
And consequently have a positive wealth curve every cycle, because we will be based on mathematics, not on feelings and news.
Because the human brain is not prepared to do trading.
Because trading is connected to the decision making of the cerebral cortex.
And the decision making is automatically linked to emotions, and emotions don't match with trading decision making, because in those moments, we can feel the best and also the worst sensations and emotions, and this certainly affects us and makes us commit grotesque mistakes!
That's why the human brain is not prepared to do trading.
If you want to participate in a fully automated, profitable and consistent trading system; be a Titan Pro 👽
I believe we are walking an extremely enriching path here, not only in terms of financial returns for our community, but also in terms of knowledge about probabilistic and automated statistical trading.
You will have access to an extremely robust system, which was built upon very strong concepts and foundations, and upon the world's main asset in a few years: Bitcoin .
We are the tip of the best that exists in the cryptocurrency market when it comes to probabilistic and automated statistical trading.
Result is result! Me being dressed or naked.
This is just the beginning!
But there is a way to consistently make money from the market.
Being the Casino! - Mark Douglas
8️⃣ : ❓ What is Backtest ❓
Imagine the market as a purely random system, but even in 'randomness' there are patterns.
So now imagine the market and statistical trading as follows:
Repeating the above 'coin' example, let's think of it as follows:
If we toss a coin up 10 times again.
It is impossible to know which flips will have heads or tails, correct?
But if we analyze these 10 tosses, then we will have a mathematical statistic of the past result, for example, 70 % of the tosses fell 'heads'.
That is:
7 moves fell on "heads" .
3 moves fell on "tails" .
So based on these conditions and on the generic backtest presented here, we could adopt " heads " as our system of moves, to have a statistical and probabilistic advantage in relation to the next move to be performed.
That is, if you define a system, based on backtests , that has a robust positive mathematical expectation in relation to the market you will have a profitable system.
For every move you make you will have a positive statistical advantage in your favor over the market before you even make the move.
Like a casino in relation to all its players!
The casino does not have an advantage over one specific player, but over all players, because it has a positive mathematical expectation about all the moves that night.
The casino will always have a positive statistical advantage over its players.
Note that there will always be real players who will make real, million-dollar bankrolls that night, but this condition is already built into the casino's 'strategy', which has a pre-determined positive statistical advantage of that night as a whole.
Statistical trading is the same thing, as long as you don't understand this you will keep losing money and consistently.
9️⃣ : ❓ How to build a Consistent system ❓
See most traders around the world perform trades believing that that specific position taken will make them filthy rich, because they simply believe faithfully that the position taken will be an undoubted winner, based on a trader's methodology: 'trading a trade' without analyzing the whole context, just using 'empirical' aspects in their system.
But if you think of trading, as a sequence of moves.
You see, 'a sequence' !
When we think statistically, it doesn't matter your result for this , or for the next specific trade , but the final sequence of trades as a whole.
As the market has a random system of results distribution , if your system has a positive statistical advantage in relation to the market, at the end of that sequence you'll have the biggest probability of having a winning bank.
That's how you do real trading!
And with consistency!
Trading is a long term game, but when you change the key you realize that it is a simple game to make money in a consistent way from the market, all you need is patience.
Even more when we are based on Bitcoin, which has its 'Halving' effect where, in theory, we will never lose money in 3 to 4 years intervals, due to its scarcity and the fact that Bitcoin is the 'discovery of digital scarcity' which makes it the digital gold, we believe in this thesis and we follow Satoshi's legacy.
So align Bitcoin with a probabilistic statistical trading system with a positive mathematical expectation of the market and 100% automated with the long term, and all you need is patience, and you will become rich.
In fact Bitcoin by itself is already a path, buy, wait for each halving and your wealth will be maintained.
No inflation, unlike fiat currencies.
This is a complete and extremely robust strategy, with the most current possible and 'not possible' techniques involved and applied here.
Today I am at another level in developing 100% automated 'quantitative' strategies.
I was born for this!
🔟 : ❓ What is a Quantitative Trading system ❓
In addition to having access to a revolutionary strategy you will have access to disruptive 100% multifunctional tables with the ability to perform 'backtests' for better tracking and monitoring of your system on a customized basis.
I would like to emphasize one thing, and that is that you keep this in mind.
Today my greatest skill in 'pinescript' is to build indicators, but mainly strategies, based on statistical and probabilistic trading, with a postive mathematical expectation in relation to the market, in a 100% automated way.
This with the goal of building a consistent and continuous positive equity curve through mathematics using data, converting it into statistical / probabilistic parameters and applying them to a Quantitative model.
Before becoming a Quantitative Trader , I was a Technical Analyst and a Discretionary Trader .
First as a position trader and then as a day trader.
Before becoming a Trader, I trained myself as a Technical Analyst , to masterly understand the shape and workings of the market in theory.
But everything changed when I met 'Mark Douglas' , when I got to know his works, that's when my head exploded 🤯, and I started to understand the market for good!
The market is nothing more than a 'random' system of distributing results.
See that I said: 'random' .
Do yourself a mental exercise.
Is there really such a thing as random ?
I believe not, as far as we know maybe the 'singularity'.
So thinking this way, to translate, the market is nothing more than a game of probability, statistics and pure mathematics.
Like a casino!
What happens is that most traders, whenever they take a position, take it with all the empirical certainty that such position will win or lose, and do not take into consideration the total sequence of results to understand their place in the market.
Understanding your place in the market gives you the ability to create and design systems that can exploit the present market anomaly, and thus make money statistically, consistently, and 100% automated.
Thinking of it this way, it is easy to make money from the market.
There are many ways to make money from the market, but the only consistent way I know of is through 'probabilistic and automated statistical trading'.
1️⃣1️⃣ : ❓ How to build a Quantitative Trading system ❓
There are some fundamental points that must be addressed here in order to understand what makes up a system based on statistics and probability applied to a quantitative model.
When we talk about 'discretionary' trading, it is a trading system based on human decisions after the defined 'empirical' conditions are met.
It is quite another thing to build a fully automated system without any human interference/interaction .
That said:
Building a statistically profitable system is perfectly possible, but this is a high level task , but with possible high rewards and consistent gains.
Here you will find a real "Skin In The Game" strategy.
With all due respect, but the vast majority of traders who post strategies on TradingView do not understand what they are doing.
Most of them do not understand the minimum complexity involved in the main variable for the construction of a real strategy, the mother variable: "strategy".
I say this by my own experience, because I have analyzed practically all the existing publications of TradingView + 200,000 indicators and strategies.
I breathe pinescript, I eat pinescript, I sleep pinescript, I bathe pinescript, I live TradingView.
But the main advantage for the TradingView users, is that all entry and exit orders made by this strategy can be checked and analyzed thoroughly, to validate and prove the veracity of this strategy, because this is a 100% real strategy.
Here there is a huge world of possibilities, but only one way to build a 'pinescript strategy' that will work correctly aligned to the real world with real results .
There are some fundamental points to take into consideration when building a profitable trading system:
The most important of these for me is: 'DrawDown' .
Followed by: 'Hit Rate' .
And only after that we use the parameter: 'Profit'.
See, this is because here, we are dealing with the 'imponderable' , and anything can happen in this scenario.
But there is one thing that makes us sleep peacefully at night, and that is: controlling losses .
That is, in other words: controlling the DrawDown .
The amateur is concerned with 'winning', the professional is concerned with conserving capital.
If we have the losses under control, then we can move on to the other two parameters: hit rate and profit.
See, the second most important factor in building a system is the hit rate.
I say this from my own experience.
I have worked with many systems with a 'low hit rate', but extremely profitable.
For example: systems with hit rates of 40 to 50%.
But as much as statistically and mathematically the profit is rewarding, operating systems with a low hit rate is always very stressful psychologically.
That's why there are two big reasons why when I build an automated trading system, I focus on the high hit rate of the system, they are
1 - To reduce psychological damage as much as possible .
2 - And more important , when we create a system with a 'high hit rate' , there is a huge intrinsic advantage here, that most statistic traders don't take in consideration.
That is: knowing more quickly when the system stops being functional.
The main advantage of a system with a high hit rate is: to identify when the system stops being functional and stop exploiting the market's anomaly.
Look: When we are talking about trading and random distribution of results on the market, do you agree that when we create a trading system, we are focused on exploring some anomaly of that market?
When that anomaly is verified by the market, it will stop being functional with time.
That's why trading systems, 'scalpers', especially for cryptocurrencies, need constant monitoring, quarterly, semi-annually or annually.
Because market movements change from time to time.
Because we go through different cycles from time to time, such as congestion cycles, accumulation , distribution , volatility , uptrends and downtrends .
1️⃣2️⃣ : ❓ How to Exploit Market Anomalies ❓
You see there is a very important point that must be stressed here.
As we are always trying to exploit an 'anomaly' in the market.
So the 'number' of indicators/tools that will integrate the system is of paramount importance.
But most traders do not take this into consideration.
To build a professional, robust, consistent, and profitable system, you don't need to use hundreds of indicators to build your setup.
This will actually make it harder to read when the setup stops working and needs some adjustment.
So focusing on a high hit rate is very important here, this is a fundamental principle that is widely ignored , and with a high hit rate, we can know much more accurately when the system is no longer functional much faster.
As Darwin said: "It is not the strongest or the most intelligent that wins the game of life, it is the most adapted.
So simple systems, as contradictory as it may seem, are more efficient, because they help to identify inflection points in the market much more quickly.
1️⃣3️⃣ : ❓ What Defines a Robust, Profitable and Consistent System ❓
See I have built, hundreds of thousands of indicators and 'pinescript' strategies, hundreds of thousands.
This is an extremely professional, robust and profitable system.
Based on the currency pairs: BTC /USDT
There are many ways and avenues to build a profitable trading setup/system.
And actually this is not a difficult task, taking in consideration, as the main factor here, that our trading and investment plan is for the long term, so consequently we will face scenarios with less noise.
He who is in a hurry eats raw.
As mentioned before.
Defining trends in pinescript is technically a simple task, the hardest task is to determine congestion zones with low volume and volatility, it's in these moments that many false signals are generated, and consequently is where most setups face their maximum DrawDown.
That's why this strategy was strictly and thoroughly planned, built on a very solid foundation, to avoid as much noise as possible, for a positive and consistent equity curve in each market cycle, 'Consistency' is our 'Mantra' around here.
1️⃣4️⃣ : 🔧 Fixed Technical
• Strategy: Titan Investments|Quantitative THEMIS|Pro|BINANCE:BTCUSDTP:4h
• Pair: BTC/USDTP
• Time Frame: 4 hours
• Broker: Binance (Recommended)
For a more conservative scenario, we have built the Quantitative THEMIS for the 4h time frame, with the main focus on consistency.
So we can avoid noise as much as possible!
1️⃣5️⃣ : ❌ Fixed Outputs : 🎯 TP(%) & 🛑SL(%)
In order to build a 'perpetual' system specific to BTC/USDT, it took a lot of testing, and more testing, and a lot of investment and research.
There is one initial and fundamental point that we can address to justify the incredible consistency presented here.
That fundamental point is our exit via Take Profit or Stop Loss percentage (%).
🎯 Take Profit (%)
🛑 Stop Loss (%)
See, today I have been testing some more advanced backtesting models for some cryptocurrency systems.
In which I perform 'backtest of backtest', i.e. we use a set of strategies each focused on a principle, operating individually, but they are part of something unique, i.e. we do 'backtests' of 'backtests' together.
What I mean is that we do a lot of backtesting around here.
I can assure you, that always the best output for a trading system is to set fixed output values!
In other words:
🎯 Take Profit (%)
🛑 Stop Loss (%)
This happens because statistically setting fixed exit structures in the vast majority of times, presents a superior result on the capital/equity curve, throughout history and for the vast majority of setups compared to other exit methods.
This is due to a mathematical principle of simplicity, 'avoiding more noise'.
Thus whenever the Quantitative THEMIS strategy takes a position it has a target and a defined maximum stop percentage.
1️⃣6️⃣ : ⚠️ Risk Profile
The strategy, currently has 3 risk profiles ⚠️ patterns for 'fixed percentage exits': Take Profit (%) and Stop Loss (%) .
They are: ⚠️ Rich's Profiles
✔️🆑 Conservative: 🎯 TP=2.7 % 🛑 SL=2.7 %
❌Ⓜ️ Moderate: 🎯 TP=2.8 % 🛑 SL=2.7 %
❌🅰 Aggressive: 🎯 TP=1.6 % 🛑 SL=6.9 %
You will be able to select and switch between the above options and profiles through the 'input' menu of the strategy by navigating to the "⚠️ Risk Profile" menu.
You can then select, test and apply the Risk Profile above that best suits your risk management, expectations and reality , as well as customize all the 'fixed exit' values through the TP and SL menus below.
1️⃣7️⃣ : ⭕ Moving Exits : (Indicators)
The strategy currently also has 'Moving Exits' based on indicator signals.
These are Moving Exits (Indicators)
📈 LONG : (EXIT)
🧃 (MAO) Short : true
📉 SHORT : (EXIT)
🧃 (MAO) Long: false
You can select and toggle between the above options through the 'input' menu of the strategy by navigating to the "LONG : Exit" and "SHORT : Exit" menu.
1️⃣8️⃣ : 💸 Initial Capital
By default the "Initial Capital" set for entries and backtests of this strategy is: 10000 $
You can set another value for the 'Starting Capital' through the tradingview menu under "properties" , and edit the value of the "Initial Capital" field.
This way you can set and test other 'Entry Values' for your trades, tests and backtests.
1️⃣9️⃣ : ⚙️ Entry Options
By default the 'order size' set for this strategy is 100 % of the 'initial capital' on each new trade.
You can set and test other entry options like : contracts , cash , % of equity
You should make these changes directly in the input menu of the strategy by navigating to the menu "⚙️ Properties : TradingView" below.
⚙️ Properties : (TradingView)
📊 Strategy Type: strategy.position_size != 1
📝💲 % Order Type: % of equity
📝💲 % Order Size: 100
Leverage: 1
So you can define and test other 'Entry Options' for your trades, tests and backtests.
2️⃣0️⃣ : ❓ How to Automate this Strategy ❓ : 🤖 Automation : 'Third-Party Services'
It is possible to automate the signals of this strategy for any centralized or decentralized broker, as well as for messaging services: Discord, Telegram and Twitter.
All in an extremely simple and uncomplicated way through the tutorials available in PDF /VIDEO for our Titan Pro 👽 subscriber community.
With our tutorials in PDF and Video it will be possible to automate the signals of this strategy for the chosen service in an extremely simple way with less than 10 steps only.
Tradingview naturally doesn't count with native integration between brokers and tradingview.
But it is possible to use 'third party services' to do the integration and automation between Tradingview and your centralized or decentralized broker.
Here are the standard, available and recommended 'third party services' to automate the signals from the 'Quantitative THEMIS' strategy on the tradingview for your broker:
1) Wundertrading (Recommended):
2) 3commas:
3) Zignaly:
4) Aleeert.com (Recommended):
5) Alertatron:
Note! 'Third party services' cannot perform 'withdrawals' via their key 'API', they can only open positions, so your funds will always be 'safe' in your brokerage firm, being traded via the 'API', when they receive an entry and exit signal from this strategy.
2️⃣1️⃣ : ❓ How to Automate this Strategy ❓ : 🤖 Automation : 'Exchanges
You can automate this strategy for any of the brokers below, through your broker's 'API' by connecting it to the 'third party automation services' for tradingview available and mentioned in the menu above:
1) Binance (Recommended)
2) Bitmex
3) Bybit
4) KuCoin
5) Deribit
6) OKX
7) Coinbase
8) Huobi
9) Bitfinex
10) Bitget
11) Bittrex
12) Bitstamp
13) Gate. io
14) Kraken
15) Gemini
16) Ascendex
17) VCCE
2️⃣2️⃣ : ❓ How to Automate this Strategy ❓ : 🤖 Automation : 'Messaging Services'
You can also automate and monitor the signals of this strategy much more efficiently by sending them to the following popular messaging services:
1) Discord
2) Telegram
3) Twitter
2️⃣3️⃣ : ❓ How to Automate this Strategy ❓ : 🤖 Automation : '🧲🤖Copy-Trading'
It will also be possible to copy/replicate the entries and exits of this strategy to your broker in an extremely simple and agile way, through the available copy-trader services.
This way it will be possible to replicate the signals of this strategy at each entry and exit to your broker through the API connecting it to the integrated copy-trader services available through the tradingview automation services below:
1) Wundetrading:
2) Zignaly:
2️⃣4️⃣ : ❔ Why be a Titan Pro 👽❔
I believe that today I am at another level in 'pinescript' development.
I consider myself today a true unicorn as a pinescript developer, someone unique and very rare.
If you choose another tool or another pinescript service, this tool will be just another one, with no real results.
But if you join our Titan community, you will have access to a unique tool! And you will get real results!
I already earn money consistently with statistical and automated trading and as an expert pinescript developer.
I am here to evolve my skills as much as possible, and one day become a pinescript 'Wizard'.
So excellence, quality and professionalism will always be my north here.
You will never find a developer like me, and who will take so seriously such a revolutionary project as this one. A Maverick! ▬ The man never stops!
Here you will find the highest degree of sophistication and development in the market for 'pinescript'.
You will get the best of me and the best of pinescript possible.
Let me show you how a professional in my field does it.
Become a Titan Pro Member 👽 and get Full Access to this strategy and all the Automation Tutorials.
Be the Titan in your life!
2️⃣5️⃣ : ❔ Why be a Titan Aff 🛸❔
Get financial return for your referrals, Decentralize the World, and raise the collective consciousness.
2️⃣6️⃣ : 📋 Summary : ⚖️ Strategy: Titan Investments|Quantitative THEMIS|Pro|BINANCE:BTCUSDTP:4h
® Titan Investimentos | Quantitative THEMIS ⚖️ | Pro 👽 2.6 | Dev: © FilipeSoh 🧙 | 🤖 100% Automated : Discord, Telegram, Twitter, Wundertrading, 3commas, Zignaly, Aleeert, Alertatron, Uniswap-v3 | BINANCE:BTCUSDTPERP 4h
🛒 Subscribe this strategy ❗️ Be a Titan Member 🏛️
🛒 Titan Pro 👽 🏛️ Titan Pro 👽 Version with ✔️100% Integrated Automation 🤖 and 📚 Automation Tutorials ✔️100% available at: (PDF/VIDEO)
🛒 Titan Affiliate 🛸 🏛️ Titan Affiliate 🛸 (Subscription Sale) 🔥 Receive 50% commission
📋 Summary : QT THEMIS ⚖️
🕵️♂️ Check This Strategy..................................................................0
🦄 ® Titan Investimentos...............................................................1
👨💻 © Developer..........................................................................2
📚 Signal Automation Tutorials : (PDF/VIDEO).......................................3
👨🔧 Revision...............................................................................4
📊 Table : (BACKTEST)..................................................................5
📊 Table : (INFORMATIONS).............................................................6
⚙️ Properties : (TRADINGVIEW)........................................................7
📆 Backtest : (TRADINGVIEW)..........................................................8
⚠️ Risk Profile...........................................................................9
🟢 On 🔴 Off : (LONG/SHORT).......................................................10
📈 LONG : (ENTRY)....................................................................11
📉 SHORT : (ENTRY)...................................................................12
📈 LONG : (EXIT).......................................................................13
📉 SHORT : (EXIT)......................................................................14
🧩 (EI) External Indicator.............................................................15
📡 (QT) Quantitative...................................................................16
🎠 (FF) Forecast......................................................................17
🅱 (BB) Bollinger Bands................................................................18
🧃 (MAP) Moving Average Primary......................................................19
🧃 (MAP) Labels.........................................................................20
🍔 (MAQ) Moving Average Quaternary.................................................21
🍟 (MACD) Moving Average Convergence Divergence...............................22
📣 (VWAP) Volume Weighted Average Price........................................23
🪀 (HL) HILO..........................................................................24
🅾 (OBV) On Balance Volume.........................................................25
🥊 (SAR) Stop and Reverse...........................................................26
🛡️ (DSR) Dynamic Support and Resistance..........................................27
🔊 (VD) Volume Directional..........................................................28
🧰 (RSI) Relative Momentum Index.................................................29
🎯 (TP) Take Profit %..................................................................30
🛑 (SL) Stop Loss %....................................................................31
🤖 Automation Selected...............................................................32
📱💻 Discord............................................................................33
📱💻 Telegram..........................................................................34
📱💻 Twitter...........................................................................35
🤖 Wundertrading......................................................................36
🤖 3commas............................................................................37
🤖 Zignaly...............................................................................38
🤖 Aleeert...............................................................................39
🤖 Alertatron...........................................................................40
🤖 Uniswap-v3..........................................................................41
🧲🤖 Copy-Trading....................................................................42
♻️ ® No Repaint........................................................................43
🔒 Copyright ©️..........................................................................44
🏛️ Be a Titan Member..................................................................45
Nº Active Users..........................................................................46
⏱ Time Left............................................................................47
| 0 | 🕵️♂️ Check This Strategy
🕵️♂️ Version Demo: 🐄 Version with ❌non-integrated automation 🤖 and 📚 Tutorials for automation ❌not available
🕵️♂️ Version Pro: 👽 Version with ✔️100% Integrated Automation 🤖 and 📚 Automation Tutorials ✔️100% available at: (PDF/VIDEO)
| 1 | 🦄 ® Titan Investimentos
Decentralizing the World 🗺
Raising the Collective Conscience 🗺
🦄Site:
🦄TradingView: www.tradingview.com
🦄Discord:
🦄Telegram:
🦄Youtube:
🦄Twitter:
🦄Instagram:
🦄TikTok:
🦄Linkedin:
🦄E-mail:
| 2 | 👨💻 © Developer
🧠 Developer: @FilipeSoh🧙
📺 TradingView: www.tradingview.com
☑️ Linkedin:
✅ Fiverr:
✅ Upwork:
🎥 YouTube:
🐤 Twitter:
🤳 Instagram:
| 3 | 📚 Signal Automation Tutorials : (PDF/VIDEO)
📚 Discord: 🔗 Link: 🔒Titan Pro👽
📚 Telegram: 🔗 Link: 🔒Titan Pro👽
📚 Twitter: 🔗 Link: 🔒Titan Pro👽
📚 Wundertrading: 🔗 Link: 🔒Titan Pro👽
📚 3comnas: 🔗 Link: 🔒Titan Pro👽
📚 Zignaly: 🔗 Link: 🔒Titan Pro👽
📚 Aleeert: 🔗 Link: 🔒Titan Pro👽
📚 Alertatron: 🔗 Link: 🔒Titan Pro👽
📚 Uniswap-v3: 🔗 Link: 🔒Titan Pro👽
📚 Copy-Trading: 🔗 Link: 🔒Titan Pro👽
| 4 | 👨🔧 Revision
👨🔧 Start Of Operations: 01 Jan 2019 21:00 -0300 💡 Start Of Operations (Skin in the game) : Revision 1.0
👨🔧 Previous Review: 01 Jan 2022 21:00 -0300 💡 Previous Review : Revision 2.0
👨🔧 Current Revision: 01 Jan 2023 21:00 -0300 💡 Current Revision : Revision 2.6
👨🔧 Next Revision: 28 May 2023 21:00 -0300 💡 Next Revision : Revision 2.7
| 5 | 📊 Table : (BACKTEST)
📊 Table: true
🖌️ Style: label.style_label_left
📐 Size: size_small
📏 Line: defval
🎨 Color: #131722
| 6 | 📊 Table : (INFORMATIONS)
📊 Table: false
🖌️ Style: label.style_label_right
📐 Size: size_small
📏 Line: defval
🎨 Color: #131722
| 7 | ⚙️ Properties : (TradingView)
📊 Strategy Type: strategy.position_size != 1
📝💲 % Order Type: % of equity
📝💲 % Order Size: 100 %
🚀 Leverage: 1
| 8 | 📆 Backtest : (TradingView)
🗓️ Mon: true
🗓️ Tue: true
🗓️ Wed: true
🗓️ Thu: true
🗓️ Fri: true
🗓️ Sat: true
🗓️ Sun: true
📆 Range: custom
📆 Start: UTC 31 Oct 2008 00:00
📆 End: UTC 31 Oct 2030 23:45
📆 Session: 0000-0000
📆 UTC: UTC
| 9 | ⚠️ Risk Profile
✔️🆑 Conservative: 🎯 TP=2.7 % 🛑 SL=2.7 %
❌Ⓜ️ Moderate: 🎯 TP=2.8 % 🛑 SL=2.7 %
❌🅰 Aggressive: 🎯 TP=1.6 % 🛑 SL=6.9 %
| 10 | 🟢 On 🔴 Off : (LONG/SHORT)
🟢📈 LONG: true
🟢📉 SHORT: true
| 11 | 📈 LONG : (ENTRY)
📡 (QT) Long: true
🧃 (MAP) Long: false
🅱 (BB) Long: false
🍟 (MACD) Long: false
🅾 (OBV) Long: false
| 12 | 📉 SHORT : (ENTRY)
📡 (QT) Short: true
🧃 (MAP) Short: false
🅱 (BB) Short: false
🍟 (MACD) Short: false
🅾 (OBV) Short: false
| 13 | 📈 LONG : (EXIT)
🧃 (MAP) Short: true
| 14 | 📉 SHORT : (EXIT)
🧃 (MAP) Long: false
| 15 | 🧩 (EI) External Indicator
🧩 (EI) Connect your external indicator/filter: false
🧩 (EI) Connect your indicator here (Study mode only): close
🧩 (EI) Connect your indicator here (Study mode only): close
| 16 | 📡 (QT) Quantitative
📡 (QT) Quantitative: true
📡 (QT) Market: BINANCE:BTCUSDTPERP
📡 (QT) Dice: openai
| 17 | 🎠 (FF) Forecast
🎠 (FF) Include current unclosed current candle: true
🎠 (FF) Forecast Type: flat
🎠 (FF) Nº of candles to use in linear regression: 3
| 18 | 🅱 (BB) Bollinger Bands
🅱 (BB) Bollinger Bands: true
🅱 (BB) Type: EMA
🅱 (BB) Period: 20
🅱 (BB) Source: close
🅱 (BB) Multiplier: 2
🅱 (BB) Linewidth: 0
🅱 (BB) Color: #131722
| 19 | 🧃 (MAP) Moving Average Primary
🧃 (MAP) Moving Average Primary: true
🧃 (MAP) BarColor: false
🧃 (MAP) Background: false
🧃 (MAP) Type: SMA
🧃 (MAP) Source: open
🧃 (MAP) Period: 100
🧃 (MAP) Multiplier: 2.0
🧃 (MAP) Linewidth: 2
🧃 (MAP) Color P: #42bda8
🧃 (MAP) Color N: #801922
| 20 | 🧃 (MAP) Labels
🧃 (MAP) Labels: true
🧃 (MAP) Style BUY ZONE: shape.labelup
🧃 (MAP) Color BUY ZONE: #42bda8
🧃 (MAP) Style SELL ZONE: shape.labeldown
🧃 (MAP) Color SELL ZONE: #801922
| 21 | 🍔 (MAQ) Moving Average Quaternary
🍔 (MAQ) Moving Average Quaternary: true
🍔 (MAQ) BarColor: false
🍔 (MAQ) Background: false
🍔 (MAQ) Type: SMA
🍔 (MAQ) Source: close
🍔 (MAQ) Primary: 14
🍔 (MAQ) Secondary: 22
🍔 (MAQ) Tertiary: 44
🍔 (MAQ) Quaternary: 16
🍔 (MAQ) Linewidth: 0
🍔 (MAQ) Color P: #42bda8
🍔 (MAQ) Color N: #801922
| 22 | 🍟 (MACD) Moving Average Convergence Divergence
🍟 (MACD) Macd Type: EMA
🍟 (MACD) Signal Type: EMA
🍟 (MACD) Source: close
🍟 (MACD) Fast: 12
🍟 (MACD) Slow: 26
🍟 (MACD) Smoothing: 9
| 23 | 📣 (VWAP) Volume Weighted Average Price
📣 (VWAP) Source: close
📣 (VWAP) Period: 340
📣 (VWAP) Momentum A: 84
📣 (VWAP) Momentum B: 150
📣 (VWAP) Average Volume: 1
📣 (VWAP) Multiplier: 1
📣 (VWAP) Diviser: 2
| 24 | 🪀 (HL) HILO
🪀 (HL) Type: SMA
🪀 (HL) Function: Maverick🧙
🪀 (HL) Source H: high
🪀 (HL) Source L: low
🪀 (HL) Period: 20
🪀 (HL) Momentum: 26
🪀 (HL) Diviser: 2
🪀 (HL) Multiplier: 1
| 25 | 🅾 (OBV) On Balance Volume
🅾 (OBV) Type: EMA
🅾 (OBV) Source: close
🅾 (OBV) Period: 16
🅾 (OBV) Diviser: 2
🅾 (OBV) Multiplier: 1
| 26 | 🥊 (SAR) Stop and Reverse
🥊 (SAR) Source: close
🥊 (SAR) High: 1.8
🥊 (SAR) Mid: 1.6
🥊 (SAR) Low: 1.6
🥊 (SAR) Diviser: 2
🥊 (SAR) Multiplier: 1
| 27 | 🛡️ (DSR) Dynamic Support and Resistance
🛡️ (DSR) Source D: close
🛡️ (DSR) Source R: high
🛡️ (DSR) Source S: low
🛡️ (DSR) Momentum R: 0
🛡️ (DSR) Momentum S: 2
🛡️ (DSR) Diviser: 2
🛡️ (DSR) Multiplier: 1
| 28 | 🔊 (VD) Volume Directional
🔊 (VD) Type: SMA
🔊 (VD) Period: 68
🔊 (VD) Momentum: 3.8
🔊 (VD) Diviser: 2
🔊 (VD) Multiplier: 1
| 29 | 🧰 (RSI) Relative Momentum Index
🧰 (RSI) Type UP: EMA
🧰 (RSI) Type DOWN: EMA
🧰 (RSI) Source: close
🧰 (RSI) Period: 29
🧰 (RSI) Smoothing: 22
🧰 (RSI) Momentum R: 64
🧰 (RSI) Momentum S: 142
🧰 (RSI) Diviser: 2
🧰 (RSI) Multiplier: 1
| 30 | 🎯 (TP) Take Profit %
🎯 (TP) Take Profit: false
🎯 (TP) %: 2.2
🎯 (TP) Color: #42bda8
🎯 (TP) Linewidth: 1
| 31 | 🛑 (SL) Stop Loss %
🛑 (SL) Stop Loss: false
🛑 (SL) %: 2.7
🛑 (SL) Color: #801922
🛑 (SL) Linewidth: 1
| 32 | 🤖 Automation : Discord | Telegram | Twitter | Wundertrading | 3commas | Zignaly | Aleeert | Alertatron | Uniswap-v3
🤖 Automation Selected : Discord
| 33 | 🤖 Discord
🔗 Link Discord: discord.com
🔗 Link 📚 Automation: 🔒Titan Pro👽
📱💻 Discord ▬ Enter Long: 🔒Titan Pro👽
📱💻 Discord ▬ Exit Long: 🔒Titan Pro👽
📱💻 Discord ▬ Enter Short: 🔒Titan Pro👽
📱💻 Discord ▬ Exit Short: 🔒Titan Pro👽
| 34 | 🤖 Telegram
🔗 Link Telegram: telegram.org
🔗 Link 📚 Automation: 🔒Titan Pro👽
📱💻 Telegram ▬ Enter Long: 🔒Titan Pro👽
📱💻 Telegram ▬ Exit Long: 🔒Titan Pro👽
📱💻 Telegram ▬ Enter Short: 🔒Titan Pro👽
📱💻 Telegram ▬ Exit Short: 🔒Titan Pro👽
| 35 | 🤖 Twitter
🔗 Link Twitter: twitter.com
🔗 Link 📚 Automation: 🔒Titan Pro👽
📱💻 Twitter ▬ Enter Long: 🔒Titan Pro👽
📱💻 Twitter ▬ Exit Long: 🔒Titan Pro👽
📱💻 Twitter ▬ Enter Short: 🔒Titan Pro👽
📱💻 Twitter ▬ Exit Short: 🔒Titan Pro👽
| 36 | 🤖 Wundertrading : Binance | Bitmex | Bybit | KuCoin | Deribit | OKX | Coinbase | Huobi | Bitfinex | Bitget
🔗 Link Wundertrading: wundertrading.com
🔗 Link 📚 Automation: 🔒Titan Pro👽
📱💻 Wundertrading ▬ Enter Long: 🔒Titan Pro👽
📱💻 Wundertrading ▬ Exit Long: 🔒Titan Pro👽
📱💻 Wundertrading ▬ Enter Short: 🔒Titan Pro👽
📱💻 Wundertrading ▬ Exit Short: 🔒Titan Pro👽
| 37 | 🤖 3commas : Binance | Bybit | OKX | Bitfinex | Coinbase | Deribit | Bitmex | Bittrex | Bitstamp | Gate.io | Kraken | Gemini | Huobi | KuCoin
🔗 Link 3commas: 3commas.io
🔗 Link 📚 Automation: 🔒Titan Pro👽
📱💻 3commas ▬ Enter Long: 🔒Titan Pro👽
📱💻 3commas ▬ Exit Long: 🔒Titan Pro👽
📱💻 3commas ▬ Enter Short: 🔒Titan Pro👽
📱💻 3commas ▬ Exit Short: 🔒Titan Pro👽
| 38 | 🤖 Zignaly : Binance | Ascendex | Bitmex | Kucoin | VCCE
🔗 Link Zignaly: zignaly.com
🔗 Link 📚 Automation: 🔒Titan Pro👽
🤖 Type Automation: Profit Sharing
🤖 Type Provider: Webook
🔑 Key: 🔒Titan Pro👽
🤖 pair: BTCUSDTP
🤖 exchange: binance
🤖 exchangeAccountType: futures
🤖 orderType: market
🚀 leverage: 1x
% positionSizePercentage: 100 %
💸 positionSizeQuote: 10000 $
🆔 signalId: @Signal1234
| 39 | 🤖 Aleeert : Binance
🔗 Link Aleeert: aleeert.com
🔗 Link 📚 Automation: 🔒Titan Pro👽
📱💻 Aleeert ▬ Enter Long: 🔒Titan Pro👽
📱💻 Aleeert ▬ Exit Long: 🔒Titan Pro👽
📱💻 Aleeert ▬ Enter Short: 🔒Titan Pro👽
📱💻 Aleeert ▬ Exit Short: 🔒Titan Pro👽
| 40 | 🤖 Alertatron : Binance | Bybit | Deribit | Bitmex
🔗 Link Alertatron: alertatron.com
🔗 Link 📚 Automation: 🔒Titan Pro👽
📱💻 Alertatron ▬ Enter Long: 🔒Titan Pro👽
📱💻 Alertatron ▬ Exit Long: 🔒Titan Pro👽
📱💻 Alertatron ▬ Enter Short: 🔒Titan Pro👽
📱💻 Alertatron ▬ Exit Short: 🔒Titan Pro👽
| 41 | 🤖 Uniswap-v3
🔗 Link Alertatron: uniswap.org
🔗 Link 📚 Automation: 🔒Titan Pro👽
📱💻 Uniswap-v3 ▬ Enter Long: 🔒Titan Pro👽
📱💻 Uniswap-v3 ▬ Exit Long: 🔒Titan Pro👽
📱💻 Uniswap-v3 ▬ Enter Short: 🔒Titan Pro👽
📱💻 Uniswap-v3 ▬ Exit Short: 🔒Titan Pro👽
| 42 | 🧲🤖 Copy-Trading : Zignaly | Wundertrading
🔗 Link 📚 Copy-Trading: 🔒Titan Pro👽
🧲🤖 Copy-Trading ▬ Zignaly: 🔒Titan Pro👽
🧲🤖 Copy-Trading ▬ Wundertrading: 🔒Titan Pro👽
| 43 | ♻️ ® Don't Repaint!
♻️ This Strategy does not Repaint!: ® Signs Do not repaint❕
♻️ This is a Real Strategy!: Quality : ® Titan Investimentos
📋️️ Get more information about Repainting here:
| 44 | 🔒 Copyright ©️
🔒 Copyright ©️: Copyright © 2023-2024 All rights reserved, ® Titan Investimentos
🔒 Copyright ©️: ® Titan Investimentos
🔒 Copyright ©️: Unique and Exclusive Strategy. All rights reserved
| 45 | 🏛️ Be a Titan Members
🏛️ Titan Pro 👽 Version with ✔️100% Integrated Automation 🤖 and 📚 Automation Tutorials ✔️100% available at: (PDF/VIDEO)
🏛️ Titan Affiliate 🛸 (Subscription Sale) 🔥 Receive 50% commission
| 46 | ⏱ Time Left
Time Left Titan Demo 🐄: ⏱♾ | ⏱ : ♾ Titan Demo 🐄 Version with ❌non-integrated automation 🤖 and 📚 Tutorials for automation ❌not available
Time Left Titan Pro 👽: 🔒Titan Pro👽 | ⏱ : Pro Plans: 30 Days, 90 Days, 12 Months, 24 Months. (👽 Pro 🅼 Monthly, 👽 Pro 🆀 Quarterly, 👽 Pro🅰 Annual, 👽 Pro👾Two Years)
| 47 | Nº Active Users
Nº Active Subscribers Titan Pro 👽: 5️⃣6️⃣ | 1✔️ 5✔️ 10✔️ 100❌ 1K❌ 10K❌ 50K❌ 100K❌ 1M❌ 10M❌ 100M❌ : ⏱ Active Users is updated every 24 hours (Check on indicator)
Nº Active Affiliates Titan Aff 🛸: 6️⃣ | 1✔️ 5✔️ 10❌ 100❌ 1K❌ 10K❌ 50K❌ 100K❌ 1M❌ 10M❌ 100M❌ : ⏱ Active Users is updated every 24 hours (Check on indicator)
2️⃣7️⃣ : 📊 PERFORMANCE : 🆑 Conservative
📊 Exchange: Binance
📊 Pair: BINANCE: BTCUSDTPERP
📊 TimeFrame: 4h
📊 Initial Capital: 10000 $
📊 Order Type: % equity
📊 Size Per Order: 100 %
📊 Commission: 0.03 %
📊 Pyramid: 1
• ⚠️ Risk Profile: 🆑 Conservative: 🎯 TP=2.7 % | 🛑 SL=2.7 %
• 📆All years: 🆑 Conservative: 🚀 Leverage 1️⃣x
📆 Start: September 23, 2019
📆 End: January 11, 2023
📅 Days: 1221
📅 Bars: 7325
Net Profit:
🟢 + 1669.89 %
💲 + 166989.43 USD
Total Close Trades:
⚪️ 369
Percent Profitable:
🟡 64.77 %
Profit Factor:
🟢 2.314
DrawDrown Maximum:
🔴 -24.82 %
💲 -10221.43 USD
Avg Trade:
💲 + 452.55 USD
✔️ Trades Winning: 239
❌ Trades Losing: 130
✔️ Average Gross Win: + 12.31 %
❌ Average Gross Loss: - 9.78 %
✔️ Maximum Consecutive Wins: 9
❌ Maximum Consecutive Losses: 6
% Average Gain Annual: 499.33 %
% Average Gain Monthly: 41.61 %
% Average Gain Weekly: 9.6 %
% Average Gain Day: 1.37 %
💲 Average Gain Annual: 49933 $
💲 Average Gain Monthly: 4161 $
💲 Average Gain Weekly: 960 $
💲 Average Gain Day: 137 $
• 📆 Year: 2020: 🆑 Conservative: 🚀 Leverage 1️⃣x
• 📆 Year: 2021: 🆑 Conservative: 🚀 Leverage 1️⃣x
• 📆 Year: 2022: 🆑 Conservative: 🚀 Leverage 1️⃣x
2️⃣8️⃣ : 📊 PERFORMANCE : Ⓜ️ Moderate
📊 Exchange: Binance
📊 Pair: BINANCE: BTCUSDTPERP
📊 TimeFrame: 4h
📊 Initial Capital: 10000 $
📊 Order Type: % equity
📊 Size Per Order: 100 %
📊 Commission: 0.03 %
📊 Pyramid: 1
• ⚠️ Risk Profile: Ⓜ️ Moderate: 🎯 TP=2.8 % | 🛑 SL=2.7 %
• 📆 All years: Ⓜ️ Moderate: 🚀 Leverage 1️⃣x
📆 Start: September 23, 2019
📆 End: January 11, 2023
📅 Days: 1221
📅 Bars: 7325
Net Profit:
🟢 + 1472.04 %
💲 + 147199.89 USD
Total Close Trades:
⚪️ 362
Percent Profitable:
🟡 63.26 %
Profit Factor:
🟢 2.192
DrawDrown Maximum:
🔴 -22.69 %
💲 -9269.33 USD
Avg Trade:
💲 + 406.63 USD
✔️ Trades Winning: 229
❌ Trades Losing : 133
✔️ Average Gross Win: + 11.82 %
❌ Average Gross Loss: - 9.29 %
✔️ Maximum Consecutive Wins: 9
❌ Maximum Consecutive Losses: 8
% Average Gain Annual: 440.15 %
% Average Gain Monthly: 36.68 %
% Average Gain Weekly: 8.46 %
% Average Gain Day: 1.21 %
💲 Average Gain Annual: 44015 $
💲 Average Gain Monthly: 3668 $
💲 Average Gain Weekly: 846 $
💲 Average Gain Day: 121 $
• 📆 Year: 2020: Ⓜ️ Moderate: 🚀 Leverage 1️⃣x
• 📆 Year: 2021: Ⓜ️ Moderate: 🚀 Leverage 1️⃣x
• 📆 Year: 2022: Ⓜ️ Moderate: 🚀 Leverage 1️⃣x
2️⃣9️⃣ : 📊 PERFORMANCE : 🅰 Aggressive
📊 Exchange: Binance
📊 Pair: BINANCE: BTCUSDTPERP
📊 TimeFrame: 4h
📊 Initial Capital: 10000 $
📊 Order Type: % equity
📊 Size Per Order: 100 %
📊 Commission: 0.03 %
📊 Pyramid: 1
• ⚠️ Risk Profile: 🅰 Aggressive: 🎯 TP=1.6 % | 🛑 SL=6.9 %
• 📆 All years: 🅰 Aggressive: 🚀 Leverage 1️⃣x
📆 Start: September 23, 2019
📆 End: January 11, 2023
📅 Days: 1221
📅 Bars: 7325
Net Profit:
🟢 + 989.38 %
💲 + 98938.38 USD
Total Close Trades:
⚪️ 380
Percent Profitable:
🟢 84.47 %
Profit Factor:
🟢 2.156
DrawDrown Maximum:
🔴 -17.88 %
💲 -9182.84 USD
Avg Trade:
💲 + 260.36 USD
✔️ Trades Winning: 321
❌ Trades Losing: 59
✔️ Average Gross Win: + 5.75 %
❌ Average Gross Loss: - 14.51 %
✔️ Maximum Consecutive Wins: 21
❌ Maximum Consecutive Losses: 6
% Average Gain Annual: 295.84 %
% Average Gain Monthly: 24.65 %
% Average Gain Weekly: 5.69 %
% Average Gain Day: 0.81 %
💲 Average Gain Annual: 29584 $
💲 Average Gain Monthly: 2465 $
💲 Average Gain Weekly: 569 $
💲 Average Gain Day: 81 $
• 📆 Year: 2020: 🅰 Aggressive: 🚀 Leverage 1️⃣x
• 📆 Year: 2021: 🅰 Aggressive: 🚀 Leverage 1️⃣x
• 📆 Year: 2022: 🅰 Aggressive: 🚀 Leverage 1️⃣x
3️⃣0️⃣ : 🛠️ Roadmap
🛠️• 14/ 01 /2023 : Titan THEMIS Launch
🛠️• Updates January/2023 :
• 📚 Tutorials for Automation 🤖 already Available : ✔️
• ✔️ Discord
• ✔️ Wundertrading
• ✔️ Zignaly
• 📚 Tutorials for Automation 🤖 In Preparation : ⭕
• ⭕ Telegram
• ⭕ Twitter
• ⭕ 3comnas
• ⭕ Aleeert
• ⭕ Alertatron
• ⭕ Uniswap-v3
• ⭕ Copy-Trading
🛠️• Updates February/2023 :
• 📰 Launch of advertising material for Titan Affiliates 🛸
• 🛍️🎥🖼️📊 (Sales Page/VSL/Videos/Creative/Infographics)
🛠️• 28/05/2023 : Titan THEMIS update ▬ Version 2.7
🛠️• 28/05/2023 : BOT BOB release ▬ Version 1.0
• (Native Titan THEMIS Automation - Through BOT BOB, a bot for automation of signals, indicators and strategies of TradingView, of own code ▬ in validation.
• BOT BOB
Automation/Connection :
• API - For Centralized Brokers.
• Smart Contracts - Wallet Web - For Decentralized Brokers.
• This way users can automate any indicator or strategy of TradingView and Titan in a decentralized, secure and simplified way.
• Without having the need to use 'third party services' for automating TradingView indicators and strategies like the ones available above.
🛠️• 28/05/2023 : Release ▬ Titan Culture Guide 📝
3️⃣1️⃣ : 🧻 Notes ❕
🧻 • Note ❕ The "Demo 🐄" version, ❌does not have 'integrated automation', to automate the signals of this strategy and enjoy a fully automated system, you need to have access to the Pro version with '100% integrated automation' and all the tutorials for automation available. Become a Titan Pro 👽
🧻 • Note ❕ You will also need to be a "Pro User or higher on Tradingview", to be able to use the webhook feature available only for 'paid' profiles on the platform.
With the webhook feature it is possible to send the signals of this strategy to almost anywhere, in our case to centralized or decentralized brokerages, also to popular messaging services such as: Discord, Telegram or Twiter.
3️⃣2️⃣ : 🚨 Disclaimer ❕❗
🚨 • Disclaimer ❕❕ Past positive result and performance of a system does not guarantee its positive result and performance for the future!
🚨 • Disclaimer ❗❗❗ When using this strategy: Titan Investments is totally Exempt from any claim of liability for losses. The responsibility on the management of your funds is solely yours. This is a very high risk/volatility market! Understand your place in the market.
3️⃣3️⃣ : ♻️ ® No Repaint
This Strategy does not Repaint! This is a real strategy!
3️⃣4️⃣ : 🔒 Copyright ©️
Copyright © 2022-2023 All rights reserved, ® Titan Investimentos
3️⃣5️⃣ : 👏 Acknowledgments
I want to start this message in thanks to TradingView and all the Pinescript community for all the 'magic' created here, a unique ecosystem! rich and healthy, a fertile soil, a 'new world' of possibilities, for a complete deepening and improvement of our best personal skills.
I leave here my immense thanks to the whole community: Tradingview, Pinecoders, Wizards and Moderators.
I was not born Rich .
Thanks to TradingView and pinescript and all its transformation.
I could develop myself and the best of me and the best of my skills.
And consequently build wealth and patrimony.
Gratitude.
One more story for the infinite book !
If you were born poor you were born to be rich !
Raising🔼 the level and raising🔼 the ruler! 📏
My work is my 'debauchery'! Do better! 💐🌹
Soul of a first-timer! Creativity Exudes! 🦄
This is the manifestation of God's magic in me. This is the best of me. 🧙
You will copy me, I know. So you owe me. 💋
My mission here is to raise the consciousness and self-esteem of all Titans and Titanids! Welcome! 🧘 🏛️
The only way to accomplish great work is to do what you love ! Before I learned to program I was wasting my life!
Death is the best creation of life .
Now you are the new , but in the not so distant future you will gradually become the old . Here I stay forever!
Playing the game like an Athlete! 🖼️ Enjoy and Enjoy 🍷 🗿
In honor of: BOB ☆
1 name, 3 letters, 3 possibilities, and if read backwards it's the same thing, a palindrome. ☘
Gratitude to the oracles that have enabled me the 'luck' to get this far: Dal&Ni&Fer
3️⃣6️⃣ : 👮 House Rules : 📺 TradingView
House Rules : This publication and strategy follows all TradingView house guidelines and rules:
📺 TradingView House Rules: www.tradingview.com
📺 Script publication rules: www.tradingview.com
📺 Vendor requirements: www.tradingview.com
📺 Links/References rules: www.tradingview.com
3️⃣7️⃣ : 🏛️ Become a Titan Pro member 👽
🟩 Titan Pro 👽 🟩
3️⃣8️⃣ : 🏛️ Be a member Titan Aff 🛸
🟥 Titan Affiliate 🛸 🟥
Titan Investments|Quantitative THEMIS|Demo|BINANCE:BTCUSDTP:4hInvestment Strategy (Quantitative Trading)
| 🛑 | Watch "LIVE" and 'COPY' this strategy in real time:
🔗 Link: www.tradingview.com
Hello, welcome, feel free 🌹💐
Since the stone age to the most technological age, one thing has not changed, that which continues impress human beings the most, is the other human being!
Deep down, it's all very simple or very complicated, depends on how you look at it.
I believe that everyone was born to do something very well in life.
But few are those who have, let's use the word 'luck' .
Few are those who have the 'luck' to discover this thing.
That is why few are happy and successful in their jobs and professions.
Thank God I had this 'luck' , and discovered what I was born to do well.
And I was born to program. 👨💻
📋 Summary : Project Titan
0️⃣ : 🦄 Project Titan
1️⃣ : ⚖️ Quantitative THEMIS
2️⃣ : 🏛️ Titan Community
3️⃣ : 👨💻 Who am I ❔
4️⃣ : ❓ What is Statistical/Probabilistic Trading ❓
5️⃣ : ❓ How Statistical/Probabilistic Trading works ❓
6️⃣ : ❓ Why use a Statistical/Probabilistic system ❓
7️⃣ : ❓ Why the human brain is not prepared to do Trading ❓
8️⃣ : ❓ What is Backtest ❓
9️⃣ : ❓ How to build a Consistent system ❓
🔟 : ❓ What is a Quantitative Trading system ❓
1️⃣1️⃣ : ❓ How to build a Quantitative Trading system ❓
1️⃣2️⃣ : ❓ How to Exploit Market Anomalies ❓
1️⃣3️⃣ : ❓ What Defines a Robust, Profitable and Consistent System ❓
1️⃣4️⃣ : 🔧 Fixed Technical
1️⃣5️⃣ : ❌ Fixed Outputs : 🎯 TP(%) & 🛑SL(%)
1️⃣6️⃣ : ⚠️ Risk Profile
1️⃣7️⃣ : ⭕ Moving Exits : (Indicators)
1️⃣8️⃣ : 💸 Initial Capital
1️⃣9️⃣ : ⚙️ Entry Options
2️⃣0️⃣ : ❓ How to Automate this Strategy ❓ : 🤖 Automation : 'Third-Party Services'
2️⃣1️⃣ : ❓ How to Automate this Strategy ❓ : 🤖 Automation : 'Exchanges
2️⃣2️⃣ : ❓ How to Automate this Strategy ❓ : 🤖 Automation : 'Messaging Services'
2️⃣3️⃣ : ❓ How to Automate this Strategy ❓ : 🤖 Automation : '🧲🤖Copy-Trading'
2️⃣4️⃣ : ❔ Why be a Titan Pro 👽❔
2️⃣5️⃣ : ❔ Why be a Titan Aff 🛸❔
2️⃣6️⃣ : 📋 Summary : ⚖️ Strategy: Titan Investments|Quantitative THEMIS|Demo|BINANCE:BTCUSDTP:4h
2️⃣7️⃣ : 📊 PERFORMANCE : 🆑 Conservative
2️⃣8️⃣ : 📊 PERFORMANCE : Ⓜ️ Moderate
2️⃣9️⃣ : 📊 PERFORMANCE : 🅰 Aggressive
3️⃣0️⃣ : 🛠️ Roadmap
3️⃣1️⃣ : 🧻 Notes ❕
3️⃣2️⃣ : 🚨 Disclaimer ❕❗
3️⃣3️⃣ : ♻️ ® No Repaint
3️⃣4️⃣ : 🔒 Copyright ©️
3️⃣5️⃣ : 👏 Acknowledgments
3️⃣6️⃣ : 👮 House Rules : 📺 TradingView
3️⃣7️⃣ : 🏛️ Become a Titan Pro member 👽
3️⃣8️⃣ : 🏛️ Be a member Titan Aff 🛸
0️⃣ : 🦄 Project Titan
This is the first real, 100% automated Quantitative Strategy made available to the public and the pinescript community for TradingView.
You will be able to automate all signals of this strategy for your broker , centralized or decentralized and also for messaging services : Discord, Telegram or Twitter .
This is the first strategy of a larger project, in 2023, I will provide a total of 6 100% automated 'Quantitative' strategies to the pinescript community for TradingView.
The future strategies to be shared here will also be unique , never before seen, real 'Quantitative' bots with real, validated results in real operation.
Just like the 'Quantitative THEMIS' strategy, it will be something out of the loop throughout the pinescript/tradingview community, truly unique tools for building mutual wealth consistently and continuously for our community.
1️⃣ : ⚖️ Quantitative THEMIS : Titan Investments|Quantitative THEMIS|Demo|BINANCE:BTCUSDTP:4h
This is a truly unique and out of the curve strategy for BTC /USD .
A truly real strategy, with real, validated results and in real operation.
A unique tool for building mutual wealth, consistently and continuously for the members of the Titan community.
Initially we will operate on a monthly, quarterly, annual or biennial subscription service.
Our goal here is to build a great community, in exchange for an extremely fair value for the use of our truly unique tools, which bring and will bring real results to our community members.
With this business model it will be possible to provide all Titan users and community members with the purest and highest degree of sophistication in the market with pinescript for tradingview, providing unique and truly profitable strategies.
My goal here is to offer the best to our members!
The best 'pinescript' tradingview service in the world!
We are the only Start-Up in the world that will decentralize real and full access to truly real 'quantitative' tools that bring and will bring real results for mutual and ongoing wealth building for our community.
2️⃣ : 🏛️ Titan Community : 👽 Pro 🔁 Aff 🛸
Become a Titan Pro 👽
To get access to the strategy: "Quantitative THEMIS" , and future Titan strategies in a 100% automated way, along with all tutorials for automation.
Pro Plans: 30 Days, 90 Days, 12 Months, 24 Months.
👽 Pro 🅼 Monthly
👽 Pro 🆀 Quarterly
👽 Pro🅰 Annual
👽 Pro👾Two Years
You will have access to a truly unique system that is out of the curve .
A 100% real, 100% automated, tested, validated, profitable, and in real operation strategy.
Become a Titan Affiliate 🛸
By becoming a Titan Affiliate 🛸, you will automatically receive 50% of the value of each new subscription you refer .
You will receive 50% for any of the above plans that you refer .
This way we will encourage our community to grow in a fair and healthy way, because we know what we have in our hands and what we deliver real value to our users.
We are at the highest level of sophistication in the market, the consistency here and the results here speak for themselves.
So growing our community means growing mutual wealth and raising collective conscience.
Wealth must be created not divided.
And here we are creating mutual wealth on all ends and in all ways.
A non-zero sum system, where everybody wins.
3️⃣ : 👨💻 Who am I ❔
My name is FilipeSoh I am 26 years old, Technical Analyst, Trader, Computer Engineer, pinescript Specialist, with extensive experience in several languages and technologies.
For the last 4 years I have been focusing on developing, editing and creating pinescript indicators and strategies for Tradingview for people and myself.
Full-time passionate workaholic pinescript developer with over 10,000 hours of pinescript development.
• Pinescript expert ▬Tradingview.
• Specialist in Automated Trading
• Specialist in Quantitative Trading.
• Statistical/Probabilistic Trading Specialist - Mark Douglas Scholl.
• Inventor of the 'Classic Forecast' Indicators.
• Inventor of the 'Backtest Table'.
4️⃣ : ❓ What is Statistical/Probabilistic Trading ❓
Statistical/probabilistic trading is the only way to get a positive mathematical expectation regarding the market and consequently that is the only way to make money consistently from it.
I will present below some more details about the Quantitative THEMIS strategy, it is a real strategy, tested, validated and in real operation, 'Skin in the Game' , a consistent way to make money with statistical/probabilistic trading in a 100% automated.
I am a Technical Analyst , I used to be a Discretionary Trader , today I am 100% a Statistical Trader .
I've gotten rich and made a lot of money, and I've also lost a lot with 'leverage'.
That was a few years ago.
The book that changed everything for me was "Trading in The Zone" by Mark Douglas.
That's when I understood that the market is just a game of statistics and probability, like a casino!
It was then that I understood that the human brain is not prepared for trading, because it involves triggers and mental emotions.
And emotions in trading and in making trading decisions do not go well together, not in the long run, because you always have the burden of being wrong with the outcome of that particular position.
But remembering that the market is just a statistical game!
5️⃣ : ❓ How Statistical/Probabilistic Trading works ❓
Let's use a 'coin' as an example:
If we toss a 'coin' up 10 times.
Do you agree that it is impossible for us to know exactly the result of the 'plays' before they actually happen?
As in the example above, would you agree, that we cannot "guess" the outcome of a position before it actually happens?
As much as we cannot "guess" whether the coin will drop heads or tails on each flip.
We can analyze the "backtest" of the 10 moves made with that coin:
If we analyze the 10 moves and count the number of times the coin fell heads or tails in a specific sequence, we then have a percentage of times the coin fell heads or tails, so we have a 'backtest' of those moves.
Then on the next flip we can now assume a point or a favorable position for one side, the side with the highest probability .
In a nutshell, this is more or less how probabilistic statistical trading works.
As Statistical Traders we can never say whether such a Trader/Position we take will be a winner or a loser.
But still we can have a positive and consistent result in a "sequence" of trades, because before we even open a position, backtests have already been performed so we identify an anomaly and build a system that will have a positive statistical advantage in our favor over the market.
The advantage will not be in one trade itself, but in the "sequence" of trades as a whole!
Because our system will work like a casino, having a positive mathematical expectation relative to the players/market.
Design, develop, test models and systems that can take advantage of market anomalies, until they change.
Be the casino! - Mark Douglas
6️⃣ : ❓ Why use a Statistical/Probabilistic system ❓
In recent years I have focused and specialized in developing 100% automated trading systems, essentially for the cryptocurrency market.
I have developed many extremely robust and efficient systems, with positive mathematical expectation towards the market.
These are not complex systems per se , because here we want to avoid 'over-optimization' as much as possible.
As Da Vinci said: "Simplicity is the highest degree of sophistication".
I say this because I have tested, tried and developed hundreds of systems/strategies.
I believe I have programmed more than 10,000 unique indicators/strategies, because this is my passion and purpose in life.
I am passionate about what I do, completely!
I love statistical trading because it is the only way to get consistency in the long run!
This is why I have studied, applied, developed, and specialized in 100% automated cryptocurrency trading systems.
The reason why our systems are extremely "simple" is because, as I mentioned before, in statistical trading we want to exploit the market anomaly to the maximum, that is, this anomaly will change from time to time, usually we can exploit a trading system efficiently for about 6 to 12 months, or for a few years, that is; for fixed 'scalpers' systems.
Because at some point these anomalies will be identified , and from the moment they are identified they will be exploited and will stop being anomalies .
With the system presented here; you can even copy the indicators and input values shared here;
However; what I have to offer you is: it is me , our team , and our community !
That is, we will constantly monitor this system, for life , because our goal here is to create a unique , perpetual , profitable , and consistent system for our community.
Myself , our team and our community will keep this script periodically updated , to ensure the positive mathematical expectation of it.
So we don't mind sharing the current parameters and values , because the real value is also in the future updates that this system will receive from me and our team , guided by our culture and our community of real users !
As we are hosted on 'tradingview', all future updates for this strategy, will be implemented and updated automatically on your tradingview account.
What we want here is: to make sure you get gains from our system, because if you get gains , our ecosystem will grow as a whole in a healthy and scalable way, so we will be generating continuous mutual wealth and raising the collective consciousness .
People Need People: 3️⃣🅿
7️⃣ : ❓ Why the human brain is not prepared to do Trading ❓
Today my greatest skill is to develop statistically profitable and 100% automated strategies for 'pinescript' tradingview.
Note that I said: 'profitable' because in fact statistical trading is the only way to make money in a 'consistent' way from the market.
And consequently have a positive wealth curve every cycle, because we will be based on mathematics, not on feelings and news.
Because the human brain is not prepared to do trading.
Because trading is connected to the decision making of the cerebral cortex.
And the decision making is automatically linked to emotions, and emotions don't match with trading decision making, because in those moments, we can feel the best and also the worst sensations and emotions, and this certainly affects us and makes us commit grotesque mistakes!
That's why the human brain is not prepared to do trading.
If you want to participate in a fully automated, profitable and consistent trading system; be a Titan Pro 👽
I believe we are walking an extremely enriching path here, not only in terms of financial returns for our community, but also in terms of knowledge about probabilistic and automated statistical trading.
You will have access to an extremely robust system, which was built upon very strong concepts and foundations, and upon the world's main asset in a few years: Bitcoin .
We are the tip of the best that exists in the cryptocurrency market when it comes to probabilistic and automated statistical trading.
Result is result! Me being dressed or naked.
This is just the beginning!
But there is a way to consistently make money from the market.
Being the Casino! - Mark Douglas
8️⃣ : ❓ What is Backtest ❓
Imagine the market as a purely random system, but even in 'randomness' there are patterns.
So now imagine the market and statistical trading as follows:
Repeating the above 'coin' example, let's think of it as follows:
If we toss a coin up 10 times again.
It is impossible to know which flips will have heads or tails, correct?
But if we analyze these 10 tosses, then we will have a mathematical statistic of the past result, for example, 70 % of the tosses fell 'heads'.
That is:
7 moves fell on "heads" .
3 moves fell on "tails" .
So based on these conditions and on the generic backtest presented here, we could adopt " heads " as our system of moves, to have a statistical and probabilistic advantage in relation to the next move to be performed.
That is, if you define a system, based on backtests , that has a robust positive mathematical expectation in relation to the market you will have a profitable system.
For every move you make you will have a positive statistical advantage in your favor over the market before you even make the move.
Like a casino in relation to all its players!
The casino does not have an advantage over one specific player, but over all players, because it has a positive mathematical expectation about all the moves that night.
The casino will always have a positive statistical advantage over its players.
Note that there will always be real players who will make real, million-dollar bankrolls that night, but this condition is already built into the casino's 'strategy', which has a pre-determined positive statistical advantage of that night as a whole.
Statistical trading is the same thing, as long as you don't understand this you will keep losing money and consistently.
9️⃣ : ❓ How to build a Consistent system ❓
See most traders around the world perform trades believing that that specific position taken will make them filthy rich, because they simply believe faithfully that the position taken will be an undoubted winner, based on a trader's methodology: 'trading a trade' without analyzing the whole context, just using 'empirical' aspects in their system.
But if you think of trading, as a sequence of moves.
You see, 'a sequence' !
When we think statistically, it doesn't matter your result for this , or for the next specific trade , but the final sequence of trades as a whole.
As the market has a random system of results distribution , if your system has a positive statistical advantage in relation to the market, at the end of that sequence you'll have the biggest probability of having a winning bank.
That's how you do real trading!
And with consistency!
Trading is a long term game, but when you change the key you realize that it is a simple game to make money in a consistent way from the market, all you need is patience.
Even more when we are based on Bitcoin, which has its 'Halving' effect where, in theory, we will never lose money in 3 to 4 years intervals, due to its scarcity and the fact that Bitcoin is the 'discovery of digital scarcity' which makes it the digital gold, we believe in this thesis and we follow Satoshi's legacy.
So align Bitcoin with a probabilistic statistical trading system with a positive mathematical expectation of the market and 100% automated with the long term, and all you need is patience, and you will become rich.
In fact Bitcoin by itself is already a path, buy, wait for each halving and your wealth will be maintained.
No inflation, unlike fiat currencies.
This is a complete and extremely robust strategy, with the most current possible and 'not possible' techniques involved and applied here.
Today I am at another level in developing 100% automated 'quantitative' strategies.
I was born for this!
🔟 : ❓ What is a Quantitative Trading system ❓
In addition to having access to a revolutionary strategy you will have access to disruptive 100% multifunctional tables with the ability to perform 'backtests' for better tracking and monitoring of your system on a customized basis.
I would like to emphasize one thing, and that is that you keep this in mind.
Today my greatest skill in 'pinescript' is to build indicators, but mainly strategies, based on statistical and probabilistic trading, with a postive mathematical expectation in relation to the market, in a 100% automated way.
This with the goal of building a consistent and continuous positive equity curve through mathematics using data, converting it into statistical / probabilistic parameters and applying them to a Quantitative model.
Before becoming a Quantitative Trader , I was a Technical Analyst and a Discretionary Trader .
First as a position trader and then as a day trader.
Before becoming a Trader, I trained myself as a Technical Analyst , to masterly understand the shape and workings of the market in theory.
But everything changed when I met 'Mark Douglas' , when I got to know his works, that's when my head exploded 🤯, and I started to understand the market for good!
The market is nothing more than a 'random' system of distributing results.
See that I said: 'random' .
Do yourself a mental exercise.
Is there really such a thing as random ?
I believe not, as far as we know maybe the 'singularity'.
So thinking this way, to translate, the market is nothing more than a game of probability, statistics and pure mathematics.
Like a casino!
What happens is that most traders, whenever they take a position, take it with all the empirical certainty that such position will win or lose, and do not take into consideration the total sequence of results to understand their place in the market.
Understanding your place in the market gives you the ability to create and design systems that can exploit the present market anomaly, and thus make money statistically, consistently, and 100% automated.
Thinking of it this way, it is easy to make money from the market.
There are many ways to make money from the market, but the only consistent way I know of is through 'probabilistic and automated statistical trading'.
1️⃣1️⃣ : ❓ How to build a Quantitative Trading system ❓
There are some fundamental points that must be addressed here in order to understand what makes up a system based on statistics and probability applied to a quantitative model.
When we talk about 'discretionary' trading, it is a trading system based on human decisions after the defined 'empirical' conditions are met.
It is quite another thing to build a fully automated system without any human interference/interaction .
That said:
Building a statistically profitable system is perfectly possible, but this is a high level task , but with possible high rewards and consistent gains.
Here you will find a real "Skin In The Game" strategy.
With all due respect, but the vast majority of traders who post strategies on TradingView do not understand what they are doing.
Most of them do not understand the minimum complexity involved in the main variable for the construction of a real strategy, the mother variable: "strategy".
I say this by my own experience, because I have analyzed practically all the existing publications of TradingView + 200,000 indicators and strategies.
I breathe pinescript, I eat pinescript, I sleep pinescript, I bathe pinescript, I live TradingView.
But the main advantage for the TradingView users, is that all entry and exit orders made by this strategy can be checked and analyzed thoroughly, to validate and prove the veracity of this strategy, because this is a 100% real strategy.
Here there is a huge world of possibilities, but only one way to build a 'pinescript strategy' that will work correctly aligned to the real world with real results .
There are some fundamental points to take into consideration when building a profitable trading system:
The most important of these for me is: 'DrawDown' .
Followed by: 'Hit Rate' .
And only after that we use the parameter: 'Profit'.
See, this is because here, we are dealing with the 'imponderable' , and anything can happen in this scenario.
But there is one thing that makes us sleep peacefully at night, and that is: controlling losses .
That is, in other words: controlling the DrawDown .
The amateur is concerned with 'winning', the professional is concerned with conserving capital.
If we have the losses under control, then we can move on to the other two parameters: hit rate and profit.
See, the second most important factor in building a system is the hit rate.
I say this from my own experience.
I have worked with many systems with a 'low hit rate', but extremely profitable.
For example: systems with hit rates of 40 to 50%.
But as much as statistically and mathematically the profit is rewarding, operating systems with a low hit rate is always very stressful psychologically.
That's why there are two big reasons why when I build an automated trading system, I focus on the high hit rate of the system, they are
1 - To reduce psychological damage as much as possible .
2 - And more important , when we create a system with a 'high hit rate' , there is a huge intrinsic advantage here, that most statistic traders don't take in consideration.
That is: knowing more quickly when the system stops being functional.
The main advantage of a system with a high hit rate is: to identify when the system stops being functional and stop exploiting the market's anomaly.
Look: When we are talking about trading and random distribution of results on the market, do you agree that when we create a trading system, we are focused on exploring some anomaly of that market?
When that anomaly is verified by the market, it will stop being functional with time.
That's why trading systems, 'scalpers', especially for cryptocurrencies, need constant monitoring, quarterly, semi-annually or annually.
Because market movements change from time to time.
Because we go through different cycles from time to time, such as congestion cycles, accumulation , distribution , volatility , uptrends and downtrends .
1️⃣2️⃣ : ❓ How to Exploit Market Anomalies ❓
You see there is a very important point that must be stressed here.
As we are always trying to exploit an 'anomaly' in the market.
So the 'number' of indicators/tools that will integrate the system is of paramount importance.
But most traders do not take this into consideration.
To build a professional, robust, consistent, and profitable system, you don't need to use hundreds of indicators to build your setup.
This will actually make it harder to read when the setup stops working and needs some adjustment.
So focusing on a high hit rate is very important here, this is a fundamental principle that is widely ignored , and with a high hit rate, we can know much more accurately when the system is no longer functional much faster.
As Darwin said: "It is not the strongest or the most intelligent that wins the game of life, it is the most adapted.
So simple systems, as contradictory as it may seem, are more efficient, because they help to identify inflection points in the market much more quickly.
1️⃣3️⃣ : ❓ What Defines a Robust, Profitable and Consistent System ❓
See I have built, hundreds of thousands of indicators and 'pinescript' strategies, hundreds of thousands.
This is an extremely professional, robust and profitable system.
Based on the currency pairs: BTC /USDT
There are many ways and avenues to build a profitable trading setup/system.
And actually this is not a difficult task, taking in consideration, as the main factor here, that our trading and investment plan is for the long term, so consequently we will face scenarios with less noise.
He who is in a hurry eats raw.
As mentioned before.
Defining trends in pinescript is technically a simple task, the hardest task is to determine congestion zones with low volume and volatility, it's in these moments that many false signals are generated, and consequently is where most setups face their maximum DrawDown.
That's why this strategy was strictly and thoroughly planned, built on a very solid foundation, to avoid as much noise as possible, for a positive and consistent equity curve in each market cycle, 'Consistency' is our 'Mantra' around here.
1️⃣4️⃣ : 🔧 Fixed Technical
• Strategy: Titan Investments|Quantitative THEMIS|Demo|BINANCE:BTCUSDTP:4h
• Pair: BTC/USDTP
• Time Frame: 4 hours
• Broker: Binance (Recommended)
For a more conservative scenario, we have built the Quantitative THEMIS for the 4h time frame, with the main focus on consistency.
So we can avoid noise as much as possible!
1️⃣5️⃣ : ❌ Fixed Outputs : 🎯 TP(%) & 🛑SL(%)
In order to build a 'perpetual' system specific to BTC/USDT, it took a lot of testing, and more testing, and a lot of investment and research.
There is one initial and fundamental point that we can address to justify the incredible consistency presented here.
That fundamental point is our exit via Take Profit or Stop Loss percentage (%).
🎯 Take Profit (%)
🛑 Stop Loss (%)
See, today I have been testing some more advanced backtesting models for some cryptocurrency systems.
In which I perform 'backtest of backtest', i.e. we use a set of strategies each focused on a principle, operating individually, but they are part of something unique, i.e. we do 'backtests' of 'backtests' together.
What I mean is that we do a lot of backtesting around here.
I can assure you, that always the best output for a trading system is to set fixed output values!
In other words:
🎯 Take Profit (%)
🛑 Stop Loss (%)
This happens because statistically setting fixed exit structures in the vast majority of times, presents a superior result on the capital/equity curve, throughout history and for the vast majority of setups compared to other exit methods.
This is due to a mathematical principle of simplicity, 'avoiding more noise'.
Thus whenever the Quantitative THEMIS strategy takes a position it has a target and a defined maximum stop percentage.
1️⃣6️⃣ : ⚠️ Risk Profile
The strategy, currently has 3 risk profiles ⚠️ patterns for 'fixed percentage exits': Take Profit (%) and Stop Loss (%) .
They are: ⚠️ Rich's Profiles
✔️🆑 Conservative: 🎯 TP=2.7 % 🛑 SL=2.7 %
❌Ⓜ️ Moderate: 🎯 TP=2.8 % 🛑 SL=2.7 %
❌🅰 Aggressive: 🎯 TP=1.6 % 🛑 SL=6.9 %
You will be able to select and switch between the above options and profiles through the 'input' menu of the strategy by navigating to the "⚠️ Risk Profile" menu.
You can then select, test and apply the Risk Profile above that best suits your risk management, expectations and reality , as well as customize all the 'fixed exit' values through the TP and SL menus below.
1️⃣7️⃣ : ⭕ Moving Exits : (Indicators)
The strategy currently also has 'Moving Exits' based on indicator signals.
These are Moving Exits (Indicators)
📈 LONG : (EXIT)
🧃 (MAO) Short : true
📉 SHORT : (EXIT)
🧃 (MAO) Long: false
You can select and toggle between the above options through the 'input' menu of the strategy by navigating to the "LONG : Exit" and "SHORT : Exit" menu.
1️⃣8️⃣ : 💸 Initial Capital
By default the "Initial Capital" set for entries and backtests of this strategy is: 10000 $
You can set another value for the 'Starting Capital' through the tradingview menu under "properties" , and edit the value of the "Initial Capital" field.
This way you can set and test other 'Entry Values' for your trades, tests and backtests.
1️⃣9️⃣ : ⚙️ Entry Options
By default the 'order size' set for this strategy is 100 % of the 'initial capital' on each new trade.
You can set and test other entry options like : contracts , cash , % of equity
You should make these changes directly in the input menu of the strategy by navigating to the menu "⚙️ Properties : TradingView" below.
⚙️ Properties : (TradingView)
📊 Strategy Type: strategy.position_size != 1
📝💲 % Order Type: % of equity
📝💲 % Order Size: 100
Leverage: 1
So you can define and test other 'Entry Options' for your trades, tests and backtests.
2️⃣0️⃣ : ❓ How to Automate this Strategy ❓ : 🤖 Automation : 'Third-Party Services'
It is possible to automate the signals of this strategy for any centralized or decentralized broker, as well as for messaging services: Discord, Telegram and Twitter.
All in an extremely simple and uncomplicated way through the tutorials available in PDF /VIDEO for our Titan Pro 👽 subscriber community.
With our tutorials in PDF and Video it will be possible to automate the signals of this strategy for the chosen service in an extremely simple way with less than 10 steps only.
Tradingview naturally doesn't count with native integration between brokers and tradingview.
But it is possible to use 'third party services' to do the integration and automation between Tradingview and your centralized or decentralized broker.
Here are the standard, available and recommended 'third party services' to automate the signals from the 'Quantitative THEMIS' strategy on the tradingview for your broker:
1) Wundertrading (Recommended):
2) 3commas:
3) Zignaly:
4) Aleeert.com (Recommended):
5) Alertatron:
Note! 'Third party services' cannot perform 'withdrawals' via their key 'API', they can only open positions, so your funds will always be 'safe' in your brokerage firm, being traded via the 'API', when they receive an entry and exit signal from this strategy.
2️⃣1️⃣ : ❓ How to Automate this Strategy ❓ : 🤖 Automation : 'Exchanges
You can automate this strategy for any of the brokers below, through your broker's 'API' by connecting it to the 'third party automation services' for tradingview available and mentioned in the menu above:
1) Binance (Recommended)
2) Bitmex
3) Bybit
4) KuCoin
5) Deribit
6) OKX
7) Coinbase
8) Huobi
9) Bitfinex
10) Bitget
11) Bittrex
12) Bitstamp
13) Gate. io
14) Kraken
15) Gemini
16) Ascendex
17) VCCE
2️⃣2️⃣ : ❓ How to Automate this Strategy ❓ : 🤖 Automation : 'Messaging Services'
You can also automate and monitor the signals of this strategy much more efficiently by sending them to the following popular messaging services:
1) Discord
2) Telegram
3) Twitter
2️⃣3️⃣ : ❓ How to Automate this Strategy ❓ : 🤖 Automation : '🧲🤖Copy-Trading'
It will also be possible to copy/replicate the entries and exits of this strategy to your broker in an extremely simple and agile way, through the available copy-trader services.
This way it will be possible to replicate the signals of this strategy at each entry and exit to your broker through the API connecting it to the integrated copy-trader services available through the tradingview automation services below:
1) Wundetrading:
2) Zignaly:
2️⃣4️⃣ : ❔ Why be a Titan Pro 👽❔
I believe that today I am at another level in 'pinescript' development.
I consider myself today a true unicorn as a pinescript developer, someone unique and very rare.
If you choose another tool or another pinescript service, this tool will be just another one, with no real results.
But if you join our Titan community, you will have access to a unique tool! And you will get real results!
I already earn money consistently with statistical and automated trading and as an expert pinescript developer.
I am here to evolve my skills as much as possible, and one day become a pinescript 'Wizard'.
So excellence, quality and professionalism will always be my north here.
You will never find a developer like me, and who will take so seriously such a revolutionary project as this one. A Maverick! ▬ The man never stops!
Here you will find the highest degree of sophistication and development in the market for 'pinescript'.
You will get the best of me and the best of pinescript possible.
Let me show you how a professional in my field does it.
Become a Titan Pro Member 👽 and get Full Access to this strategy and all the Automation Tutorials.
Be the Titan in your life!
2️⃣5️⃣ : ❔ Why be a Titan Aff 🛸❔
Get financial return for your referrals, Decentralize the World, and raise the collective consciousness.
2️⃣6️⃣ : 📋 Summary : ⚖️ Strategy: Titan Investments|Quantitative THEMIS|Demo|BINANCE:BTCUSDTP:4h
® Titan Investimentos | Quantitative THEMIS ⚖️ | Demo 🐄 2.6 | Dev: © FilipeSoh 🧙 | 🤖 100% Automated : Discord, Telegram, Twitter, Wundertrading, 3commas, Zignaly, Aleeert, Alertatron, Uniswap-v3 | BINANCE:BTCUSDTPERP 4h
🛒 Subscribe this strategy ❗️ Be a Titan Member 🏛️
🛒 Titan Pro 👽 🔗 🏛️ Titan Pro 👽 Version with ✔️100% Integrated Automation 🤖 and 📚 Automation Tutorials ✔️100% available at: (PDF/VIDEO)
🛒 Titan Affiliate 🛸 🔗 🏛️ Titan Affiliate 🛸 (Subscription Sale) 🔥 Receive 50% commission
📋 Summary : QT THEMIS ⚖️
🕵️♂️ Check This Strategy..................................................................0
🦄 ® Titan Investimentos...............................................................1
👨💻 © Developer..........................................................................2
📚 Signal Automation Tutorials : (PDF/VIDEO).......................................3
👨🔧 Revision...............................................................................4
📊 Table : (BACKTEST)..................................................................5
📊 Table : (INFORMATIONS).............................................................6
⚙️ Properties : (TRADINGVIEW)........................................................7
📆 Backtest : (TRADINGVIEW)..........................................................8
⚠️ Risk Profile...........................................................................9
🟢 On 🔴 Off : (LONG/SHORT).......................................................10
📈 LONG : (ENTRY)....................................................................11
📉 SHORT : (ENTRY)...................................................................12
📈 LONG : (EXIT).......................................................................13
📉 SHORT : (EXIT)......................................................................14
🧩 (EI) External Indicator.............................................................15
📡 (QT) Quantitative...................................................................16
🎠 (FF) Forecast......................................................................17
🅱 (BB) Bollinger Bands................................................................18
🧃 (MAP) Moving Average Primary......................................................19
🧃 (MAP) Labels.........................................................................20
🍔 (MAQ) Moving Average Quaternary.................................................21
🍟 (MACD) Moving Average Convergence Divergence...............................22
📣 (VWAP) Volume Weighted Average Price........................................23
🪀 (HL) HILO..........................................................................24
🅾 (OBV) On Balance Volume.........................................................25
🥊 (SAR) Stop and Reverse...........................................................26
🛡️ (DSR) Dynamic Support and Resistance..........................................27
🔊 (VD) Volume Directional..........................................................28
🧰 (RSI) Relative Momentum Index.................................................29
🎯 (TP) Take Profit %..................................................................30
🛑 (SL) Stop Loss %....................................................................31
🤖 Automation Selected...............................................................32
📱💻 Discord............................................................................33
📱💻 Telegram..........................................................................34
📱💻 Twitter...........................................................................35
🤖 Wundertrading......................................................................36
🤖 3commas............................................................................37
🤖 Zignaly...............................................................................38
🤖 Aleeert...............................................................................39
🤖 Alertatron...........................................................................40
🤖 Uniswap-v3..........................................................................41
🧲🤖 Copy-Trading....................................................................42
♻️ ® No Repaint........................................................................43
🔒 Copyright ©️..........................................................................44
🏛️ Be a Titan Member..................................................................45
Nº Active Users..........................................................................46
⏱ Time Left............................................................................47
| 0 | 🕵️♂️ Check This Strategy
🕵️♂️ Version Demo: 🐄 Version with ❌non-integrated automation 🤖 and 📚 Tutorials for automation ❌not available
🕵️♂️ Version Pro: 👽 Version with ✔️100% Integrated Automation 🤖 and 📚 Automation Tutorials ✔️100% available at: (PDF/VIDEO)
| 1 | 🦄 ® Titan Investimentos
Decentralizing the World 🗺
Raising the Collective Conscience 🗺
🦄Site:
🦄TradingView: www.tradingview.com
🦄Discord:
🦄Telegram:
🦄Youtube:
🦄Twitter:
🦄Instagram:
🦄TikTok:
🦄Linkedin:
🦄E-mail:
| 2 | 👨💻 © Developer
🧠 Developer: @FilipeSoh🧙
📺 TradingView: www.tradingview.com
☑️ Linkedin:
✅ Fiverr:
✅ Upwork:
🎥 YouTube:
🐤 Twitter:
🤳 Instagram:
| 3 | 📚 Signal Automation Tutorials : (PDF/VIDEO)
📚 Discord: 🔗 Link: 🔒Titan Pro👽
📚 Telegram: 🔗 Link: 🔒Titan Pro👽
📚 Twitter: 🔗 Link: 🔒Titan Pro👽
📚 Wundertrading: 🔗 Link: 🔒Titan Pro👽
📚 3comnas: 🔗 Link: 🔒Titan Pro👽
📚 Zignaly: 🔗 Link: 🔒Titan Pro👽
📚 Aleeert: 🔗 Link: 🔒Titan Pro👽
📚 Alertatron: 🔗 Link: 🔒Titan Pro👽
📚 Uniswap-v3: 🔗 Link: 🔒Titan Pro👽
📚 Copy-Trading: 🔗 Link: 🔒Titan Pro👽
| 4 | 👨🔧 Revision
👨🔧 Start Of Operations: 01 Jan 2019 21:00 -0300 💡 Start Of Operations (Skin in the game) : Revision 1.0
👨🔧 Previous Review: 01 Jan 2022 21:00 -0300 💡 Previous Review : Revision 2.0
👨🔧 Current Revision: 01 Jan 2023 21:00 -0300 💡 Current Revision : Revision 2.6
👨🔧 Next Revision: 28 May 2023 21:00 -0300 💡 Next Revision : Revision 2.7
| 5 | 📊 Table : (BACKTEST)
📊 Table: true
🖌️ Style: label.style_label_left
📐 Size: size_small
📏 Line: defval
🎨 Color: #131722
| 6 | 📊 Table : (INFORMATIONS)
📊 Table: false
🖌️ Style: label.style_label_right
📐 Size: size_small
📏 Line: defval
🎨 Color: #131722
| 7 | ⚙️ Properties : (TradingView)
📊 Strategy Type: strategy.position_size != 1
📝💲 % Order Type: % of equity
📝💲 % Order Size: 100 %
🚀 Leverage: 1
| 8 | 📆 Backtest : (TradingView)
🗓️ Mon: true
🗓️ Tue: true
🗓️ Wed: true
🗓️ Thu: true
🗓️ Fri: true
🗓️ Sat: true
🗓️ Sun: true
📆 Range: custom
📆 Start: UTC 31 Oct 2008 00:00
📆 End: UTC 31 Oct 2030 23:45
📆 Session: 0000-0000
📆 UTC: UTC
| 9 | ⚠️ Risk Profile
✔️🆑 Conservative: 🎯 TP=2.7 % 🛑 SL=2.7 %
❌Ⓜ️ Moderate: 🎯 TP=2.8 % 🛑 SL=2.7 %
❌🅰 Aggressive: 🎯 TP=1.6 % 🛑 SL=6.9 %
| 10 | 🟢 On 🔴 Off : (LONG/SHORT)
🟢📈 LONG: true
🟢📉 SHORT: true
| 11 | 📈 LONG : (ENTRY)
📡 (QT) Long: true
🧃 (MAP) Long: false
🅱 (BB) Long: false
🍟 (MACD) Long: false
🅾 (OBV) Long: false
| 12 | 📉 SHORT : (ENTRY)
📡 (QT) Short: true
🧃 (MAP) Short: false
🅱 (BB) Short: false
🍟 (MACD) Short: false
🅾 (OBV) Short: false
| 13 | 📈 LONG : (EXIT)
🧃 (MAP) Short: true
| 14 | 📉 SHORT : (EXIT)
🧃 (MAP) Long: false
| 15 | 🧩 (EI) External Indicator
🧩 (EI) Connect your external indicator/filter: false
🧩 (EI) Connect your indicator here (Study mode only): close
🧩 (EI) Connect your indicator here (Study mode only): close
| 16 | 📡 (QT) Quantitative
📡 (QT) Quantitative: true
📡 (QT) Market: BINANCE:BTCUSDTPERP
📡 (QT) Dice: openai
| 17 | 🎠 (FF) Forecast
🎠 (FF) Include current unclosed current candle: true
🎠 (FF) Forecast Type: flat
🎠 (FF) Nº of candles to use in linear regression: 3
| 18 | 🅱 (BB) Bollinger Bands
🅱 (BB) Bollinger Bands: true
🅱 (BB) Type: EMA
🅱 (BB) Period: 20
🅱 (BB) Source: close
🅱 (BB) Multiplier: 2
🅱 (BB) Linewidth: 0
🅱 (BB) Color: #131722
| 19 | 🧃 (MAP) Moving Average Primary
🧃 (MAP) Moving Average Primary: true
🧃 (MAP) BarColor: false
🧃 (MAP) Background: false
🧃 (MAP) Type: SMA
🧃 (MAP) Source: open
🧃 (MAP) Period: 100
🧃 (MAP) Multiplier: 2.0
🧃 (MAP) Linewidth: 2
🧃 (MAP) Color P: #42bda8
🧃 (MAP) Color N: #801922
| 20 | 🧃 (MAP) Labels
🧃 (MAP) Labels: true
🧃 (MAP) Style BUY ZONE: shape.labelup
🧃 (MAP) Color BUY ZONE: #42bda8
🧃 (MAP) Style SELL ZONE: shape.labeldown
🧃 (MAP) Color SELL ZONE: #801922
| 21 | 🍔 (MAQ) Moving Average Quaternary
🍔 (MAQ) Moving Average Quaternary: true
🍔 (MAQ) BarColor: false
🍔 (MAQ) Background: false
🍔 (MAQ) Type: SMA
🍔 (MAQ) Source: close
🍔 (MAQ) Primary: 14
🍔 (MAQ) Secondary: 22
🍔 (MAQ) Tertiary: 44
🍔 (MAQ) Quaternary: 16
🍔 (MAQ) Linewidth: 0
🍔 (MAQ) Color P: #42bda8
🍔 (MAQ) Color N: #801922
| 22 | 🍟 (MACD) Moving Average Convergence Divergence
🍟 (MACD) Macd Type: EMA
🍟 (MACD) Signal Type: EMA
🍟 (MACD) Source: close
🍟 (MACD) Fast: 12
🍟 (MACD) Slow: 26
🍟 (MACD) Smoothing: 9
| 23 | 📣 (VWAP) Volume Weighted Average Price
📣 (VWAP) Source: close
📣 (VWAP) Period: 340
📣 (VWAP) Momentum A: 84
📣 (VWAP) Momentum B: 150
📣 (VWAP) Average Volume: 1
📣 (VWAP) Multiplier: 1
📣 (VWAP) Diviser: 2
| 24 | 🪀 (HL) HILO
🪀 (HL) Type: SMA
🪀 (HL) Function: Maverick🧙
🪀 (HL) Source H: high
🪀 (HL) Source L: low
🪀 (HL) Period: 20
🪀 (HL) Momentum: 26
🪀 (HL) Diviser: 2
🪀 (HL) Multiplier: 1
| 25 | 🅾 (OBV) On Balance Volume
🅾 (OBV) Type: EMA
🅾 (OBV) Source: close
🅾 (OBV) Period: 16
🅾 (OBV) Diviser: 2
🅾 (OBV) Multiplier: 1
| 26 | 🥊 (SAR) Stop and Reverse
🥊 (SAR) Source: close
🥊 (SAR) High: 1.8
🥊 (SAR) Mid: 1.6
🥊 (SAR) Low: 1.6
🥊 (SAR) Diviser: 2
🥊 (SAR) Multiplier: 1
| 27 | 🛡️ (DSR) Dynamic Support and Resistance
🛡️ (DSR) Source D: close
🛡️ (DSR) Source R: high
🛡️ (DSR) Source S: low
🛡️ (DSR) Momentum R: 0
🛡️ (DSR) Momentum S: 2
🛡️ (DSR) Diviser: 2
🛡️ (DSR) Multiplier: 1
| 28 | 🔊 (VD) Volume Directional
🔊 (VD) Type: SMA
🔊 (VD) Period: 68
🔊 (VD) Momentum: 3.8
🔊 (VD) Diviser: 2
🔊 (VD) Multiplier: 1
| 29 | 🧰 (RSI) Relative Momentum Index
🧰 (RSI) Type UP: EMA
🧰 (RSI) Type DOWN: EMA
🧰 (RSI) Source: close
🧰 (RSI) Period: 29
🧰 (RSI) Smoothing: 22
🧰 (RSI) Momentum R: 64
🧰 (RSI) Momentum S: 142
🧰 (RSI) Diviser: 2
🧰 (RSI) Multiplier: 1
| 30 | 🎯 (TP) Take Profit %
🎯 (TP) Take Profit: false
🎯 (TP) %: 2.2
🎯 (TP) Color: #42bda8
🎯 (TP) Linewidth: 1
| 31 | 🛑 (SL) Stop Loss %
🛑 (SL) Stop Loss: false
🛑 (SL) %: 2.7
🛑 (SL) Color: #801922
🛑 (SL) Linewidth: 1
| 32 | 🤖 Automation : Discord | Telegram | Twitter | Wundertrading | 3commas | Zignaly | Aleeert | Alertatron | Uniswap-v3
🤖 Automation Selected : Discord
| 33 | 🤖 Discord
🔗 Link Discord:
🔗 Link 📚 Automation: 🔒Titan Pro👽
📱💻 Discord ▬ Enter Long: 🔒Titan Pro👽
📱💻 Discord ▬ Exit Long: 🔒Titan Pro👽
📱💻 Discord ▬ Enter Short: 🔒Titan Pro👽
📱💻 Discord ▬ Exit Short: 🔒Titan Pro👽
| 34 | 🤖 Telegram
🔗 Link Telegram:
🔗 Link 📚 Automation: 🔒Titan Pro👽
📱💻 Telegram ▬ Enter Long: 🔒Titan Pro👽
📱💻 Telegram ▬ Exit Long: 🔒Titan Pro👽
📱💻 Telegram ▬ Enter Short: 🔒Titan Pro👽
📱💻 Telegram ▬ Exit Short: 🔒Titan Pro👽
| 35 | 🤖 Twitter
🔗 Link Twitter:
🔗 Link 📚 Automation: 🔒Titan Pro👽
📱💻 Twitter ▬ Enter Long: 🔒Titan Pro👽
📱💻 Twitter ▬ Exit Long: 🔒Titan Pro👽
📱💻 Twitter ▬ Enter Short: 🔒Titan Pro👽
📱💻 Twitter ▬ Exit Short: 🔒Titan Pro👽
| 36 | 🤖 Wundertrading : Binance | Bitmex | Bybit | KuCoin | Deribit | OKX | Coinbase | Huobi | Bitfinex | Bitget
🔗 Link Wundertrading:
🔗 Link 📚 Automation: 🔒Titan Pro👽
📱💻 Wundertrading ▬ Enter Long: 🔒Titan Pro👽
📱💻 Wundertrading ▬ Exit Long: 🔒Titan Pro👽
📱💻 Wundertrading ▬ Enter Short: 🔒Titan Pro👽
📱💻 Wundertrading ▬ Exit Short: 🔒Titan Pro👽
| 37 | 🤖 3commas : Binance | Bybit | OKX | Bitfinex | Coinbase | Deribit | Bitmex | Bittrex | Bitstamp | Gate.io | Kraken | Gemini | Huobi | KuCoin
🔗 Link 3commas:
🔗 Link 📚 Automation: 🔒Titan Pro👽
📱💻 3commas ▬ Enter Long: 🔒Titan Pro👽
📱💻 3commas ▬ Exit Long: 🔒Titan Pro👽
📱💻 3commas ▬ Enter Short: 🔒Titan Pro👽
📱💻 3commas ▬ Exit Short: 🔒Titan Pro👽
| 38 | 🤖 Zignaly : Binance | Ascendex | Bitmex | Kucoin | VCCE
🔗 Link Zignaly:
🔗 Link 📚 Automation: 🔒Titan Pro👽
🤖 Type Automation: Profit Sharing
🤖 Type Provider: Webook
🔑 Key: 🔒Titan Pro👽
🤖 pair: BTCUSDTP
🤖 exchange: binance
🤖 exchangeAccountType: futures
🤖 orderType: market
🚀 leverage: 1x
% positionSizePercentage: 100 %
💸 positionSizeQuote: 10000 $
🆔 signalId: @Signal1234
| 39 | 🤖 Aleeert : Binance
🔗 Link Aleeert:
🔗 Link 📚 Automation: 🔒Titan Pro👽
📱💻 Aleeert ▬ Enter Long: 🔒Titan Pro👽
📱💻 Aleeert ▬ Exit Long: 🔒Titan Pro👽
📱💻 Aleeert ▬ Enter Short: 🔒Titan Pro👽
📱💻 Aleeert ▬ Exit Short: 🔒Titan Pro👽
| 40 | 🤖 Alertatron : Binance | Bybit | Deribit | Bitmex
🔗 Link Alertatron:
🔗 Link 📚 Automation: 🔒Titan Pro👽
📱💻 Alertatron ▬ Enter Long: 🔒Titan Pro👽
📱💻 Alertatron ▬ Exit Long: 🔒Titan Pro👽
📱💻 Alertatron ▬ Enter Short: 🔒Titan Pro👽
📱💻 Alertatron ▬ Exit Short: 🔒Titan Pro👽
| 41 | 🤖 Uniswap-v3
🔗 Link Alertatron:
🔗 Link 📚 Automation: 🔒Titan Pro👽
📱💻 Uniswap-v3 ▬ Enter Long: 🔒Titan Pro👽
📱💻 Uniswap-v3 ▬ Exit Long: 🔒Titan Pro👽
📱💻 Uniswap-v3 ▬ Enter Short: 🔒Titan Pro👽
📱💻 Uniswap-v3 ▬ Exit Short: 🔒Titan Pro👽
| 42 | 🧲🤖 Copy-Trading : Zignaly | Wundertrading
🔗 Link 📚 Copy-Trading: 🔒Titan Pro👽
🧲🤖 Copy-Trading ▬ Zignaly: 🔒Titan Pro👽
🧲🤖 Copy-Trading ▬ Wundertrading: 🔒Titan Pro👽
| 43 | ♻️ ® Don't Repaint!
♻️ This Strategy does not Repaint!: ® Signs Do not repaint❕
♻️ This is a Real Strategy!: Quality : ® Titan Investimentos
📋️️ Get more information about Repainting here:
| 44 | 🔒 Copyright ©️
🔒 Copyright ©️: Copyright © 2023-2024 All rights reserved, ® Titan Investimentos
🔒 Copyright ©️: ® Titan Investimentos
🔒 Copyright ©️: Unique and Exclusive Strategy. All rights reserved
| 45 | 🏛️ Be a Titan Members
🏛️ Titan Pro 👽 Version with ✔️100% Integrated Automation 🤖 and 📚 Automation Tutorials ✔️100% available at: (PDF/VIDEO)
🏛️ Titan Affiliate 🛸 (Subscription Sale) 🔥 Receive 50% commission
| 46 | ⏱ Time Left
Time Left Titan Demo 🐄: ⏱♾ | ⏱ : ♾ Titan Demo 🐄 Version with ❌non-integrated automation 🤖 and 📚 Tutorials for automation ❌not available
Time Left Titan Pro 👽: 🔒Titan Pro👽 | ⏱ : Pro Plans: 30 Days, 90 Days, 12 Months, 24 Months. (👽 Pro 🅼 Monthly, 👽 Pro 🆀 Quarterly, 👽 Pro🅰 Annual, 👽 Pro👾Two Years)
| 47 | Nº Active Users
Nº Active Subscribers Titan Pro 👽: 5️⃣6️⃣ | 1✔️ 5✔️ 10✔️ 100❌ 1K❌ 10K❌ 50K❌ 100K❌ 1M❌ 10M❌ 100M❌ : ⏱ Active Users is updated every 24 hours (Check on indicator)
Nº Active Affiliates Titan Aff 🛸: 6️⃣ | 1✔️ 5✔️ 10❌ 100❌ 1K❌ 10K❌ 50K❌ 100K❌ 1M❌ 10M❌ 100M❌ : ⏱ Active Users is updated every 24 hours (Check on indicator)
2️⃣7️⃣ : 📊 PERFORMANCE : 🆑 Conservative
📊 Exchange: Binance
📊 Pair: BINANCE: BTCUSDTPERP
📊 TimeFrame: 4h
📊 Initial Capital: 10000 $
📊 Order Type: % equity
📊 Size Per Order: 100 %
📊 Commission: 0.03 %
📊 Pyramid: 1
• ⚠️ Risk Profile: 🆑 Conservative: 🎯 TP=2.7 % | 🛑 SL=2.7 %
• 📆All years: 🆑 Conservative: 🚀 Leverage 1️⃣x
📆 Start: September 23, 2019
📆 End: January 11, 2023
📅 Days: 1221
📅 Bars: 7325
Net Profit:
🟢 + 1669.89 %
💲 + 166989.43 USD
Total Close Trades:
⚪️ 369
Percent Profitable:
🟡 64.77 %
Profit Factor:
🟢 2.314
DrawDrown Maximum:
🔴 -24.82 %
💲 -10221.43 USD
Avg Trade:
💲 + 452.55 USD
✔️ Trades Winning: 239
❌ Trades Losing: 130
✔️ Average Gross Win: + 12.31 %
❌ Average Gross Loss: - 9.78 %
✔️ Maximum Consecutive Wins: 9
❌ Maximum Consecutive Losses: 6
% Average Gain Annual: 499.33 %
% Average Gain Monthly: 41.61 %
% Average Gain Weekly: 9.6 %
% Average Gain Day: 1.37 %
💲 Average Gain Annual: 49933 $
💲 Average Gain Monthly: 4161 $
💲 Average Gain Weekly: 960 $
💲 Average Gain Day: 137 $
• 📆 Year: 2020: 🆑 Conservative: 🚀 Leverage 1️⃣x
• 📆 Year: 2021: 🆑 Conservative: 🚀 Leverage 1️⃣x
• 📆 Year: 2022: 🆑 Conservative: 🚀 Leverage 1️⃣x
2️⃣8️⃣ : 📊 PERFORMANCE : Ⓜ️ Moderate
📊 Exchange: Binance
📊 Pair: BINANCE: BTCUSDTPERP
📊 TimeFrame: 4h
📊 Initial Capital: 10000 $
📊 Order Type: % equity
📊 Size Per Order: 100 %
📊 Commission: 0.03 %
📊 Pyramid: 1
• ⚠️ Risk Profile: Ⓜ️ Moderate: 🎯 TP=2.8 % | 🛑 SL=2.7 %
• 📆 All years: Ⓜ️ Moderate: 🚀 Leverage 1️⃣x
📆 Start: September 23, 2019
📆 End: January 11, 2023
📅 Days: 1221
📅 Bars: 7325
Net Profit:
🟢 + 1472.04 %
💲 + 147199.89 USD
Total Close Trades:
⚪️ 362
Percent Profitable:
🟡 63.26 %
Profit Factor:
🟢 2.192
DrawDrown Maximum:
🔴 -22.69 %
💲 -9269.33 USD
Avg Trade:
💲 + 406.63 USD
✔️ Trades Winning: 229
❌ Trades Losing : 133
✔️ Average Gross Win: + 11.82 %
❌ Average Gross Loss: - 9.29 %
✔️ Maximum Consecutive Wins: 9
❌ Maximum Consecutive Losses: 8
% Average Gain Annual: 440.15 %
% Average Gain Monthly: 36.68 %
% Average Gain Weekly: 8.46 %
% Average Gain Day: 1.21 %
💲 Average Gain Annual: 44015 $
💲 Average Gain Monthly: 3668 $
💲 Average Gain Weekly: 846 $
💲 Average Gain Day: 121 $
• 📆 Year: 2020: Ⓜ️ Moderate: 🚀 Leverage 1️⃣x
• 📆 Year: 2021: Ⓜ️ Moderate: 🚀 Leverage 1️⃣x
• 📆 Year: 2022: Ⓜ️ Moderate: 🚀 Leverage 1️⃣x
2️⃣9️⃣ : 📊 PERFORMANCE : 🅰 Aggressive
📊 Exchange: Binance
📊 Pair: BINANCE: BTCUSDTPERP
📊 TimeFrame: 4h
📊 Initial Capital: 10000 $
📊 Order Type: % equity
📊 Size Per Order: 100 %
📊 Commission: 0.03 %
📊 Pyramid: 1
• ⚠️ Risk Profile: 🅰 Aggressive: 🎯 TP=1.6 % | 🛑 SL=6.9 %
• 📆 All years: 🅰 Aggressive: 🚀 Leverage 1️⃣x
📆 Start: September 23, 2019
📆 End: January 11, 2023
📅 Days: 1221
📅 Bars: 7325
Net Profit:
🟢 + 989.38 %
💲 + 98938.38 USD
Total Close Trades:
⚪️ 380
Percent Profitable:
🟢 84.47 %
Profit Factor:
🟢 2.156
DrawDrown Maximum:
🔴 -17.88 %
💲 -9182.84 USD
Avg Trade:
💲 + 260.36 USD
✔️ Trades Winning: 321
❌ Trades Losing: 59
✔️ Average Gross Win: + 5.75 %
❌ Average Gross Loss: - 14.51 %
✔️ Maximum Consecutive Wins: 21
❌ Maximum Consecutive Losses: 6
% Average Gain Annual: 295.84 %
% Average Gain Monthly: 24.65 %
% Average Gain Weekly: 5.69 %
% Average Gain Day: 0.81 %
💲 Average Gain Annual: 29584 $
💲 Average Gain Monthly: 2465 $
💲 Average Gain Weekly: 569 $
💲 Average Gain Day: 81 $
• 📆 Year: 2020: 🅰 Aggressive: 🚀 Leverage 1️⃣x
• 📆 Year: 2021: 🅰 Aggressive: 🚀 Leverage 1️⃣x
• 📆 Year: 2022: 🅰 Aggressive: 🚀 Leverage 1️⃣x
3️⃣0️⃣ : 🛠️ Roadmap
🛠️• 14/ 01 /2023 : Titan THEMIS Launch
🛠️• Updates January/2023 :
• 📚 Tutorials for Automation 🤖 already Available : ✔️
• ✔️ Discord
• ✔️ Wundertrading
• ✔️ Zignaly
• 📚 Tutorials for Automation 🤖 In Preparation : ⭕
• ⭕ Telegram
• ⭕ Twitter
• ⭕ 3comnas
• ⭕ Aleeert
• ⭕ Alertatron
• ⭕ Uniswap-v3
• ⭕ Copy-Trading
🛠️• Updates February/2023 :
• 📰 Launch of advertising material for Titan Affiliates 🛸
• 🛍️🎥🖼️📊 (Sales Page/VSL/Videos/Creative/Infographics)
🛠️• 28/05/2023 : Titan THEMIS update ▬ Version 2.7
🛠️• 28/05/2023 : BOT BOB release ▬ Version 1.0
• (Native Titan THEMIS Automation - Through BOT BOB, a bot for automation of signals, indicators and strategies of TradingView, of own code ▬ in validation.
• BOT BOB
Automation/Connection :
• API - For Centralized Brokers.
• Smart Contracts - Wallet Web - For Decentralized Brokers.
• This way users can automate any indicator or strategy of TradingView and Titan in a decentralized, secure and simplified way.
• Without having the need to use 'third party services' for automating TradingView indicators and strategies like the ones available above.
🛠️• 28/05/2023 : Release ▬ Titan Culture Guide 📝
3️⃣1️⃣ : 🧻 Notes ❕
🧻 • Note ❕ The "Demo 🐄" version, ❌does not have 'integrated automation', to automate the signals of this strategy and enjoy a fully automated system, you need to have access to the Pro version with '100% integrated automation' and all the tutorials for automation available. Become a Titan Pro 👽
🧻 • Note ❕ You will also need to be a "Pro User or higher on Tradingview", to be able to use the webhook feature available only for 'paid' profiles on the platform.
With the webhook feature it is possible to send the signals of this strategy to almost anywhere, in our case to centralized or decentralized brokerages, also to popular messaging services such as: Discord, Telegram or Twiter.
3️⃣2️⃣ : 🚨 Disclaimer ❕❗
🚨 • Disclaimer ❕❕ Past positive result and performance of a system does not guarantee its positive result and performance for the future!
🚨 • Disclaimer ❗❗❗ When using this strategy: Titan Investments is totally Exempt from any claim of liability for losses. The responsibility on the management of your funds is solely yours. This is a very high risk/volatility market! Understand your place in the market.
3️⃣3️⃣ : ♻️ ® No Repaint
This Strategy does not Repaint! This is a real strategy!
3️⃣4️⃣ : 🔒 Copyright ©️
Copyright © 2022-2023 All rights reserved, ® Titan Investimentos
3️⃣5️⃣ : 👏 Acknowledgments
I want to start this message in thanks to TradingView and all the Pinescript community for all the 'magic' created here, a unique ecosystem! rich and healthy, a fertile soil, a 'new world' of possibilities, for a complete deepening and improvement of our best personal skills.
I leave here my immense thanks to the whole community: Tradingview, Pinecoders, Wizards and Moderators.
I was not born Rich .
Thanks to TradingView and pinescript and all its transformation.
I could develop myself and the best of me and the best of my skills.
And consequently build wealth and patrimony.
Gratitude.
One more story for the infinite book !
If you were born poor you were born to be rich !
Raising🔼 the level and raising🔼 the ruler! 📏
My work is my 'debauchery'! Do better! 💐🌹
Soul of a first-timer! Creativity Exudes! 🦄
This is the manifestation of God's magic in me. This is the best of me. 🧙
You will copy me, I know. So you owe me. 💋
My mission here is to raise the consciousness and self-esteem of all Titans and Titanids! Welcome! 🧘 🏛️
The only way to accomplish great work is to do what you love ! Before I learned to program I was wasting my life!
Death is the best creation of life .
Now you are the new , but in the not so distant future you will gradually become the old . Here I stay forever!
Playing the game like an Athlete! 🖼️ Enjoy and Enjoy 🍷 🗿
In honor of: BOB ☆
1 name, 3 letters, 3 possibilities, and if read backwards it's the same thing, a palindrome. ☘
Gratitude to the oracles that have enabled me the 'luck' to get this far: Dal&Ni&Fer
3️⃣6️⃣ : 👮 House Rules : 📺 TradingView
House Rules : This publication and strategy follows all TradingView house guidelines and rules:
📺 TradingView House Rules: www.tradingview.com
📺 Script publication rules: www.tradingview.com
📺 Vendor requirements: www.tradingview.com
📺 Links/References rules: www.tradingview.com
3️⃣7️⃣ : 🏛️ Become a Titan Pro member 👽
🟩 Titan Pro 👽 🟩
3️⃣8️⃣ : 🏛️ Be a member Titan Aff 🛸
🟥 Titan Affiliate 🛸 🟥
Probability Oscillator (Zeiierman)█ Overview
The Probability Oscillator (Zeiierman) turns price dynamics into a regime-aware probability map of continuation vs. reversal. Rather than treating momentum as a single, fixed signal, it adapts its core estimator to current market conditions—favoring trend persistence in calm regimes and oscillation/reversion in volatile regimes.
You get a fast Probability line, a slower Signal line, dynamic OB/OS bounds, midline bias, color-coded trend probability, background regime cues, and Momentum Impulse dots that reveal concentrated bursts of directional intent. Beneath the surface, the Probability line functions as a sequential Bayesian filter — continuously updating a regime-conditioned prior (trend or volatility) with new market evidence. The resulting posterior odds are then expressed as a bounded oscillator for intuitive interpretation. In stable markets, the prior favors continuity; in volatile markets, it reweights toward mean reversion.
⚪ Why This One Is Unique
The Probability Oscillator operates within a self-adaptive probabilistic framework that continuously reshapes itself in response to the market’s evolving structure. Rather than relying on fixed formulas or static thresholds, it employs a context-aware Bayesian core that interprets flow dynamics through an adaptive regime model.
Its internal architecture blends state recognition, probability normalization, and dynamic envelope mapping, allowing it to adjust between conditions of directional stability and volatility-driven reversion fluidly. The result is an intelligent, self-adjusting probability field that remains stable in trends, reactive in consolidations, and contextually aware across all market states—delivering a refined sense of probabilistic direction without exposing raw computational structure.
█ Main Features
⚪ Probability Oscillator
At the core lies a probability-driven oscillator that continuously adapts its internal weighting to evolving market behavior. It translates incoming price evidence into a smooth probability curve that distinguishes between continuation and reversion phases, providing a refined view of conviction beneath price action.
The Probability Oscillator estimates the likelihood of trend continuation while dynamically adjusting to the surrounding volatility regime:
Probability Line (fast) – Captures short-term probability shifts, weighted by current market conditions — calm or volatile.
Signal Line (slow) – A smoothed probability filter that defines the prevailing bias and confirms directional persistence.
Momentum Impulse Dots – Small markers highlighting bursts of positive (green) or negative (red) momentum, indicating transitions in conviction strength.
The oscillator’s probabilistic framework automatically transitions between two self-adaptive modes:
Low-Volatility Mode – Prioritizes directional momentum and smooth trend continuity, ideal for trending markets.
High-Volatility Mode – Emphasizes oscillatory probability swings and reversals, optimized for range-bound or transitional conditions.
This dual-regime behavior allows the Probability Oscillator to remain stable in directional trends yet responsive in volatile ranges, producing a coherent probabilistic signal across any timeframe.
⚪ Trend Probability Coloring
The Trend Probability Coloring system transforms the Signal Line into a live confidence gauge. Its adaptive hue reflects the underlying probabilistic bias — green for sustained bullish pressure, red for bearish control, and yellow during transitional uncertainty. Behind the scenes, it applies curvature-sensitive weighting and probabilistic smoothing to display a visually coherent measure of directional conviction.
⚪ Impulse Dots
Impulse Dots identify moments of concentrated momentum expansion — short bursts of probabilistic acceleration that often precede shifts in structure. Each impulse represents a localized jump in directional confidence, isolating meaningful change-points from background noise. The result is a precise visualization of where probability and price begin to align, revealing early cues of strength, exhaustion, or imminent rotation.
█ How to Use
⚪ Trend Following
The Signal Line acts as the long-term probabilistic trend gauge, revealing when the market is building or losing directional conviction. Its slope and color communicate both bias and transition strength:
Green → bullish probability bias (trend continuation likely).
Red → bearish probability bias (downside continuation likely).
Yellow → transitional or indecisive phase (potential regime shift).
Use the Signal Line to confirm directional alignment:
A transition from red → yellow → green signals that the market is turning bullish and probability is shifting toward continuation on the upside.
A transition from green → yellow → red signals that bullish conviction is fading and bearish control is emerging.
⚪ Overbought & Oversold
The Probability Oscillator can also be used to identify overbought and oversold conditions by observing when the Probability Line moves above its upper bound or below its lower bound. These events often signal potential market slowdowns, pullbacks, or even broader reversals depending on context and regime.
The OB/OS levels automatically adapt to the prevailing market mode:
Trend Mode (~70/30) – Optimized for riding trends and timing pullbacks within directional continuations.
Volatility Mode (~80/20) – Tailored for fading extremes and capturing fast mean-reversion moves during consolidation phases.
Signals: Reclaims from oversold zones within a bullish bias, or rejections from overbought zones in a bearish bias, represent high-probability inflection points — especially when confirmed by Impulse Dots or regime-aligned Signal Line color transitions.
⚪ Using Volatility Modes to Choose Strategy
The Probability Oscillator automatically adapts its behavior to the active volatility regime, enabling traders to align their approach with the current market state. One of the most effective ways to use the tool is to select a trading strategy that aligns with the prevailing market mode.
Trend Mode (purple fill) – Represents low-volatility, directional environments where markets move smoothly and sustain momentum over time. In these conditions, a trend-following approach is most effective. Focus on the broader direction, participate on Probability-over-Signal crossups above 50, and trail positions as long as the Signal Line remains green. These calm phases often persist before volatility expansion, making them ideal for riding steady continuation waves rather than reacting to short-term fluctuations.
Volatility Mode (blue switch bar) – Activates in high-volatility conditions, signaling increased market agitation and sharper price swings. In this regime, trading becomes more tactical. Mean-reversion and scalping strategies perform best—fade OB/OS extremes, use midline reclaims for timing, or trade Impulse confirmations to capture breakout accelerations and short-term momentum surges.
⚪ Impulse
The Momentum Impulses highlight periods when the market experiences sharp bursts of directional momentum, marking transitions in conviction strength and energy expansion.
Green top dots → Indicate strong bullish impulses, often signaling the onset or acceleration of upward momentum.
Red bottom dots → Indicate strong bearish impulses, highlighting pressure buildup or downside continuation.
These impulses are particularly useful in two contexts:
During ranging markets , they help confirm overbought and oversold conditions, signaling when reversals or exhaustion points are highly probable.
During regime transitions , they validate breakout strength, confirming that new directional phases are supported by genuine momentum rather than noise.
In essence, Impulse Dots visualize the heartbeat of market conviction—pinpointing where momentum surges align with probabilistic bias, whether to confirm a breakout or warn of exhaustion in choppy conditions.
█ How It Works
⚪ Regime Switch Engine
At the foundation lies a Bayesian regime adaptation process that treats volatility as evolving market evidence. The system continuously updates a prior belief about whether the market favors directional persistence or oscillatory reversion. In calm states, it maintains a continuity-biased belief structure that favors smoother probability propagation.
Calculation: Employs a volatility-normalized Bayesian comparator, generating a posterior distribution over regime likelihoods. This ensures the oscillator remains statistically invariant to scale and consistent across instruments and timeframes.
⚪ Trend Probability Coloring (Conviction Layer)
The Trend Probability Coloring system visualizes Bayesian posterior confidence in real time. It continuously updates the Signal Line’s color as new evidence shifts the model’s belief between bullish, neutral, and bearish states.
When the posterior probability leans strongly upward, the line turns green; as uncertainty grows, it fades to yellow; and when conviction turns negative, it transitions to red. Each color change represents a probabilistic reweighting — the model’s evolving assessment of directional dominance.
Calculation: Applies posterior-weighted smoothing and curvature-based confidence mapping to translate Bayesian belief strength into a fluid visual gradient.
⚪ Momentum Impulse Engine
The Momentum Impulse Engine detects sudden bursts in probabilistic conviction — moments when the Bayesian posterior sharply reweights toward one directional outcome. These impulses represent statistically significant shifts in belief, where new evidence rapidly alters the model’s assessment of market direction.
Green impulses highlight surges in bullish probability; red impulses mark spikes in bearish conviction. Each impulse reflects a brief phase of directional dominance, revealing where probability momentum begins to accelerate or exhaust.
Calculation: Employs nonlinear Bayesian change detection and extreme-value gating to isolate abrupt posterior inflections.
-----------------
Disclaimer
The content provided in my scripts, indicators, ideas, algorithms, and systems is for educational and informational purposes only. It does not constitute financial advice, investment recommendations, or a solicitation to buy or sell any financial instruments. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
Skrip berbayar
Daily Manual KILLZONESThis indicator is to be used with "KILLSTATS", our indicator allowing to backtest on hundreds of days at which time, and which day the top/low of the day and week is formed.
"Manual Killzone" allows to define our statistical killzones by day of the week manually: you define your own rules according to your interpretation of our Killstats indicator.
It integrates a daily price action filter according to the ICT concept:
It will only display bullish probabilities (green) defined if and only if we are in discount and out of the daily range 25/75%.
Same for bearish probabilities (red)
The blue color is to be applied in case of reversal with high contradictory probability (Example: to be used for Tuesday from 2pm to 3pm, if Tuesday is a day with high probability to form a top, but 2pm/15pm is the time with high probability to form a bottom AND a top. Indecision => blue)
WARNING : Calculated according to Etc/UTC time : put "0" in the Timezone parameter of killstats.
It is necessary to use the replay mode regularly during the backtesting to update the data!
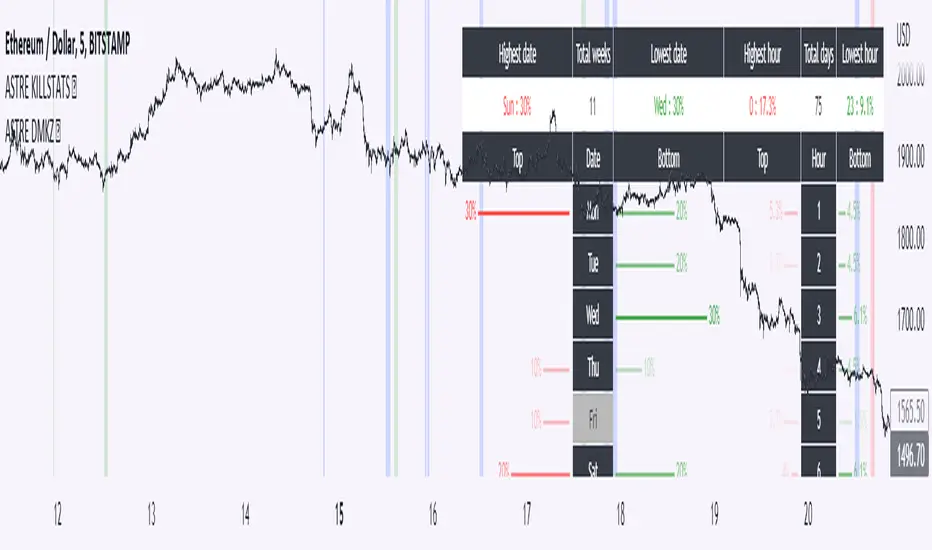
KillstatsBacktest and identify at what times/days the high/low were formed. The periods are shown on the graph along with detailed statistics.
Exemple with "days : 600" and "13h : top 12%" : we understand that over 600 days, in 12% of the cases we have formed the top of the day at 13h.
up to 1000+ days studied to find favorable reversal time slots: killstats! The data presented can sometimes be... surprising.
Increasing/decreasing the timeframe on chart = increase/decrease the studied period.
A period of 1000 days ( UT : h1) allows to have solid but not exact statistics.
A period of 30 days allows to have current statistics but too little sample to know if the data is relevant.
I recommend looking for intersections of killstats over several periods: If over 1000 days AND 30 days, 3pm was a time with a high probability of forming a top, it is interesting to look for short positions between 3pm and 4pm.
The data is displayed in the form of a diagram whose visual allows to identify effective time slots.
Caution. Timeframe: h1 maximum for the study of the day's high/low to be correct - and daily maximum for the study of the week's high/low.
Caution2. Match the timezone with the input (by default set to GMT+1). So if you are at GMT+2, you must put "2" in timezone.
I recommend using this as part of an aggressive high frequency scalping strategy to make the most of your trading session - with the aim of quickly moving to TP1/BE and leaving your winning position open.